
I wanted to share the story about our battle with tech debt and the challenge of completely rebuilding Browserless. It feels in the spirit of open source to share the process as well as the product.
So, here it goes…
Some context about the product and the challenge
Browserless.io is an eight person, bootstrapped startup. Things are all going well, we’ve got thousands of users and last year we broke $1M ARR.
The core product is managed, cloud hosted browsers. We run thousands at a time using AWS and DigitalOcean, for people to use with Puppeteer and Playwright scripts. Our container is also available to self deploy under an open-source license.
Hosting headless browsers is notoriously difficult. They aren’t really designed for cloud deployments in the same way that a databse is.
Running Browserless has involved challenges such as writing our own load balancers from scratch using NGINX and Lua, while supporting multiple libraries. Any and all rewrites are tricky and need to be approached with caution, which is where our story really starts.
V1 was getting pretty creaky
Our founder started building Browserless back in 2015. That means V1 was eight years old and had some key headaches.
The design patterns we used are now quite legacy and are prone to memory leaks. For example, take a look at the puppeteer-provider on our V1 branch. It doesn’t use classes well, calls out to other internal private functions, and is a pain to debug where problems might occur. Its “statefulness” is a somewhat decided anti-pattern, and a clear indicator that a reworking might be necessary.
There’s also chrome-helper that “helps” manage chrome. It had similar issues to the puppeteer-provider in that it’s a stateful piece of code that is very difficult to pinpoint issues on. In general, cleanup happened all over the place when things go wrong, and V1 had to twist and contort the “queue” library in order to implement things like cleanup actions.
To be quite frank it had just become too unwieldy.
It was also very strongly tied to Chrome. We wanted to add support for Firefox and Webkit , but V1 heavily relied on the underlying browser to be Chrome for interactions which made this extremely difficult. Assumptions can build all sorts of corners you can code yourself into! Not only that, all of our subdomains, docker tags, and more also relied on this fact.
The developer experience for our open source image was also in need of improvement.
V1 had partial support for implementing your own behaviors via hooks, so users could extend the docker image and add their own functionality. It was very clunky to work with and was very limited in terms of what it could do.
Since we “dogfood” these open source images internally to build our paid product, it was also impacting our small dev team. Building and launching new features was a struggle due to our own technical debt, so a decision was needed.
Accepting it’s time to pay our (tech) debts
Fixing the issues above required a complete overhaul of our core product and underlying platform. It would take months, during which we wouldn’t be shipping many new features. Even launching V2 was mostly going to benefit ourselves at first, with the difference to our paying users only coming once we built new features on top of it.
Thankfully bootstrapping meant that our MRR was steady and covered all of our costs, so there wasn’t a VC funded runway to race against. But, it would also make it hard to increase revenue during that time*.
As you can imagine, we discussed this with our advisers multiple times and chewed the decision over for months before finally biting the bullet.
*Side note: at this point we also didn’t have a dedicated marketer and were DIY-ing our promo, but that’s a story for another time.
Putting together a wishlist
As well as the key factors I’ve already mentioned, we had a pretty lengthy wishlist for V2:
| v1 | v2 |
|---|---|
| All images used Chrome or Chromium | Wanted to have browser-specific images as well as one for all the browsers (Chrome, Firefox and Webkit) |
| Docker Hub’s UI and admin portals have been frustrating, plus users disliked that Docker Hub required a paid account to pull more than a certain amount a month | Moving to a new docker container repository needed to be possible, instead of being locked in. |
| We had some legacy sandboxes for securing certain APIs, but they were now deprecated | $We wanted to shift to more secure methods and stop relying on vulnerable modules |
| We had to rely on an HTTP framework | A better dev ex was planned, with auto-generated documented and runtime validation for our APIs that we could implement ourselves |
| Like many teams, we were dependent on the npm and javascript ecosystem, using hundreds of packages that sometimes went extinct. | The aim was to use as few modules as possible to ensure stability and security, while not having to rebuild “the hard parts” |
| More and more packages are moving to ECMAScript modules, which we couldn’t handle well since V1 is CommonJS-based. | ECMAScript modules are a lot easier “from the ground up.” |
| Used various frameworks and routing. | Custom libraries and routing. NodeJS HTTP service, light and flexible to support both WebSocket and HTTP routing. |
| TypeScript but no NPM package or SDK for extensions. | TypeScript with an npm package, for easily building new features |
There was no way to feed all of these things into Version 1 in an elegant way, it could only be done if we stripped the whole thing back to basics.
We also had a few things we wanted to get rid of as well. As our first major version change, this presented a good opportunity to do so plus write a platform of sorts to tackle things we wanted. You might say it was a great confluence of events to rip this bandaid off.
The other big decision was to drop support for Selenium. Even though it’s still a popular library, attention is shifting more and more towards Playwright and Puppeteer. Supporting Selenium had far too high a technical cost and complexity, and added yet-another-version to align all things with, so we bit the bullet and dropped it for V2.
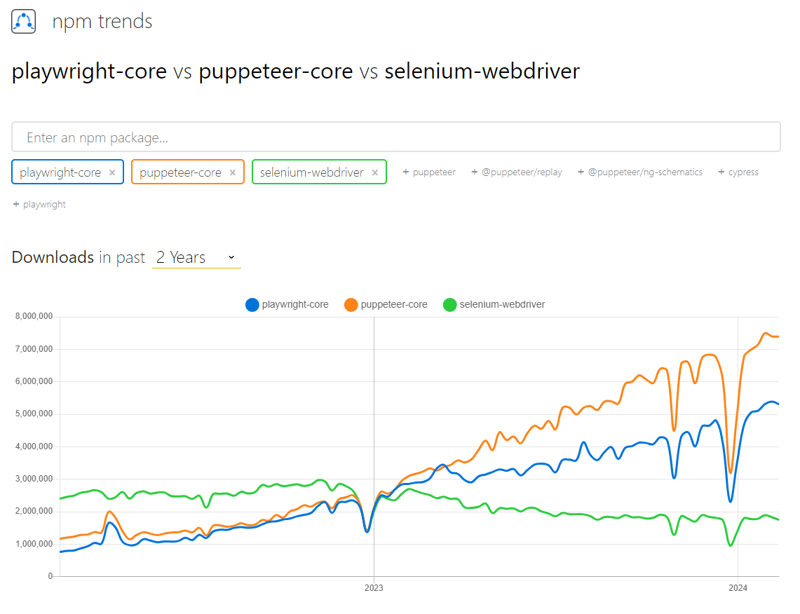 Why we're dropping support for Selenium
Why we're dropping support for Selenium
Plan of attack
We put together a plan for the rebuild, the general stages were:
- Figure out what we didn’t want to build.
- How to handle potentially several browsers per container.
- Make it automatic: documentation generation, OpenAPI schemas, and make it machine readable.
- Make it accessible: deploy to Github Container registry with easy to understand tags and formatting.
Unsurprisingly, we actually used a lot of the same packages from V1 in support of V2. TypeScript, queue, puppeteer/playwright, and of course prettier and ESLint.
We desperately wanted to use an API framework, but none really seemed to meet our needs of TypeScript-first, WebSocket routing, and some kind of “dependency” characteristics. As much as it sucked, we needed to write our own. This wasn’t as easy as we’d hoped, and with every great plan there comes an even greater punch to the face.
The best laid plans of mice and devs
I believe it was Mike Tyson who said
Everyone has a plan until they get punched in the repo.

Yup, things went wrong. Here’s a highlight of some favorite headaches we came across:
- Having a TypeScript-first approach meant we had to build a bunch of tooling. I won’t go into details as you can freely look at it in our scripts folder here to see for yourselves: https://github.com/browserless/browserless/tree/main/scripts.
- Handling WebSocket routes and HTTP routes is tricky and easy to get wrong. What happens when one dies halfway through the request? What if they need a browser to run? What if they don’t? We had to account for a whole bunch of scenarios.
- How do we make the system malleable to routes sometimes being there or not? We wanted custom docker images with only the functionality they needed. Building a lazy-loading route system was difficult to get working 100%.
- Figuring out our priorities for routing was tricky, but worth the several-times-over redesigns. What do developers care about? Headers, Methods, Accepts, Content-types and more can play wildly into how a request is handled.
- Design patterns we’ve seen across other libraries worked great for your cookie-cutter REST APIs, but tend to leave a lot to be desired when working with things like a web-browser.
It wasn’t all nightmares though. Once we got things set right, not only did it “feel” good, but writing new API routes and functionality happened much much faster.
Surprising benefits we encountered
Having a class-based routing system, with TypeScript at the center, felt natural and the way forward.
We now define routes in browserless as being either WebSocket, HTTP or both + a browser. When having a mostly-declarative syntax for routes, and a strong class-based system, other things became a lot easier.
For example, since we know ahead of time what methods, paths, and request/response formats are we can much more easily generate a live documentation site that details all these items without having to manually create one. This includes query-parameters, response objects or types, and POST body requirements. This value is further shown by the fact that all of these features are also propagated down to the SDK level as well.
The most surprising thing, however, is that the way we generate our runtime validation passes through meta-data from playwright and puppeteer all the way to the documentation site. That means if there’s a helpful comment, type info, or description in these libraries it’ll surface in documentation. Any updates there are automatically carried over to our platform and passed through.
Hitting our launch deadline
I’m especially proud (and even a bit surprised) that we managed to hit our target launch date 12 months after we started. With a long history of use-cases and complexity, recreating the platform was no easy task.
We were sponsoring a newsletter on Dec 7th last year, so the aim was to ship v2 before then. We managed to ship and make v2 available on GitHub’s container image registry.
It’s even mostly compatible with v1, so we heard from our self-hosted customers that the transition was fairly simple.
Final thoughts
It was a huge undertaking and I’m extremely proud of what we’ve achieved. Overall it took around 400 days of developer time and the payoff is already looking huge.
The new modular SDK means we’re rapidly developing a range of new features that are in the pipelines, such as enterprise level account management and advanced browser workflows.


















