
What is Machine Learning & How Does it Work?
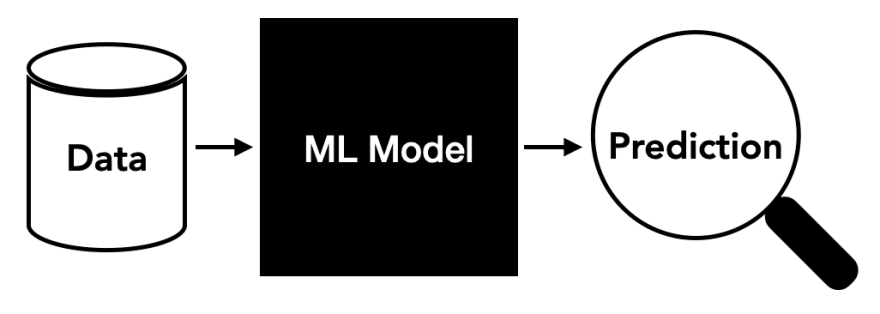
Machine Learning is a branch of Artificial Intelligence that enables computers to learn from data without being explicitly programmed. It uses algorithms to analyze large amounts of data, identify patterns and trends, and then make predictions based on those findings.
Machine Learning algorithms can be divided into two main categories:
- Supervised learning algorithms are used when the data has labeled outputs and the algorithm can use this labeled output to make predictions about unlabeled data.
- Unsupervised learning algorithms are used when the data has no labeled outputs and the algorithm can use this unlabeled data to discover hidden patterns in the data. By understanding these two types of machine learning algorithms, we can better understand how machines are able to learn from data and make predictions.
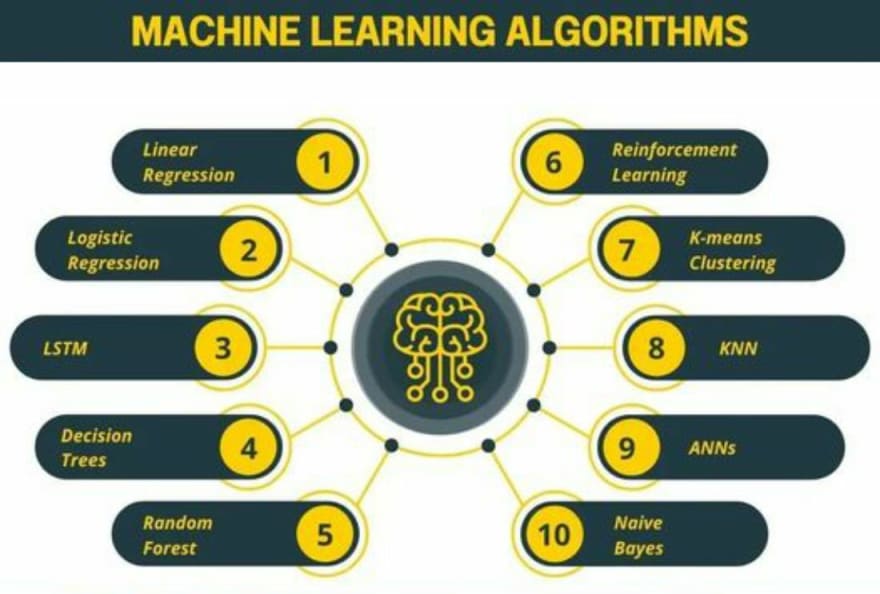
Exploring the Different Types of ML Algorithms & Their Use Cases
Machine Learning (ML) algorithms are becoming increasingly important in the world of data science. They enable us to make predictions, classify data, and identify patterns from large datasets. ML algorithms can be used for a variety of tasks, from predicting stock prices to recognizing objects in images.
In this article, we will explore the different types of ML algorithms and their use cases.
We will look at linear regression algorithm, logistic regression algorithm, LSTM, Decision Trees, Random Forest, Reinforcement Learning, K-means Klustering, KNN, ANNs and Naive Bayes.
By understanding these different types of ML algorithms and their use cases, we can better understand how they can be used to solve real-world problems.
Linear regression algorithm
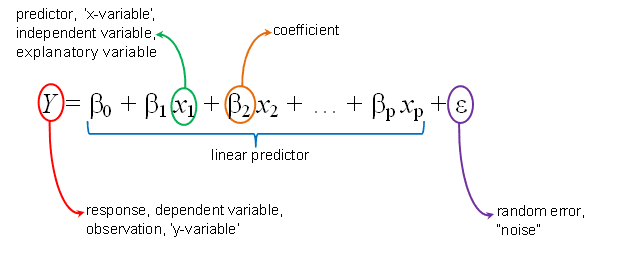
is a machine learning algorithm used to predict a continuous value. Given a set of input data, it tries to find the best line of fit that describes the data. The equation of this line is known as the "regression line." The best fit is determined by minimizing the sum of the squares of the differences between the predicted values and the actual values. The predicted values are calculated using the following equation:
y = mx + b
Where y is the predicted output, m is the slope of the line, x is the input data, and b is the y-intercept (the point where the line crosses the y-axis).
Linear regression can be used to make predictions about a continuous value, such as the price of a house based on its size, the demand for a product based on its price, and so on. It is a simple and widely used technique for predicting continuous values, and it is often used as a baseline model for more complex algorithms. In this article you can read more about it.
 source
source
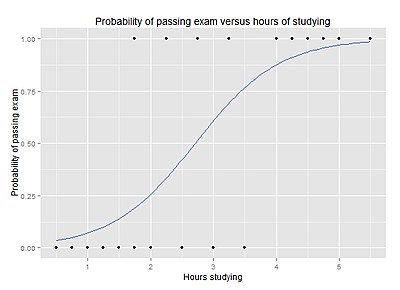
Logistic regression
is a supervised learning algorithm that is used for classification tasks. It is a generalized linear model that uses a logistic function to model a binary dependent variable, which can take on values of 0 or 1. The logistic function is a sigmoid curve that maps any real-valued number to a value between 0 and 1.
The goal of logistic regression is to find the best coefficients (weights) for the features in the data, such that the logistic function can be used to predict the probability that an example belongs to a certain class. The predicted probability is then thresholded to make a prediction about the class.
Logistic regression can be trained using maximum likelihood estimation, by minimizing the cross-entropy loss between the predicted probabilities and the true labels. It is a popular algorithm for binary classification problems and is also often used as a baseline for more complex models.
Here you can see an example of a logistic regression model.

Long Short-Term Memory (LSTM)
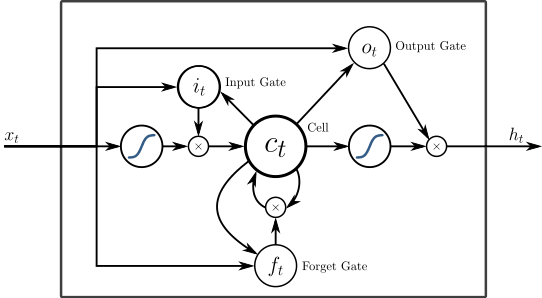
is a type of recurrent neural network (RNN) that is able to capture long-term dependencies in sequence data. RNNs process input sequences one element at a time, maintaining an internal hidden state that captures some information about the past elements in the sequence. LSTMs are a variant of RNNs that are designed to remember information for longer periods of time and to prevent the vanishing gradient problem, which is the inability of standard RNNs to retain long-term dependencies due to the exponential decay of gradients as they are backpropagated through many time steps.
LSTMs have three gates: an input gate, an output gate, and a forget gate. The input gate controls what information from the current input will be passed to the cell state. The output gate controls what information from the cell state will be output. The forget gate controls what information from the previous cell state will be discarded. These gates are implemented using sigmoid functions and elementwise multiplication. The cell state is a weighted combination of the previous cell state and the current input, where the weights are learned during training.
LSTMs have been successful in a variety of natural language processing tasks, such as language translation and text generation, as well as in other areas such as music generation and financial forecasting.
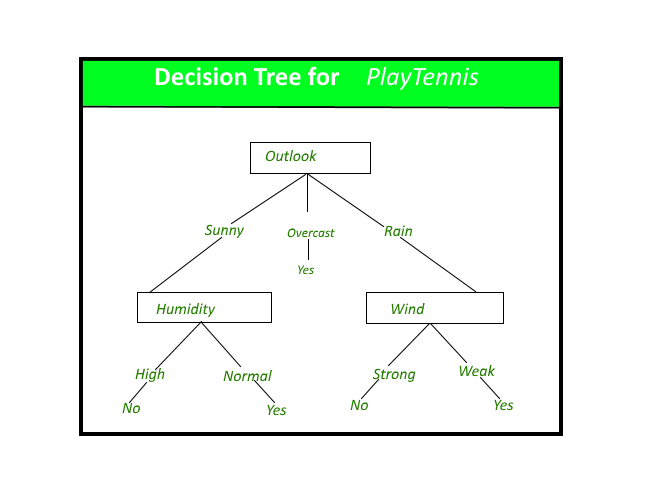
Decision trees
are a type of supervised learning algorithm that can be used for classification or regression tasks. They work by constructing a tree-like model of decisions and their possible consequences, with an internal node representing a decision, branches representing the possible outcomes of a decision, and leaf nodes representing the final outcome.
To build a decision tree, the algorithm starts at the root node and splits the data into subsets based on the most important feature, which is determined using a metric such as information gain or Gini impurity. The process is then repeated at each child node, until the leaf nodes are reached, which contain a class label or a predicted value.
Decision trees are easy to understand and interpret, and they can handle large amounts of data, but they are prone to overfitting and can be unstable, as small changes in the data can lead to large changes in the tree structure. To mitigate these issues, techniques such as pruning, boosting, and bagging can be used.
Here you can find a detailed article with examples about Decision trees ML Model.
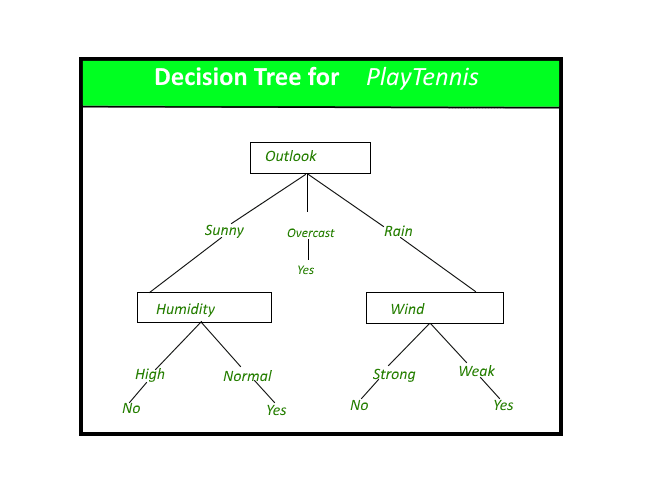 source
source
Random forests
are an ensemble learning method for classification, regression and other tasks, that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random forests correct for decision trees' habit of overfitting to their training set.
Random forests are a popular and effective method for a variety of tasks, including recommendation systems and image classification. They are also used for feature selection, as the importance of a feature can be computed as the averaged importance of the feature over all trees in the forest.
The main advantages of random forests are that they are easy to use, can handle high-dimensional data, and are resistant to overfitting. They are also relatively fast to train and to make predictions with. However, they can be less interpretable than decision trees, as it can be difficult to understand why a particular prediction was made.
Here you can find a beautiful example of Random forest.
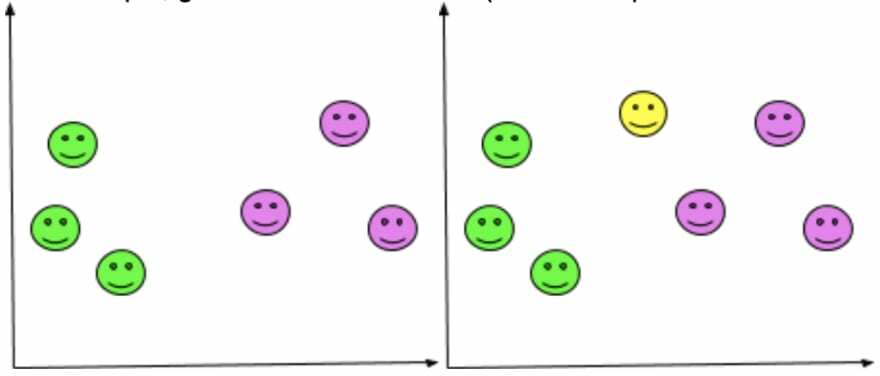
Reinforcement learning
is a type of machine learning in which an agent learns by interacting with its environment and receiving feedback in the form of rewards or penalties. The goal of the agent is to learn a policy that maximizes the cumulative reward over time.
In reinforcement learning, an agent observes its environment and takes actions that affect the state of the environment. The agent receives a reward or penalty based on the action it took and the resulting state of the environment. The agent's goal is to learn a policy that maximizes the cumulative reward it receives over time.
Reinforcement learning can be applied to a wide range of tasks, such as controlling a robot or playing a game. It has been successful in a variety of applications, including robotics, video games, and autonomous vehicles. One of the key challenges in reinforcement learning is balancing exploration, in which the agent tries out new actions to gather more information, with exploitation, in which the agent leverages its current knowledge to maximize reward.
Here is a beautiful Reinforcement learning use case.
K-means clustering
is an unsupervised learning algorithm that is used to partition a dataset into K distinct, non-overlapping clusters. The goal of the algorithm is to minimize the sum of squared distances between each data point and the mean of its cluster.
The algorithm begins by randomly selecting K initial centroids, one for each cluster. It then assigns each data point to the nearest centroid, based on the Euclidean distance between the point and the centroid. Once all the data points have been assigned to a cluster, the centroids are updated to the mean of the points in their respective clusters. The process of assigning points to clusters and updating the centroids is repeated until the centroids converge, or until a maximum number of iterations is reached.
K-means clustering is a popular and simple method for partitioning a dataset into clusters. It is fast and efficient, but it is sensitive to the initial placement of the centroids and can sometimes produce suboptimal results. Other clustering algorithms, such as DBSCAN and Gaussian mixture models, can be more robust but may be more computationally expensive.
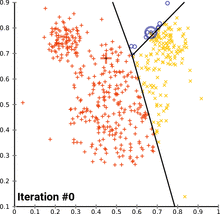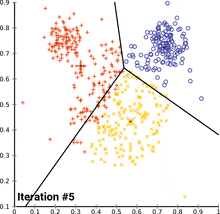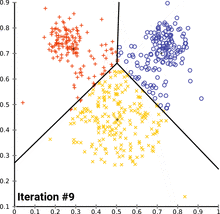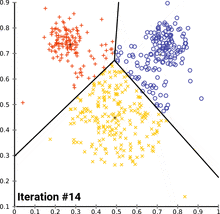
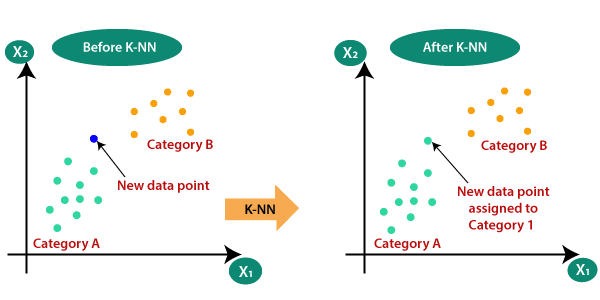
KNN (K Nearest Neighbors)
is a machine learning algorithm used for classification and regression tasks. It is based on the concept of similarity, where data points that are closer together are more likely to belong to the same class or have similar properties. KNN is a supervised learning algorithm, meaning it requires labeled training data in order to learn how to classify new data points. KNN can be used for both classification and regression problems, making it a versatile tool for many different types of machine learning applications.
Artificial Neural Networks (ANNs)
are a powerful tool for machine learning. By using ANNs, machines can learn from data and make decisions on their own. This is done by training the ANNs to recognize patterns in large datasets and then use those patterns to make predictions about future data. ANNs are used in a variety of applications, ranging from image recognition to natural language processing. With the help of ANNs, machines can become more intelligent and better equipped to solve complex problems.
Artificial Neural Networks: types, uses, and how they work- you can find detailed explanations and use cases in this article.
Naive Bayes
is a simple, yet effective and widely used machine learning algorithm for classification tasks. It is based on the idea of using Bayes' theorem to make predictions. Bayes' theorem describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
In the context of classification, Naive Bayes algorithm can be used to predict the class of a given data point based on a training dataset of known classifications. The key assumption of the Naive Bayes algorithm is that all the features of the data point are independent of each other, which is called the "naive" assumption. Despite this assumption, the algorithm often performs well in practice and is particularly useful when the number of features is large.
There are several variations of the Naive Bayes algorithm, including the Gaussian Naive Bayes, Multinomial Naive Bayes, and Bernoulli Naive Bayes. These variations differ in the way they calculate probabilities of the features and the class. Here you can find more informations about this ML Algorithm.
Conclusion
Overall, machine learning algorithms are powerful tools that can be used to extract insights and make predictions from data, but they are only as good as the data they are trained on and the assumptions they make. It is important to carefully evaluate the performance of machine learning models and to ensure that they are used ethically and responsibly.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}