
Introduction
The bigger the traffic, the bigger the latency and the higher the cost.
It seems that the global economic situation grounded us a bit and made us go back to basics when every byte of memory counted and every unnecessary line of code was removed. Besides higher latency which usually drives pouring better computing and more costs, we tend to forget we're paying a huge amount of money for the amount of transferred data as well, especially around communication between services.
Let’s take a look at the following scenario-
A single, shared EC2 instance, 2 CPUs with 4GB RAM,
processing 10,000 requests of 1KB per day -> 300,000 on an average month -> 292 GB of transferred data.
If we run those minor numbers with an AWS EC2 calculator, we would get the following invoice:
- Compute monthly cost is: $33.29 +
- Data transfer cost:
- If that 292 GBs is transferred within a region, it will cost $5.84 (14% of the total invoice)
- If that 292 GBs is transferred back to the internet, it will cost $26.28 (44% of the total invoice)
Popular formats
Usually, services communicate with each other using one of the following
- JSON.
JSON stands for JavaScript Object Notation and is a text format for storing and transporting data.
When using JSON to send a message, we’ll first have to serialize the object representing the message into a JSON-formatted string, then transmit.
{"sensorId": 32,"sensorValue": 24.5}
This string is 36 characters long, but the information content of the string is only 6 characters long. This means that about 16% of transmitted data is actual data, while the rest is metadata. The ratio of useful data in the whole message is increased by decreasing key length or increasing value size, for example, when using a string or array.
- Protobuf.
Protocol Buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data.
Protocol Buffers use a binary format to transfer messages.
Using Protocol Buffers in your code is slightly more complicated than using JSON.
The user must first define a message using the .proto file. This file is then compiled using Google’s protoc compiler, which generates source files that contain the Protocol Buffer implementation for the defined messages.
This is how our message would look in the .proto definition file:
message TemperatureSensorReading {
optional uint32 sensor_id = 1;
optional float sensor_value = 2;
}
When serializing the message from the example above, it’s only 7 bytes long. This can be confusing initially because we would expect uint32 and float to be 8 bytes long when combined. However, Protocol Buffers won’t use all 4 bytes for uint32 if they can encode the data in fewer bytes. In this example, the sensor_id value can be stored in 1 byte. It means that in this serialized message, 1 byte is metadata for the first field, and the field data itself is only 1 byte long. The remaining 5 bytes are metadata and data for the second field; 1 byte for metadata and 4 bytes for data because float always uses 4 bytes in Protocol Buffers. This gives us 5 bytes or 71% of actual data in a 7-byte message.
The main difference between the two is that JSON is just text, while Protocol Buffers are binary. This difference has a crucial impact on the size and performance of moving data between different devices.
Benchmark
In this benchmark, we will take the same message structure and examine the size difference, as well as the network performance.
We used Memphis schemaverse to act as our destination and a simple Python app as the sender.
The gaming industry use cases are usually considered to have a large payload, and to demonstrate the massive savings between the different formats. We used one of “Blizzard” example schemas.
The full used .proto can be found here.
Each packet weights 959.55KiB on average
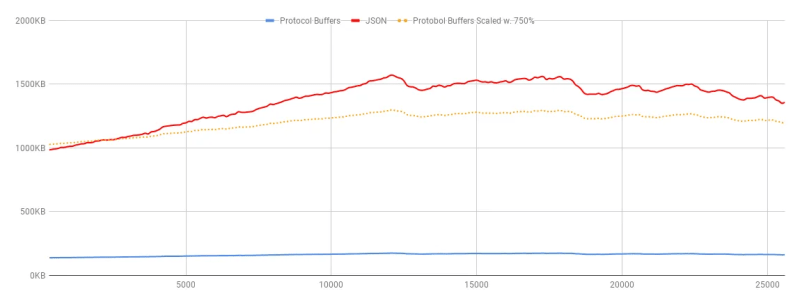
As can be seen, the average savings are between 618.19% to 807.93%!!!
Another key aspect to take under consideration would be the additional step of Serialization/Deserialization.
One more key aspect to take under consideration is the serialization function and its potential impact on performance, as it is, in fact, a similar action to compression.
Quick side-note. Memphis Schemaverse eliminates the need to implement Serialization/Deserialization functions, but behind the scenes, a set of conversion functions will take place.
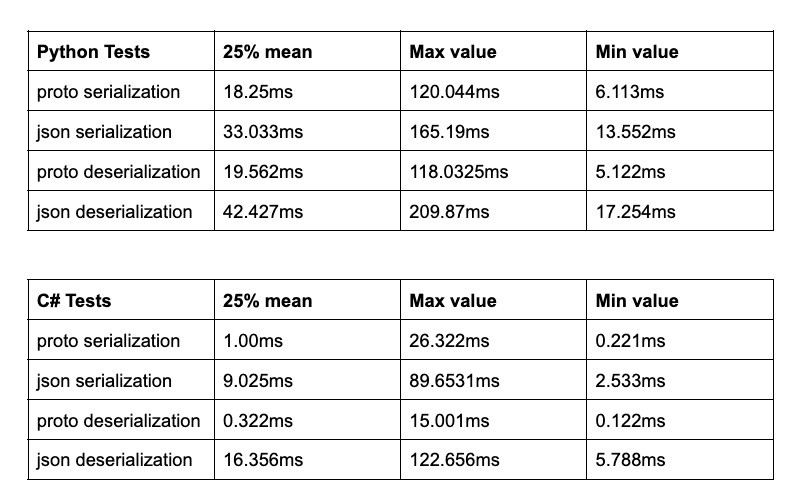
Going back to serialization. The tests were performed using a Macbook Pro M1 Pro and 16 GB RAM using Google.Protobuf.JsonFormatter and Google.Protobuf.JsonParser Python serialization/deserialization used google.protobuf.json_format
Summary
This comparison is not about articulating which is better. Both formats have their own strengths, but if we go from “the end” and ask ourselves what are the most important parameters for our use case, and both low latency and small footprint are there, then protobuf would be a suitable choice.
If the added complexity is a drawback, I highly recommend checking out Schemaverse and how it eliminates most of the heavy lifting when JSON is the used format, but the benefits of protobuf are appealing.
Resources
https://infinum.com/blog/json-vs-protocol-buffers/
https://levelup.gitconnected.com/protobuf-a-high-performance-data-interchange-format-64eaf7c82c0d
Join 4500+ others and sign up for our data engineering newsletter.
Originally published at memphis.dev by Sveta Gimpelson Co-founder & VP of Data & Research at Memphis.dev.
Follow Us to get the latest updates!
Github • Docs • Discord


















