
Discover how AWS Lambda works under the hood and get several tips on performance enhancement to refine your cloud solutions and serverless knowledge background.
In 2024, AWS Lambda redefines cloud computing with its serverless model, freeing developers from managing infrastructure. In this article I'd like to explore Lambda's internals: its operational model, containerization benefits, invocation methods, and the underlying architecture driving its efficiency and scalability.
Lambda Through the Eyes of a Regular Developer
For developers, AWS Lambda symbolizes a streamlined approach to application deployment and management. It's a shift from traditional server management to a more straightforward, code-focused methodology. It allows you to get the following benefits:
- Deployment Simplified: Lambda allows developers to deploy their code easily, either by uploading a ZIP file or using a container image. This simplicity means developers spend less time on setup and more on writing effective code.
- Language Choice: With support for various programming languages like Node.js, Python, Java, and Go, Lambda offers the freedom to work in a preferred language, enhancing coding efficiency and comfort.
- Automatic Scaling: Lambda's auto-scaling feature removes the burden of resource management from the developer. This means no worrying about server capacity, regardless of the application's demand.
Now, let’s dive deeper into how the choice of deployment type can affect your overall AWS performance.
Deployment Choices and Performance Optimization in AWS Lambda
AWS Lambda offers two primary deployment methods for functions, each catering to different application sizes and requirements.
Deployment Options:
- ZIP Deployment: This method suits smaller functions with limited dependencies. The ZIP deployment is straightforward but constrained by a lower size limit, making it less suitable for more extensive applications.
- Container Image Deployment: For larger applications, Lambda supports container images up to 10 GB. This increased capacity is ideal for applications that need larger libraries or more significant dependencies.
What about performance optimization? AWS Lambda has several peculiarities here:
1) Invocation Constraint in Firecracker
Lambda uses Firecracker for creating microVMs, each handling one invocation at a time. This model means a single instance cannot simultaneously process multiple requests, a consideration for high-throughput applications.
2) Caching as a Performance Enhancement
Lambda employs a three-tiered caching system to improve function performance:
- L1 Cache (Local Cache on Worker Host): Located directly on the worker host, this cache allows for quick access to frequently used data, essential for speeding up function invocations.
- L2 Cache (Shared Across Worker Hosts and Customers): This shared cache holds common data across different Lambda functions and customers, optimizing performance by reducing redundant data fetching.
- L3 Cache (S3 Bucket Managed by AWS): The L3 cache, for less frequently accessed data, provides efficient long-term storage in an S3 bucket, reducing retrieval times.
3) Optimizing Container Deployment
To maximize caching benefits, especially with container images, it's advisable to strategically structure container layers. Place stable elements like the operating system and runtime in base layers, and put frequently changing business logic in upper layers. This setup allows for more efficient caching of static components, speeding up the Lambda function's loading process.
Invocation Methods and Architecture of AWS Lambda
Now, let's focus on invocation methods to better understand how AWS Lambda genuinely works.
Lambda offers diverse invocation methods to suit different application needs and its architecture is designed to support these methods efficiently.
Invocation Methods:
- Synchronous Invocation: Typically used for interactive workloads like APIs. An example is an API Gateway triggering a Lambda function, which then queries a database and responds directly. This method is immediate and responsive, suitable for real-time data processing.
- Asynchronous Invocation: Used for scenarios like processing data uploaded to S3. The event triggers an internal queue managed by AWS Lambda, which then processes the function asynchronously. This method is ideal for workloads where immediate response to the triggering event is not required.
- Event Source Mapping: Particularly useful for streaming data services like Kinesis or DynamoDB Streams. Lambda polls these sources and invokes the function based on the incoming data. This method efficiently handles batch processing and is integral for applications dealing with continuous data streams.
Lambda Architecture Under the Hood
Finally, we’re ready to dive into how Lambdas work under the hood:
- Frontend Service: When a Lambda function is invoked, the frontend service plays a crucial role. It routes the request to the appropriate data plane services and manages the initial stages of the invocation process;
- Worker Hosts and MicroVMs: Lambda operates with worker hosts that manage numerous microVMs, crafted by Firecracker. Each microVM is uniquely dedicated to a single function invocation, ensuring isolated and secure execution environments. Furthermore, the architecture is designed so that multiple worker hosts can concurrently handle invocations of the same Lambda function. This setup not only provides high availability and robust load balancing but also enhances the scalability and reliability of the service across different availability zones;
- Firecracker: Firecracker is a vital component in Lambda’s architecture. It enables the creation of lightweight, secure microVMs for each function invocation. This mechanism ensures that resources are efficiently allocated and scaled according to the demand of the Lambda function;
- Internal Queueing in Lambda: For asynchronous invocation processes, AWS Lambda implements an internal queuing mechanism. When events trigger a Lambda function, they are initially placed in this internal queue. This system efficiently manages the distribution of events to the available microVMs for processing. The internal queue plays a crucial role in balancing the load, thereby maintaining the smooth operation of Lambda functions, especially during spikes in demand or high-throughput scenarios.
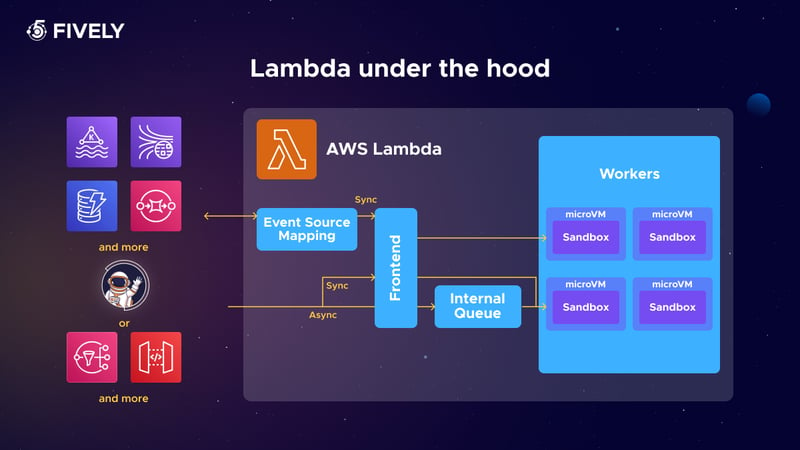
As you can see, it is the infrastructure that ensures the successful operation of AWS Lambdas. The number of Lambda calls is already surpassing trillions per month, and recently, on the 6th of December 2023, the scalability feature of AWS Lambda has been further enhanced up to 12 times, so the understanding of the Lambda internals will help you grasp how this became possible.


















