
As ChatGPT "was born" nearly a year and a half from now, everyone out there is telling us that AI, especially LLMs, will steal our jobs. No more writers, no more developers, no more marketers, no more operators. The future seems to see AI as the king of the world.
While there's no doubt that AI is here to stay and support us in our daily jobs, is not so easy to say that it will replace jobs (and what jobs, particularly).
Also, as a user of ChatGPT, I noticed a degradation in its performance since it came on the market.
So, in this article, I'd like to raise some questions - and eventually, create discussions - about this topic:
what if ChatGPT has already seen its glorified period? Will it really increase its capabilities in a short period of time or will it take years to make great improvements?
I'll do so by introducing known procedures like training models to guide you through necessary things to take into account to reason about the topic.
NOTE: In this article, I will talk about ChatGPT for simplicity as it's the most famous (and maybe used) LLM, but the considerations apply to other similar software.
An introduction to training and evaluating an ML/DL model
When training and evaluating a Machine Learning (ML) or a Deep Learning (DL) model, data scientists always do the same thing: they get the available dataset and split it into the train and the test set.
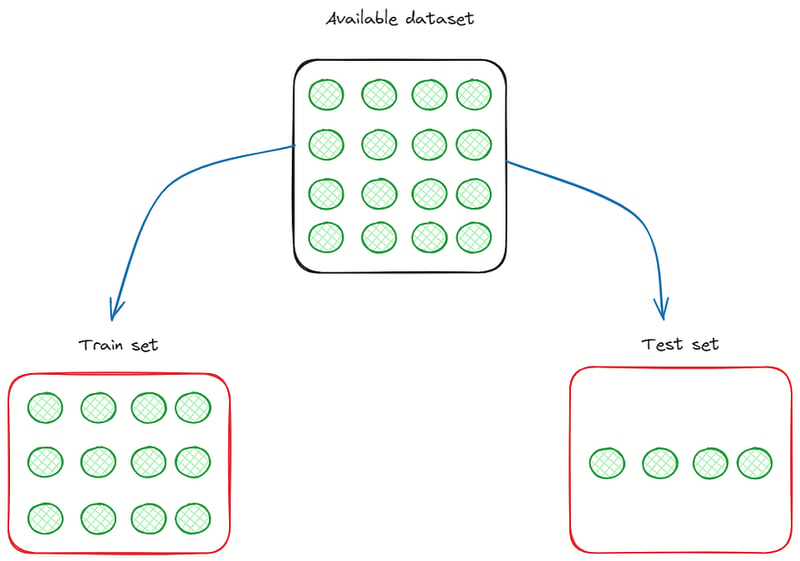
This operation is done to find the model that best fits the data. To do so, data scientists train different models on the train set and calculate some performance metrics. Then, they calculate the same performance metrics using the test set and find the best-performing model.
So, the importance of this methodology is that ML and DL models have to be evaluated on new and unseen data to verify that they are generalizing well what they have learned in the train set.
This is an important introduction to keep in mind for the subsequent part of this article.
The sets of combinations
In mathematics - in particular, in linear algebra - we talk about the sets of combinations.
The most famous one is the sets of linear combinations (also called "Span"). To define it, we use Wikipedia:
In mathematics, a linear combination is an expression constructed from a set of terms by multiplying each term by a constant and adding the results.
So, for example, the linear combination of two variables x and y could be created as:
Where a and b are two constant values (two numbers).
Anyway, the sets of combinations can also be non-linear. This means that a variable z can be created as a non-linear combination of x and y. It could be quadratic, cubic, or it could have another mathematical form.
Of course: this applies to variables as well as to all mathematical entities, like datasets.

How sets of combinations influence the performance of a model
Now, considering what we've defined until now, a question may arise:
What happens if the test set is a combination of the train set?
In this case, two major events may occur (both or one of the two):
- Data leakage. "Data leakage is when information from outside the training dataset is used to create the model. This additional information can allow the model to learn or know something that it otherwise would not know and in turn, invalidate the estimated performance of the model being constructed."
- Overfitting. This phenomenon occurs when the model has learned the specific patterns in the training data. This results in a low performance on the unseen data in the test set.
When these two phenomena occur, the model generalizes poorly. This means that the model may perform well on the test set because it reflects the combinations present in the training set, but its ability to perform on entirely new data is still unknown.
In other words, the model has an evaluation bias. This means that the evaluation metrics calculated on the test set can not reflect the model's actual performance (thus, are biased). This could lead to misguided confidence in the model's abilities.
Possible sets of combinations in training LLMs
Now, our interest here is in LLMs. As known, these models are trained on a vast amount of data. So, the more the data, the more the possibility of getting biased data.
Also, we don't know the actual data used to train ChatGPT, but we know that a significant proportion of the training data came from the Internet.
So, first of all, on the Internet (but this is a consideration that applies, in general, to books and other sources) a lot of websites describe the same topic. This may led to possible sets of combinations between the train and the test sets used.
Also, ML and DL models often need retraining to evaluate if the model still applies to new data incoming.
Imagine that ChatGPT was trained and evaluated in September 2022 for the first time (only using the Internet, for simplicity).
Imagine that the first retraining and re-evaluation was made in March 2023 (still only using the Internet, for simplicity). Some questions that may arise are:
- How much new content has been generated on the Internet since the first release of ChatGPT in November 2022 and the first retraining?
- How much new content on the Internet has been AI-generated since the first release of ChatGPT in November 2022 and the first retraining?
These questions are interesting to understand if LLMs are really improving or not because - as stated at the beginning of this article - I've seen more of a degradation in the performance, rather than an improvement (but, sure: I may be biased).
So, if the point of training (and re-training) is to evaluate a model on new unseen data, we can state that AI-generated content probably creates a subset of combination from data previously used to train the model, thus leading the model to data leakage, even though the training may be done with proper techniques to avoid it.
Will LLMs need years to get improvements in performance with other training?
When trying to find the model that best fits the data, we know that data quality has a higher impact than using a "better model" or better-fine-tuned hyperparameters of the same model.
So data quality is more important than model tuning. This particularly applies to LLMs that need a vast amount of data to be trained.
So, another question may be:
- Given the fact that AI-generated text on the Internet may lead to creating new data that are a subset of combinations of the train data, how much time should pass before a great and new amount of content is generated so that the performance can increase?
In other words: will LLMs need years to make actual improvements, on the contrary to what we are daily reading on the news?
Or, we should ask: what about ChatGPT can not actually be better than we know it today? As it already seen its glory days?
Conclusions
In this article, I wanted to make a reasoning about how ChatGPT is evolving on the side of performance.
I believe that re-training it using the Internet may lead to data leakage because AI-generated content is not a small proportion today of the whole content existing on the Internet. Also, this may lead to data leakage, thus a degradation of the performance, because this content is a subset of combinations of content previously created.
I'd like this article to create a genuine discussion on this topic, hoping to generate a positive and constructive one. Please: share your thoughts in the comments!
Hi, I am Federico Trotta and I'm a freelance Technical Writer.
Do you want to collaborate with me? Hire me.


















