Vamos supor que você tenha uma tarefa em que você precise remover itens duplicados de um array, considerando sempre o item com a data mais recente. Para simplificar, os objetos estão na estrutura { id: number, date: Date }.
Exemplo de array de entrada:
[
{ id: 3, date: '2023-01-03T00:00:00.000Z' },
{ id: 3, date: '2023-01-04T00:00:00.000Z' },
{ id: 4, date: '2023-01-02T00:00:00.000Z' },
{ id: 3, date: '2023-01-02T00:00:00.000Z' },
]
O resultado esperado seria um array com ids únicos
[
{ id: 3, date: '2023-01-04T00:00:00.000Z' },
{ id: 4, date: '2023-01-02T00:00:00.000Z' },
]
Você saberia tratar itens em larga escala com boa performance? Qual abordagem que te vem em mente para resolver o problema?
Para esse artigo, vamos gerar um array de dados aleatórios no formato de cima, pra testar a performance do código:
const randomInt = (limit) => Math.floor(Math.random() * limit);
const array = Array.from({ length: 100000 }).map((_, idx) => ({
id: randomInt(100),
date: new Date(2023, 0, randomInt(31), 0, 0, 0),
}));
Uma abordagem comum de se pensar para resolver esse problema é criar um método que filtre os itens do array utilizando um reduce, e/ou for. Para cada item do array verificamos se já existe aquele id no array, se não existir adicionamos ele, se existir verificamos o novo item é mais recente para substituí-lo
const removeDuplicates = (array) => {
const uniqArray = [];
for (let i = 0; i < array.length; i++) {
const item = array[i];
const index = uniqArray.findIndex((i) => i.id === item.id);
if (index === -1) {
uniqArray .push(item);
continue;
}
if (item.date > uniqArray[index].date) {
uniqArray[index] = item;
}
}
return uniqArray;
}
Essa abordagem resolve o problema de uma forma relativamente simples. Podemos checar o tempo de execução que essa função leva para processar o arquivo de entrada que foi inicialmente gerado.
const startTime = new Date();
removeDuplicates(array);
console.log(`Took: ${new Date() - startTime}ms`)
![]()
35 milissegundos para processar 100.000 itens em um array, não é tão demorado, e pararmos pra pensar. Pois é, mas aí que vem a pegadinha do malandro. O problema dessa abordagem é que definitivamente não é a melhor. Isso porque temos 2 loops um dentro do outro, quanto maior a quantidade de dados diferentes, mais doloroso será para a triste máquina que ousar executar esse código.
Se olharmos para nossa base de dados, temos apenas 100 ids diferentes. O que significa que o segundo loop, no pior dos casos, vai fazer apenas 100 iterações. Também significa que quanto mais ids diferente existirem, maior o tempo de demora. Com 1.000 ids diferentes ele demora 170ms e com 10.000 demora 1379ms, sim, mais de um segundo.
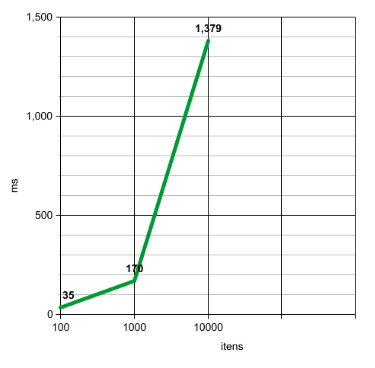
O crescimento do tempo de execução é exponencial. Mas como melhorar esse algoritmo então?
Vamos ver o que o chatgpt acha:
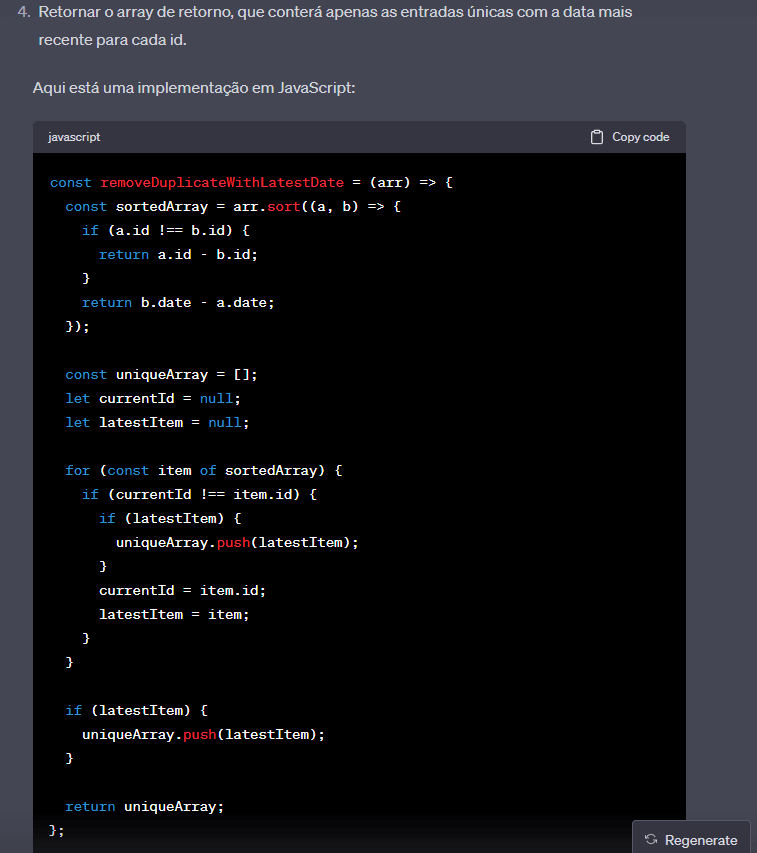
Admito que por esse algoritmo eu não esperava, ele está ordenando o array pelo id. Dessa forma ele consegue fazer a checagem de um id por vez, sem necessidade de realizar o find e loopar entre todos os itens de um array desordenado. Sendo assim, para ilustrar, ele verificar primeiro o id 1, compara e percebe qual o mais recente e, quando vê que chegou no id 2, armazena o item de id 1 mais recente, aí começa a verificar o id 2 e assim segue até o fim.
Vamos começar a usar uma ferramenta para comparar os algoritmos, a que irei utilizar aqui será o perf link. Esse site permite iniciar uma massa de dados e comparar o tempo de execução entre cada uma das abordagens. O site realiza a mesma operação várias vezes, então a quantidade inicial do array que utilizaremos será um pouco menor, apenas 10.000, ao invés dos 100.000 iniciais, para minimizar o tempo de execução.
Irei comparar o caso de existirem apenas 10 ids únicos, que significa que quase toda a massa de dados consiste em itens duplicados, e com os ids variando entre 1 e 9.000, como a função gera números aleatórios pro id não dá pra garantir que apenas 1.000 estarão duplicados, mas garantimos que tem muita probabilidade de existirem muitos ids únicos.
Sem mais delongas, comparemos a performance das duas abordagens:
Cenário com apenas 10 ids:

Cenário com 9.000 ids:

A performance do código do GPT é pior nos cenários em que existem mais duplicidades e melhor nos cenários infinitamente superior nos cenários que existem pouca duplicidade.
Mas e se existisse uma terceira forma ainda melhor? Será possível?
Bom, quando criamos um objeto no javascript ele funciona como se fosse um "dicionário" de dados, trazendo referencia direta a todas as "chaves" vinculadas aos valores. Será que conseguimos tirar proveito dessa propriedade nesse caso?
const removeDuplicatesKeyMap = (array) => {
const keyMap = {};
for (let i = 0; i < array.length; i++) {
const item = array[i];
if (!keyMap[item.id]) {
keyMap[item.id] = item;
continue;
}
if (item.date > keyMap[item.id].date) {
keyMap[item.id] = item;
}
}
return Object.values(keyMap)
}
O código acima cria um objeto indexando as chaves como os ids do array e os valores como sendo a referência ao próprio objeto. Então o array se transformaria em algo como:
{
3: { id: 3, date: '2023-01-04T00:00:00.000Z' },
4: { id: 4, date: '2023-01-02T00:00:00.000Z' },
}
Sempre que precisarmos de um item do array podemos acessa-lo diretamente pelo seu index, como se fosse uma propriedade normal. keyMap[3] retornaria o objeto { id: 3, date: '2023-01-04T00:00:00.000Z' }. Assim seria possível facilmente acessar todos os itens de acordo com o id de cada item.
Ok, a teoria parece boa, vamos ver na prática:
Com 10 ids diferentes:
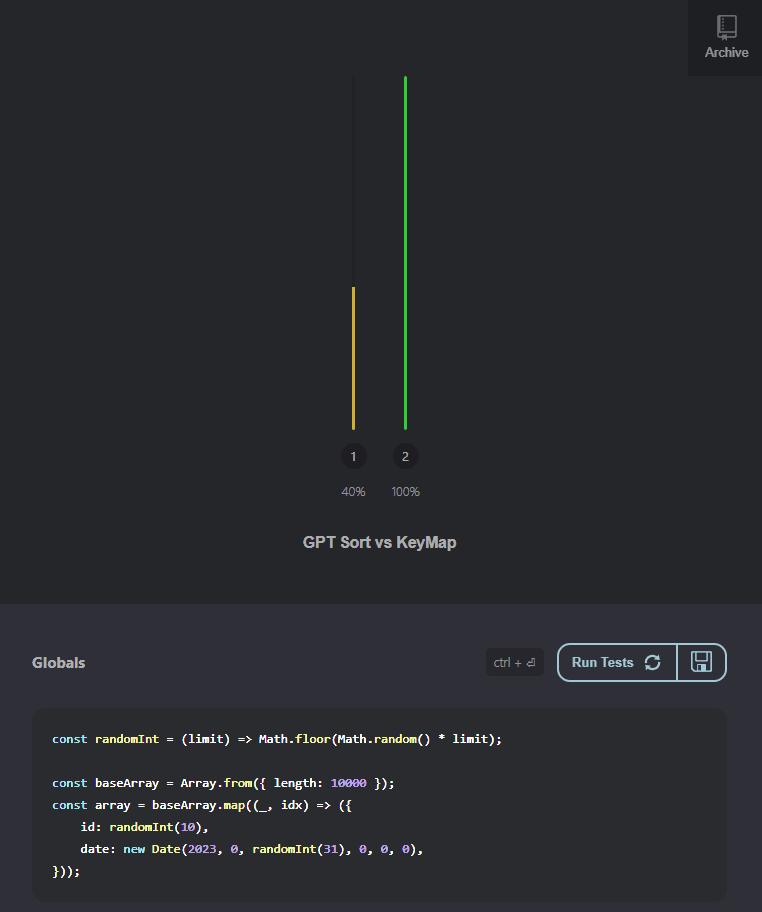
Com 9.000 ids diferentes:

💥 Booooom 💥, toma essa GPT, hoje você foi superado!!!
(só hoje hahaha)
Achei bem interessante quando descobri essa técnica, pesquisei outras abordagens para resolver esse problema, mas essa foi a melhor que consegui pensar.
Essa técnica também pode ser usada para um in memory join, quando necessário.
Lembrando que existem muitas outras formas de melhorar a arquitetura das aplicações para que não seja necessário executar tantos itens de uma vez. Mas performance de código, na minha visão, nunca é demais!
O que aconselho a levar desse artigo é sempre tentar entender e explorar formas diferentes de resolver o mesmo problema.
Você conhece conhecia essa estratégia? conhece outras estratégias para resolver o mesmo problema? compartilha com a gente aí em baixo 👇


















