
Twitter has officially released its new API, aka version 2. It comes with great premises. Introduced with an astonishing video and proudly promoted as a rebuild "from the ground up to better support developers", including business, academic researchers, students, and makers.
I was really excited to see the new opportunities that it brings. While still in an early access phase, I must say that I'm a bit disappointed so far. Let's see why.
The great.
The developer portal, including the developer's dashboard, has been fully rebranded. Information is a bit easier to find, more structured. There are many more quickstarts which is really great for a newcomer.
One thing that I've immediately liked is the improved way of filtering data. A bit like in GraphQL, you can ask Twitter which properties you are interested in.
For example, when asking for tweets, Twitter sends by default the id and text (content) of the tweet. If you are interested in receiving specific metrics, like the number of retweets, you can ask for that by adding a new parameter.
This will look like the following:
?tweet.fields=created_at,public_metrics
It reduces the payload to just what you want - which is always great. Though I'd love to be able to have more granularity. For example, ask for retweets only, and not having all public_metrics. Also, the default fields are mandatory. There's no way to overrides that.
The meh.
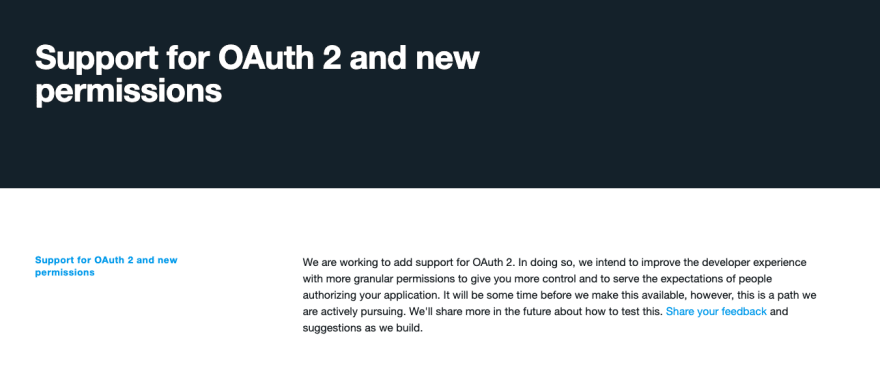
The API still uses OAuth 1.0a for the authentication part. That's probably the first thing that "shocked" me. Most APIs have migrated to OAuth 2.0 for years. It's really surprising that Twitter didn't take the leap when releasing this new version.
OAuth 2.0 has introduced the notion of scopes, which is very familiar today. By keeping OAuth 1.0a, Twitter will not be able to provide granularity to the developer on the user's data.
In other words, by allowing an application, it will always have full access to your data. Which is not something people want anymore. Twitter says it's on the roadmap though.
Also, Auth 1.0a is far more difficult to use from a developer's perspective. It requires signing each request for example. But, I'm using a tool called Pizzly (that I've participated to build) to help with that.
More broadly, I haven't seen many innovations with that new API. It's mostly a REST API, with some interesting concepts (e.g. the ”fields” parameters). But some other APIs already have similar concepts in place (Google APIs has used the field parameters for years).
The ugly.
The API quotas are still very low. An application can't request more than 500,000 tweets per month. I've estimated that when browsing my feed on Twitter, I'm looking at about 50 tweets per session. Per month, that's 50 * 30 = 1500 tweets.
Building an application that just renders a user's feed would stop working at just a few hundred active users. It's really not that much.
I also have this feeling that this new API isn't targetting small developers. For instance, when starting to look at the new Twitter API, I wanted to build a graph of my Twitter timeline to make it looks a bit like GitHub Contributions Graph.

There's no such endpoint that lets you do that in the new Twitter API. No endpoint to retrieve tweets of an authenticated user. And the public tweets can be retrieved in the last 7 days only. It's a bit of a shame that Twitter keeps its user's data for itself.
Another example that strengthens this feeling, one of the 6 available endpoints is the sampled stream which delivers "a roughly 1% random sample of publicly available Tweets in real-time". That's kind of awesome! But the amount of data that you need to manage is massive...
Conclusion
The API is still in an Early Access phase and we can see it.
Not all endpoints are available. As of writing, only 6 endpoints are. And for example, you can't post a new tweet with the version 2; neither manage DMs. So it's really early to get the most of this new API.
Also, tons of great features are still on the roadmap. But I have the overall feeling that the new Twitter API is mostly targetting big players (established companies, academic researchers, etc.).


















