Snowflake Snowpark Migration Accelerator to Convert Your Spark Code to Snowpark —Here is All You Need To Know
Photo by Barth Bailey on Unsplash

If you have not heard until now, Snowflake released Snowpark, a set of libraries and code execution environments that run Python and other programming languages next to your data in Snowflake. Snowpark can be used to build data pipelines, ML models, apps, and other data processing tasks.
Snowpark Migration Accelerator is a free, self-service code assessment and conversion tool from Snowflake that helps developers get up and running in Snowpark from Spark faster and more efficiently.
Snowflake stresses that this tool is an accelerator and is not really testing the data and that you still need to do it yourself. It’s trying to accelerate your steps toward migrating to Snowpark.
Snowpark Migration Accelerator is focused on Spark, while another part of the tool is only available to Snowflake Professional Services for things like SQL Server and Oracle migration code conversions. I truly hope this tool gets expanded to include all capabilities for free.Snowpark Migration Accelerator
Snowpark Migration Accelerator
The Snowpark Migration Accelerator is a useful tool that can assist you in migrating your Spark data to Snowflake. It provides a comprehensive assessment of your existing data and conversion capabilities to speed up your migration process.
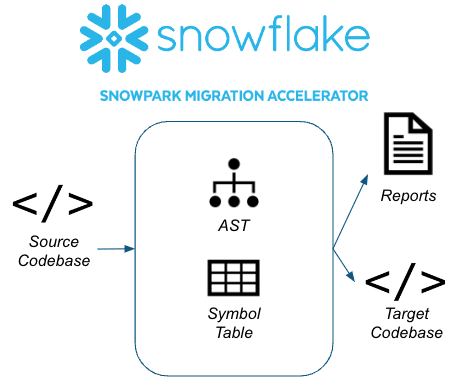
The Snowpark Migration Accelerator uses an automated migration framework that has been developed over the past 30 years. It applies this methodology to code languages that reference the Spark API. The application creates an Abstract Syntax Tree (AST) and a Symbol Table for the entire codebase that it scans.
The tool creates a semantic model that represents what the code does and recreates it to Snowflake. It is designed to provide the highest level of functional equivalence between the source and the target, making the process of migration much more efficient.
It can understand your source code by analyzing and creating a semantic model of your code’s behavior. It does not really use a matching model, for example, as it can recognize the usage of the Spark API in source code or notebook files, take inventory of them, and finally convert them to their functional equivalent by using the Snowpark API.
The tool has two modes. The assessment mode is fully available for any database supported by the Snowpark Migration Accelerator. Up until now, assessment has always been free, and conversion has been paid. Spark jobs are now free in conversion mode, which is great news for everyone needing to migrate from Spark to Snowflake.
The Snowpark Migration Accelerator supports these two platforms: Spark-Scala and PySpark.
The following file types are scanned for references to the Spark API:
- For Spark Scala: *.scala, *.ipynb, *.dbc
- For PySpark: *.py, *.python, *.ipynb and *.dbc
- Jupyter Notebook files (*.ipynb) and exported databricks (*.dbc) files when included in the source code directory
- SQL files (*.sql) and SQL cells in a notebook file (either *.ipynb or *.dbc) are also processed by the tool. These files will be scanned for SQL elements.
To give you a view into the possibilities, it can be used by a lot of platforms to migrate from. This is not a complete list, but you could use Databricks, Azure HDInsight, Azure data flows, AWS Glue, AWS EMR, Google Dataproc, and many other Spark-based engines available out there.
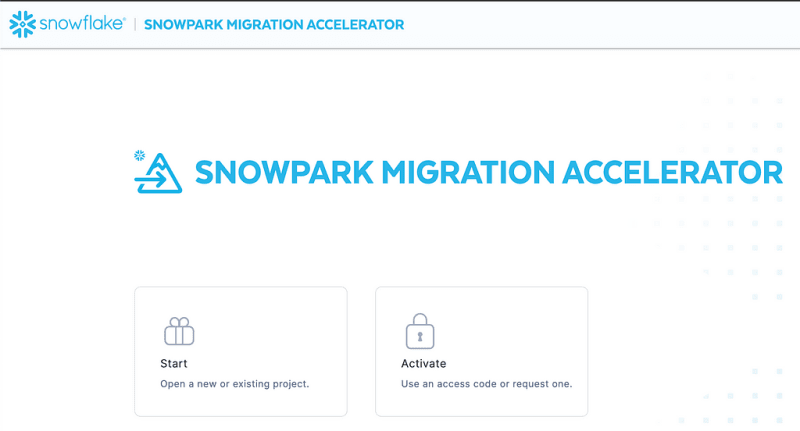
This is a view into the software before choosing the modes. You can see you can start, which gives you the assessment mode only, or activate it to get the conversion mode, too. Activate is free for Spark, but I will review this later.
Assessment
If you are not sure the tool, SMA would work for you, then start with the assessment. It is very easy to do an assessment against your code.
The first step in an assessment is to point the tool to the code, and for that, you have two options, you can add a directory with the files, or it can read Notebooks files.
I did not want to use any internal or client files, so I went around and found some samples in an AWS Glue Github. I downloaded the entire repository onto my computer.
Step 1: Click Start

Step 2: Click on New Project
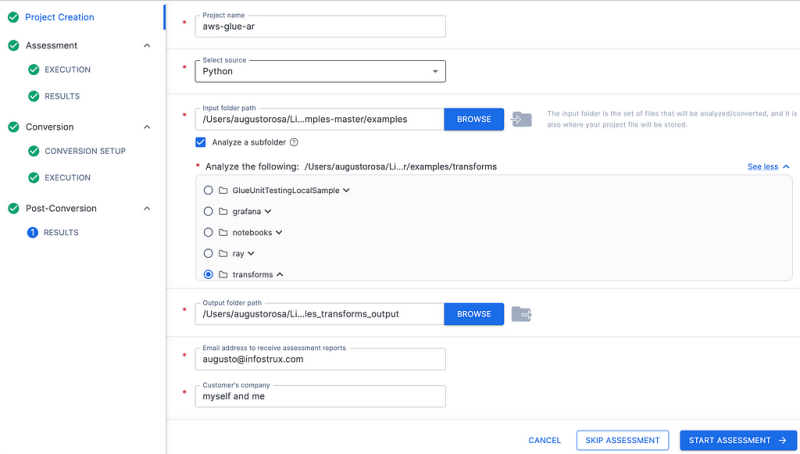
You can see it is quite straightforward. When you browse the folder with the code, I click “Analyse Subfolder” and go to the folder “Transformations.” The only thing worth mentioning is that you can pick Scala and Python as sources.
Step 3: Start Assessment
In a super quick way, it runs through the code and you get results.
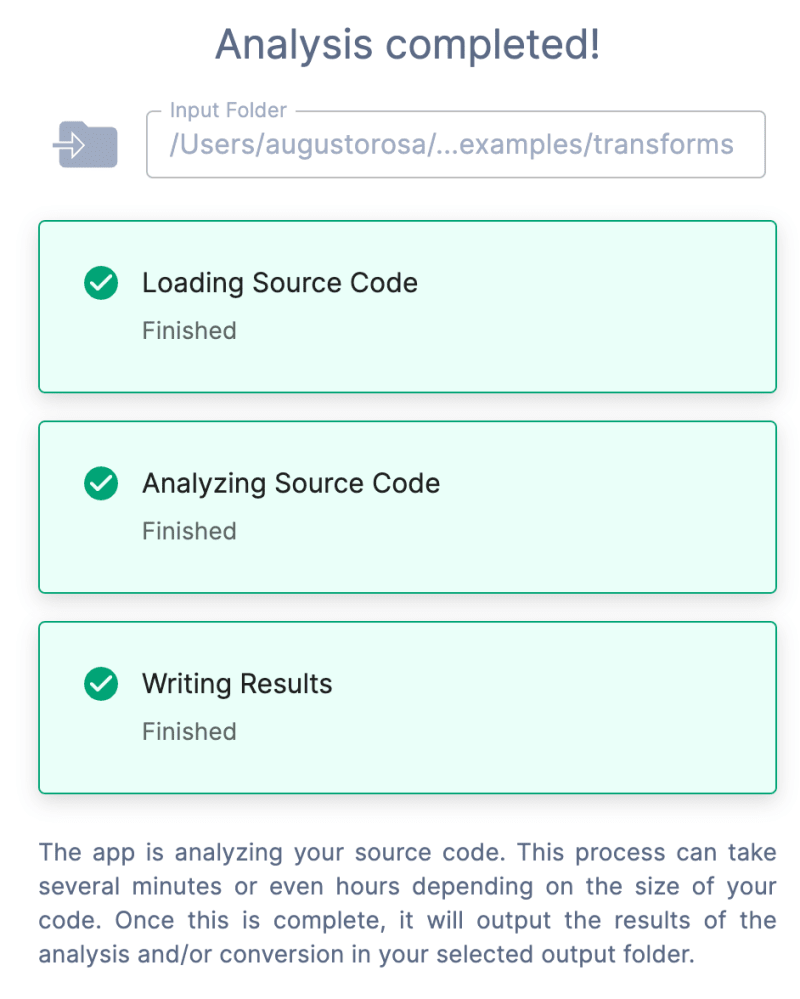
Step 4: Analysis Report
In the Analysis Report, there are two tabs: Assessment Report and Code Compare.
Assessment Report
I was very lucky on this simple transformation case and got a 100% Readiness Score, but in other actual use cases I tried, it is the upper 80%, which is still amazing. Keep in mind that the team keeps improving the compatibility with PySpark over time as well. I had some code from a previous migration that we had used this tool, and the Readiness Score increased by 5% from the last time we tried it.
It tells you things like Spark API Usages by Status or Categorization. It also shows you what Calls are being made and, finally, a File Summary. It is a lot of good information to help you plan your migration.

It tells you things like Spark API Usages, by Status or Categorization. It show you what Calls are being made as well, and finally a File Summary.
It is a lot of good information to help you plan your migration.
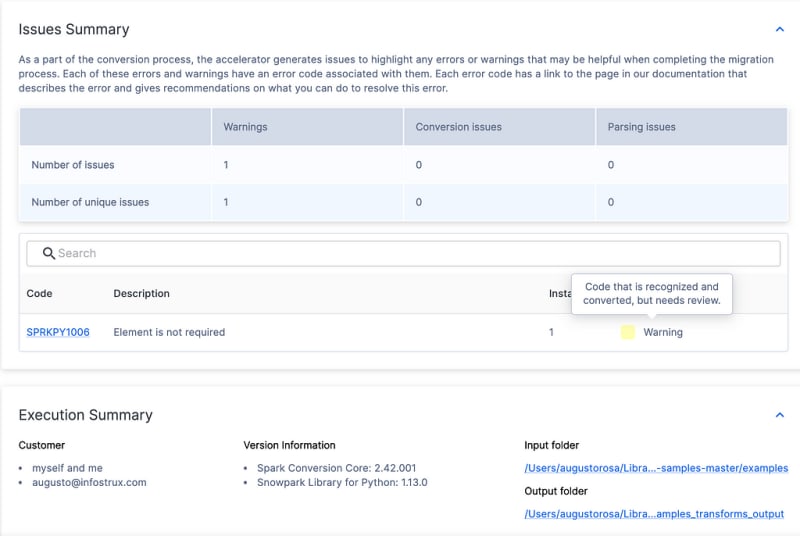
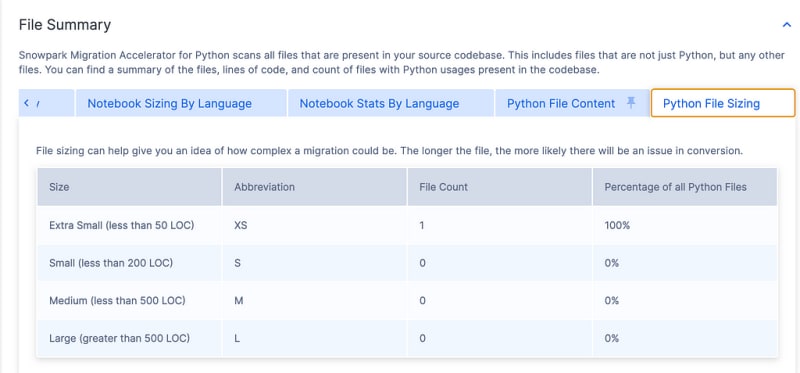
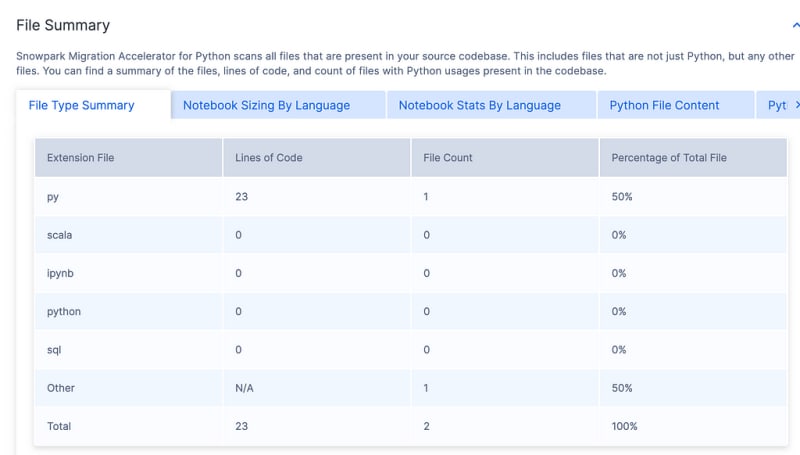

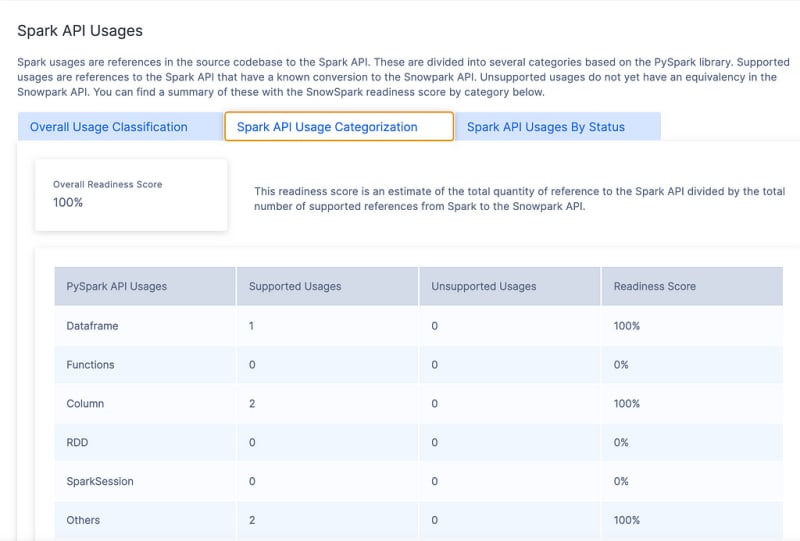
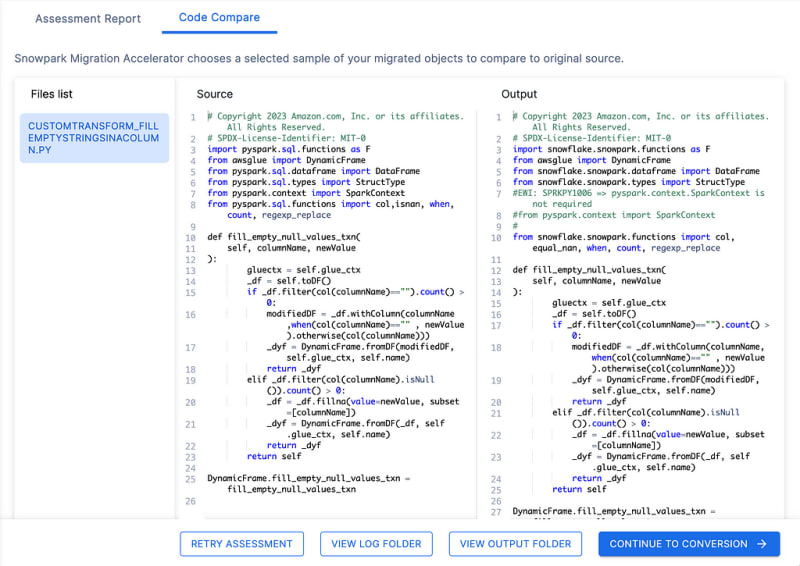
Code Compare
Let’s look at the Core Comparison tool before I run the conversion step. You can see all pyspark method, now show Snowflake. Snowpark in the Output.
Conversion
Before you can run a conversion, you need to get a free license key that will be sent to your email. I am told that the license requirement may disappear when this product goes into General Availability.
Step 1: License Key (one time only)
There is an Activate button on the top right corner of the tool, so go there and click on it. It will ask your personal details and you will automatically get the license key on your email. You get it right away.
The license lasts one month, and you can request another if you are still working on what you need.

Add the key into the SMA for a full activation. You won’t be able to do Step 2 if you do copy and paste your license.
Step 2: Conversion Setup
When you button Continue to Conversation, you land on the Conversion Setup step. It has already auto-populated much of the settings based on the assessment project, although you have to manually select the license key you just uploaded above.
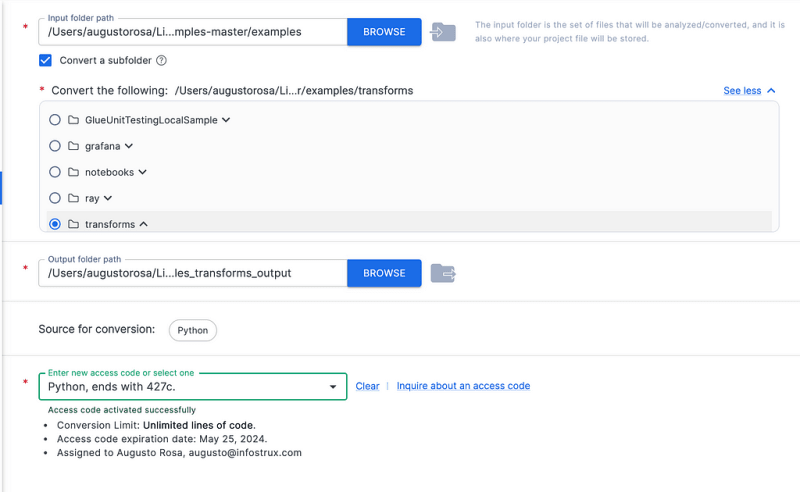
You can see that, you do have the ability to select what folder to convert.
Step 3: Conversion
Click on Start Conversion button, and it will quickly convert your code depends on how much you have.

Step 4: View Results
Click on View Results, and let’s look at it together.
SMA creates a couple folders, but the main folder to look is examples_transforms_output with an Assessment and Conversion sub-folder. You can see three folders there: Output, Reports and Logs.
This was a super simply conversion but I am putting both here side by side.

Old Code”
# Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: MIT-0
import pyspark.sql.functions as F
from awsglue import DynamicFrame
from pyspark.sql.dataframe import DataFrame
from pyspark.sql.types import StructType
from pyspark.context import SparkContext
from pyspark.sql.functions import col,isnan, when, count, regexp_replace
def fill_empty_null_values_txn(
self, columnName, newValue
):
gluectx = self.glue_ctx
_df = self.toDF()
if _df.filter(col(columnName)=="").count() > 0:
modifiedDF = _df.withColumn(columnName,when(col(columnName)=="" , newValue).otherwise(col(columnName)))
_dyf = DynamicFrame.fromDF(modifiedDF, self.glue_ctx, self.name)
return _dyf
elif _df.filter(col(columnName).isNull()).count() > 0:
_df = _df.fillna(value=newValue, subset=[columnName])
_dyf = DynamicFrame.fromDF(_df, self.glue_ctx, self.name)
return _dyf
return self
DynamicFrame.fill_empty_null_values_txn = fill_empty_null_values_txn
SMA Converted Code:
# Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: MIT-0
import pyspark.sql.functions as F
from awsglue import DynamicFrame
from pyspark.sql.dataframe import DataFrame
from pyspark.sql.types import StructType
from pyspark.context import SparkContext
from pyspark.sql.functions import col,isnan, when, count, regexp_replace
def fill_empty_null_values_txn(
self, columnName, newValue
):
gluectx = self.glue_ctx
_df = self.toDF()
if _df.filter(col(columnName)=="").count() > 0:
modifiedDF = _df.withColumn(columnName,when(col(columnName)=="" , newValue).otherwise(col(columnName)))
_dyf = DynamicFrame.fromDF(modifiedDF, self.glue_ctx, self.name)
return _dyf
elif _df.filter(col(columnName).isNull()).count() > 0:
_df = _df.fillna(value=newValue, subset=[columnName])
_dyf = DynamicFrame.fromDF(_df, self.glue_ctx, self.name)
return _dyf
return self
DynamicFrame.fill_empty_null_values_txn = fill_empty_null_values_txn
Complex Example
I picked a more complex example, this time a Databricks Notebook, and here are the results, and you can see some things get flagged as not supported this time. Like readwriter.DataFrameReader.option “inferSchema” or pyspark.sql.readwriter.DataFrameReader.option “header” while others SMA provides alternatives.
import os
import pandas as pd
import glob
#EWI: SPRKPY1002 => pyspark.sql.functions.input_file_name is not supported
#from pyspark.sql.functions import input_file_name, lit, col
from snowflake.snowpark.functions import lit, col
# Creates a list of all csv files
globbed_files = glob.glob("/dbfs/databricks-datasets/COVID/CSSEGISandData/csse_covid_19_data/csse_covid_19_daily_reports/*.csv")
#globbed_files = glob.glob("/dbfs/databricks-datasets/COVID/CSSEGISandData/csse_covid_19_data/csse_covid_19_daily_reports/04*.csv")
i = 0
for csv in globbed_files:
# Filename
source_file = csv[5:200]
process_date = csv[100:104] + "-" + csv[94:96] + "-" + csv[97:99]
# Read data into temporary dataframe
#EWI: SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.option "inferSchema" is not supported
#EWI: SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.option "header" is not supported
#EWI: SPRKPY1026 => pyspark.sql.readwriter.DataFrameReader.csv has a workaround, see documentation for more info
df_tmp = spark.read.option("inferSchema", True).option("header", True).csv(source_file)
df_tmp.createOrReplaceTempView("df_tmp")
# Obtain schema
schema_txt = ' '.join(map(str, df_tmp.columns))
# Three schema types (as of 2020-04-08)
schema_01 = "Province/State Country/Region Last Update Confirmed Deaths Recovered"# 01-22-2020 to 02-29-2020
schema_02 = "Province/State Country/Region Last Update Confirmed Deaths Recovered Latitude Longitude"# 03-01-2020 to 03-21-2020
schema_03 = "FIPS Admin2 Province_State Country_Region Last_Update Lat Long_ Confirmed Deaths Recovered Active Combined_Key"# 03-22-2020 to
# Insert data based on schema type
if ( schema_txt == schema_01 ):
df_tmp = ( df_tmp.withColumn("FIPS", lit(None).cast(IntegerType())).withColumn("Admin2", lit(None).cast(StringType())).withColumn("Province_State", col("Province/State")).withColumn("Country_Region", col("Country/Region")).withColumn("Last_Update", col("Last Update")).withColumn("Lat", lit(None).cast(DoubleType())).withColumn("Long_", lit(None).cast(DoubleType())).withColumn("Active", lit(None).cast(IntegerType())).withColumn("Combined_Key", lit(None).cast(StringType())).withColumn("process_date", lit(process_date)).select("FIPS", "Admin2", "Province_State", "Country_Region", "Last_Update", "Lat", "Long_", "Confirmed", "Deaths", "Recovered", "Active", "Combined_Key", "process_date") )
jhu_daily = jhu_daily.union(df_tmp)
elif ( schema_txt == schema_02 ):
df_tmp = ( df_tmp.withColumn("FIPS", lit(None).cast(IntegerType())).withColumn("Admin2", lit(None).cast(StringType())).withColumn("Province_State", col("Province/State")).withColumn("Country_Region", col("Country/Region")).withColumn("Last_Update", col("Last Update")).withColumn("Lat", col("Latitude")).withColumn("Long_", col("Longitude")).withColumn("Active", lit(None).cast(IntegerType())).withColumn("Combined_Key", lit(None).cast(StringType())).withColumn("process_date", lit(process_date)).select("FIPS", "Admin2", "Province_State", "Country_Region", "Last_Update", "Lat", "Long_", "Confirmed", "Deaths", "Recovered", "Active", "Combined_Key", "process_date") )
jhu_daily = jhu_daily.union(df_tmp)
elif ( schema_txt == schema_03 ):
df_tmp = df_tmp.withColumn("process_date", lit(process_date))
jhu_daily = jhu_daily.union(df_tmp)
else:
print("Schema may have changed")
raise
# print out the schema being processed by date
print("%s | %s" % (process_date, schema_txt))
#EWI: SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.option "header" is not supported
#EWI: SPRKPY1002 => pyspark.sql.readwriter.DataFrameReader.option "inferSchema" is not supported
#EWI: SPRKPY1026 => pyspark.sql.readwriter.DataFrameReader.csv has a workaround, see documentation for more info
map_popest_county = spark.read.option("header", True).option("inferSchema", True).csv("/tmp/dennylee/COVID/population_estimates_by_county/co-est2019-alldata.csv")
map_popest_county.createOrReplaceTempView("map_popest_county")
fips_popest_county = spark.sql("select State * 1000 + substring(cast(1000 + County as string), 2, 3) as fips, STNAME, CTYNAME, census2010pop, POPESTIMATE2019 from map_popest_county")
fips_popest_county.createOrReplaceTempView("fips_popest_county")
Coming Soon Features
- Convert elements for SparkML to SnowparkML
- Convert elements for Pandas and PySpark Pandas to Snowpark
- Improved categorization of import libraries
- Conversion walkthrough in the docs
Conclusion
This is my first time using the Snowpark Migration Accelerator (SMA) and I found to be straight forward and easy to use. I tried three different code bases with good results overall. I will do a live video next time to show the process of running the code in Snowflake and getting it to work.
Having analyzed any failed conversions, I would immeditaly try to run the code in a Snowflake Snowsight or CLI and follow the errors, logic and testing data matches until you have running code and data that matches between systems.
This is not fault prove process and software, but it is not intended to be, it is an Accelerator to get you there faster. I can speak about a client that used this tool and had more than 15,000 lines of code, and was able to convert 99% code into Snowpark Snowpark. It is incrediable for a free piece of software.
What else can do?
- Deploy the code via automation
- You could write unit testing so you guarantees the results in Snowpark are always good as part of your CI/CD builds
- At Infostrux, we found that having integration testing within the data also helps, and often we either are creating some python utility that compares the data or use an open-source tools that compares the source system to the target data and tell us what are differences

- Finally, you run through Staging / UAT testing typically done by the client or business team
I hope you found this step by step useful if you are going to try your migration from a Spark system to Snowpark.
If you do need professional help, remember that Infostrux specializes in Snowflake and can help you through our offers.
I am Augusto Rosa, VP of Engineering for Infostrux Solutions. Snowflake Data Super Hero and SME.
Thanks for reading my blog post. You can follow me on LinkedIn. Subscribe to more Blogs post https://blog.augustorosa.com for the most interesting Data Engineering and Snowflake news.
Sources:
- https://docs.snowconvert.com/sma/general/getting-started
- https://www.snowflake.com/snowflake-professional-services/snowpark-migration-accelerator/


















