
Hi there! Every time I need to do batch processing using Unix tools, I am amazed by the simplicity and robustness of Unix commands. But how do they compare with other batch processing tools? Let's understand the pros and cons of batch processing using Unix commands.
Let's suppose you have a file with the network traffic flows. Your goal is to calculate the most common source and destination IP-port combinations. How would you do that?
We can download from Kaggle a dataset with network traffic flows. Let's start by solving the problem using the Pandas library, in Python, probably the most used library for quick data analysis. There are better ways to solve the problem, but for the purpose of this post, let's use a naive approach.
Simple, right? We load all data from the file, group by source and destination IP and port, count the repeated combinations, sort values by the count, take the top 20 results, and store them in a file. Try it yourself!
Now let's solve it using only Unix commands.
We read the file (except the header), filter only the columns needed (Source IP, Source Port, Destination IP, and Destination Port), sort by that combination, count the repeated combinations, sort again by count, take the first 20 results and store it in a file. Very similar to the Python approach, maybe a little less readable if you're not used to Unix, but still easy to understand. Let's compare both approaches.
It seems that the Python approach is faster than the Unix commands! Interesting, but why is that? Before diving into the question, let's tweak our input.Let's replicate our dataset by a factor of 8 and rerun the scripts. You can easily guess that it should take more time to run, and you would be right. But another things happens…
Wow, it seems that the python script was terminated by the kernel, but the Unix commands ran successfully. Let's take a closer look into what happenned.
 RAM memory while running Python script. RAM memory went up to 100% before crashing.
RAM memory while running Python script. RAM memory went up to 100% before crashing.
 RAM memory while running Unix commands. RAM memory stayed below 20%.
RAM memory while running Unix commands. RAM memory stayed below 20%.
Looking at the RAM memory, it seems that with the Python script, the memory was insufficient to process the entire dataset. Comparing with the Unix commands on the other hand, there is no impact on RAM memory whatsoever.
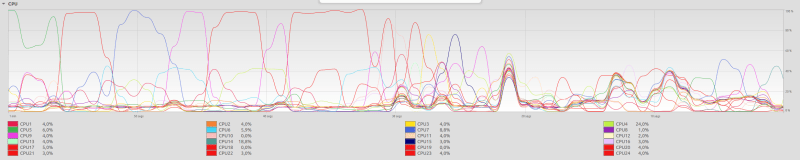 CPU usage while running Python script. There was almost always one CPU close to 100% usage before terminating the script.
CPU usage while running Python script. There was almost always one CPU close to 100% usage before terminating the script.
 CPU usage while running Unix commands. CPU usage of every CPU never surpassed 70%.
CPU usage while running Unix commands. CPU usage of every CPU never surpassed 70%.
Besides, it looks as the Python script always uses one CPU core to 100%, while the Unix commands distribute the load across the available CPUs. How does this happens? Is it automatic?
What happens is that Pandas processes the entire dataset in-memory. If the dataset is larger than the memory size, the script will crash. Another downside of Pandas is that it only uses a single CPU core, instead of taking advantage of all CPU cores. For these reasons, Pandas is better suited for smaller datasets, where it may be faster than Unix commands due to all in-memory processing. However, for datasets larger than the available RAM memory, Pandas may not be the best approach.
On the other hand, Unix commands are much better suited for larger datasets. The sort utility automatically handles larger-than-memory datasets, by splitting the data into batches, which are sorted in-memory and then stored in temporary files. Only then those temporary files are merged together. In this way, you never run out of RAM memory. Besides, the sort utility also parallelizes sorting across multiple CPU cores, making the bottleneck the rate at which disk files are read.
 Temporary files created by sort command in my /tmp folder.
Temporary files created by sort command in my /tmp folder.
This is awesome, right? This also resembles another programming model…
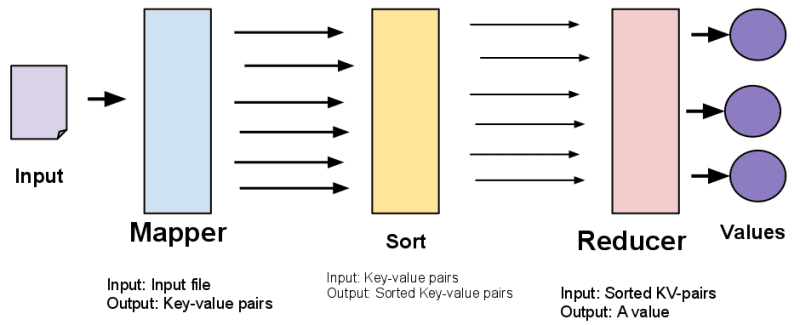 MapReduce Pipeline. In Berkeley CS61A Lab 13.
MapReduce Pipeline. In Berkeley CS61A Lab 13.
Have you heard about MapReduce? It's a programming model for batch processing in distributed systems, presented by Google engineers in 2004. Its goal is to distribute the processing of large datasets between servers, by separating all processing steps into two tasks: mappers, which perform mainly mapping, filtering and sorting, and reducers, which perform an aggregation operation. For the exercise above, each mapper would sort a batch of the dataset, and send the sorted batch to another task, which would perform the merge.
We can see that MapReduce took the Unix approach to deal with large datasets and applied it to distributed computation. It's even more amazing to see the robustness of Unix commands taking into account that MapReduce was presented 35 years later than the creation of Unix, which was created in 1969.
Are there more breakthrough ideas in Unix? Let's take a look at its philosophy.
Make each program do one thing well
The core of the Unix philosophy is to separate the logic of every processing step. This means that instead of having one monolithic kernel with lots of features, Unix aims for a small kernel with lots of utilities. cat, sort, ls or awk are not in the Unix kernel, but are separate tools that help doing the job needed. This approach is one of the reasons why Unix is still relevant today: even though the world has changed and the technologies have evolved, those simple programs are still useful everyday: users still need to sort content, list their directories, and read text files.
In today's distributed and complex systems, this principle is still applied today, particularly in the microsservices pattern. The goal of the microsservices is, instead of having a single service with lots of features, to have multiple services, each focused in doing one job well. This has many operational benefits, mainly easier code maintenance, better monitoring and better scalability.
Expect the output of every program to become the input to another
In Unix every program has a standard way of communicating between themselves. The pipes guarantee that you can easily take the output of a program and use it as input to another, acting as an uniform programming interface. This has the obvious advantage that it's easy to use Unix commands in sequence - there is no need to pre-process or post-process the data. This easiness of composability of simple programs makes Unix a powerful tool.
It is interesting to think that most of today's systems it is not as composable as Unix in 1969. Many time is still spent just trying to solve integration between systems. However, the idea of the output of a service to become the input of another is now widely adopted through the event-driven architecture. Many large enterprises find it the best way to communicate between services - each service consumes from the streams that is interested in, and publishes its output to another stream. If another service is interested in the data, it can subscribe to the output stream. Again, this is very similar to the piping design in Unix: each service does its own job and publishes the result to the output, unaware of any other service that might consume that data. The main difference is that while Unix interface uses text files to communicate between processes, services mainly use message brokers (for example, Apache Kafka or RabbitMQ).
Design and build software to be tried early, ideally within weeks
In 1969, Unix developers had the philosophy that software had to be tried early. Curiously, in the 70's, waterfall was born and took the software world by storm. Long were the days were software was tested and shipped early. During that time, software was only tested after all design and coding was done.
Only in 2001, when the Agile manifesto was written, that large software enterprises started following again the Unix principles and designing and building software early (some of them still use the waterfall method, with little success). It took us 30 years to understand that the waterfall methodology was not very well suited for most software development, and that the Unix philosophy was right all along!
Use tools in preference to unskilled help to lighten a programming task
The last principle is probably the most difficult to understand. When having a problem that can be solved manually, Unix developers would rather build tools to solve it than solve it themselves manually. This principle gave birth to many tools now used in day-to-day life. If those problems were recurrent, then there was already a tool available to solve them.
Many software tools were created as side-projects to solve a specific problem and ended up being used in a much larger scale. Apache Kafka was initially created in Linkedin to ingest lots of data with low-latency into a lambda architecture (there is an old but excelent post about it). GraphQL was initially created in Facebook to solve the problem of overfetching and underfetching in Facebook mobile app. Cassandra was initially developed in Facebook, to power the inbox search feature. The bottom line is that the problem we are trying to solve may as well appear in many other scenarios. If we are able to solve it once, we will be able to solve it easily many more times with the same software.
Although it was written more than half a century ago, the Unix philosophy is still a great piece of advice for every software developer. The tools created are still useful, and better than many of the today's software. It is not common for a piece of software to remain useful and heavily used around the world more than 50 years after its creation, with its main features remaining the same.
Although sometimes it's forgotten, when doing data processing with large datasets in a single machine, Unix may be your best tool.
Thanks for reading!
ps: There is a way to run the Python script above and use much less memory. Have you tried loading only the columns you need to memory? 😃
also, you can read an interesting rant about Python, R and Unix here.


















