
With process synchronization out of the way, it’s time to look into distributed system synchronization—specifically distributed mutual exclusion using logical clocks. Once again, the purpose of this article is to further solidify my understanding of the concept before my PhD qualifying exam.
Distributed Mutual Exclusion Overview
Up to this point, mutual exclusion was something that we were able to accomplish between processes on the same machine. In other words, these processes shared the same hardware and operating system, so we only had to worry about navigating that environment.
Now, we’re interested in distributed systems. In other words, a network of machines that have their own environments. For example, the internet is a massive distributed system. Of course, we can have distributed systems smaller than the local area networks (LAN) in our homes.
Sometimes processes on these networks need to share data just like processes do on the same machine. Naturally, the question becomes: “how do we protect those critical sections?” In this article, we’ll be looking at logical clocks as a mechanism for synchronizing distributed systems
Once again, the material for this article was borrowed from the lecture notes for the CSE 6431 course at The Ohio State University. Feel free to browse the slides below:
- OSU CSE 6431 Distributed Mutual Exclusion Part 1 (Logical Clocks)
- OSU CSE 6431 Distributed Mutual Exclusion Part 2 (Vector Clocks)
- OSU CSE 6431 Distributed Mutual Exclusion Part 3 (Lamport & Ricart-Agrawala Algorithm)
- OSU CSE 6431 Distributed Mutual Exclusion Part 4 (Maekawa Algorithm)
As always, all writing is my own.
Introduction to Logical Clocks
One way to synchronize distributed systems is to impose a clock on that system much like the way we handle processors today. Of course, it’s never really that simple.
Global Clocks
Normally, when we want to share information with somebody, we’re bound by the distance between us and that person. For example, if the person is close, we might be able to communicate with them directly. However, if they’re further away, we might opt for a phone call or even a text message. And if they’re somewhere remote, we may even decide to send a letter.
Unfortunately, the time it takes to deliver a message is not negligible. For example, in the last case, it could take days for the other person to receive our message. In addition, it takes time for them to write their response and even more time for them to deliver it back.
If for some reason, we had to send information that was time-sensitive (i.e. let’s meet in town on the 3rd), they may not get our letter in time. Even if they do get the letter in time, we may not receive their response in time (i.e. they can’t make it).
Of course, one solution is to make plans so far into the future that there’s no risk of either message not making it in time. Sadly, there are still potential problems. For example, something may prohibit our friend from making their commitment, and they may not find out until it’s too late to warn us. Luckily, we don’t really have to deal with these sort of problems as much, but they still exist in distributed systems.
What I’ve just described is similar to how a distributed system would work with a global clock. In other words, processes would make decisions on the assumption that all processes were aware of the current time. Of course, the assumption cannot possibly be true because messages have unpredictable delay. As a result, a process can end up corrupting shared memory because its local clock is too fast or too slow.
The Happens-Before Relation
Instead of dealing with timestamps, we can start thinking about interactions between machines as events. For example, take a look at the following pseudocode:
x = 10
x = x + 1
y = x - 2
In this example, we have two shared memory variables (x and y) which we interact with in some order:
- Write 10 to x
- Read x
- Write 11 to x
- Read x
- Write 9 to y
In this example, we don’t care about the actual time that these events occur. We only care about their order because their order determines the result. In particular, swapping lines can give the shared variables dramatically different values. More specifically, writing to x has to “happen before” we can read from it to increment it.
In distributed systems, we can take this idea of happens-before to a new level. In particular, when two process exchange messages, one process has to send a message before another process can receive that message. As a result, we can start reasoning about a logical ordering to the events in a distributed systems.
To go one step further, the happens-before relation is transitive. If some event a happens before some other event b and b happens before some third event c, then a must happen before c. With that property in mind, we can start synchronizing events.
Lamport’s Logical Clock
Interestingly enough, the happens-before relationship is pretty simple to implement. All we have to do is have each process (Pi) track their own events with a timestamp using the following rules:
- Clock Ci is incremented by d at each event in Pi (d > 0)
- When Pi sends a message m, that message is timestamped with the value obtained in the previous step
- When Pi receives a message m, Pi sets its clock to the max of its time and the timestamp on the message plus d (Ci = max(Ci, tm) + d)
In other words, processes maintain their own clocks and only update them if they receive a message with a higher timestamp. Below is an example of this algorithm in action:
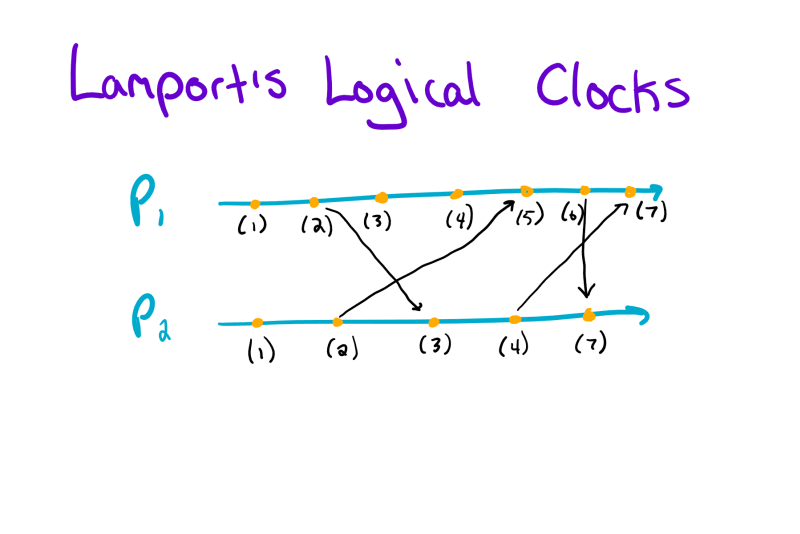
In this example, we have two processes: P1 and P2. Each process is denoted by a line which points off infinitely to the right. On each line, we’ll notice several orange dots. These dots denote events, and we mark each one with a timestamp according to the Lamport’s Logical Clock algorithm.
Occasionally, we’ll notice an arrow between processes. These arrows indicate messages passed between processes. According to our algorithm, message senders attach their current timestamp to their messages, so message receivers can update their local clock if necessary. See if you notice any places where a process had to update its clock.
Vector Clocks
Now, Lamport’s Logical Clocks have a bit of a limitation in that the happens-before relation only implies that the timestamp of one process is less than the other. Unfortunately, knowing the timestamps alone isn’t enough to prove the happens-before relation. To do that, we have to introduce Vector Clocks.
Like Lamport’s Logical Clocks, Vector Clocks work using the happens-before relation. However, instead of tracking a single local clock, Vector Clocks track all the clocks of all processes. Of course, we don’t want to introduce a global clock, so each process maintains its own clock as well as its best guess of all other clocks. In particular, Vector Clocks use the following rules:
- Clock Ci is a vector of length n where Ci[i] is its own logical clock
- When events a and b are on the same process, increment that process’s clock by d (Ci[i] = Ci[i] + d)
- When Pi receives a message m, Pi increments its own clock by d and updates every other clock with the max of itself and the timestamp of the message
Naturally, definitions can be hard to digest, so let’s take a look at another example borrowed from the slides:
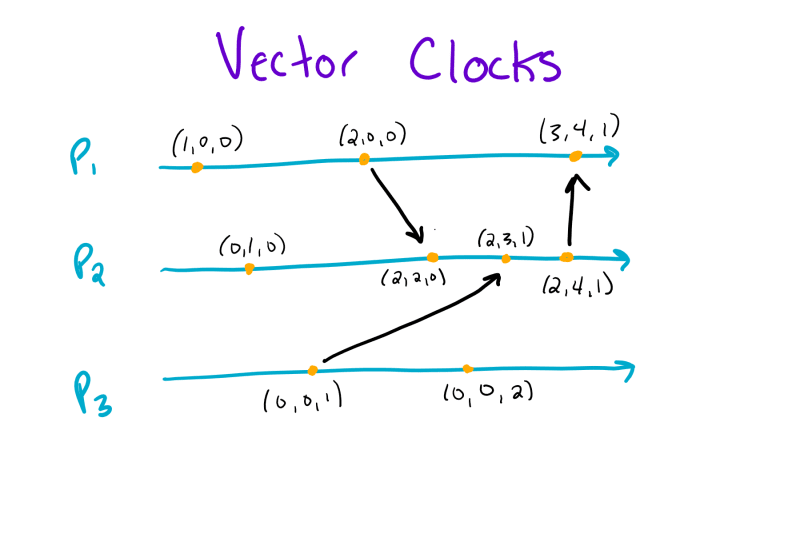
The main advantage of using a vector clock over a logical clock is that we can start looking at causal relationships. In particular, if all the timestamps of one vector clock event (E1) are less than all the timestamps of another vector clock event (E2), we can assume that the first event (E1) happened before the second (E2).
Mutual Exclusion Using Logical Clocks
With the concept of logical clocks in mind, we can start looking at better ways of applying mutual exclusion in distributed systems. In particular, we’ll take a high-level look at three algorithms: Lamport, Ricart-Agrawala, and Maekawa.
Before we get into that, I do want to mention that there’s sort of an obvious way to provide mutual exclusion at this point, right? Instead of having some complex asynchronous process handle the critical section problem, we could provide some centralized site which grants permission to processes which want to enter their critical sections. In the following sections, we’ll look at why that may not be the best course of action.
Lamport Algorithm
Instead of providing a centralized site, what if we developed some message passing scheme, so all processes would end up agreeing to take turns accessing their critical sections. Well, that’s exactly how the Lamport algorithm works.
The Lamport algorithm works by passing three messages: REQUEST, REPLY, and RELEASE. When a process wants to request access to their critical section, they send a REQUEST message out to all other processes before enqueueing the request in its own queue. Each process that receives the REQUEST message returns a REPLY message before enqueueing the request in its own queue.
From their, a requesting process only enters its critical section when it has received replies with timestamps greater than its current time from all other processes AND it’s first in its queue.
After processing its critical section, the process removes its request of its queue and sends out a RELEASE message to all other processes. When receiving a RELEASE message, each process will then remove the releasing process’s request from its queue.
As always, it’s much easier to look at a picture, so here’s the algorithm in action:
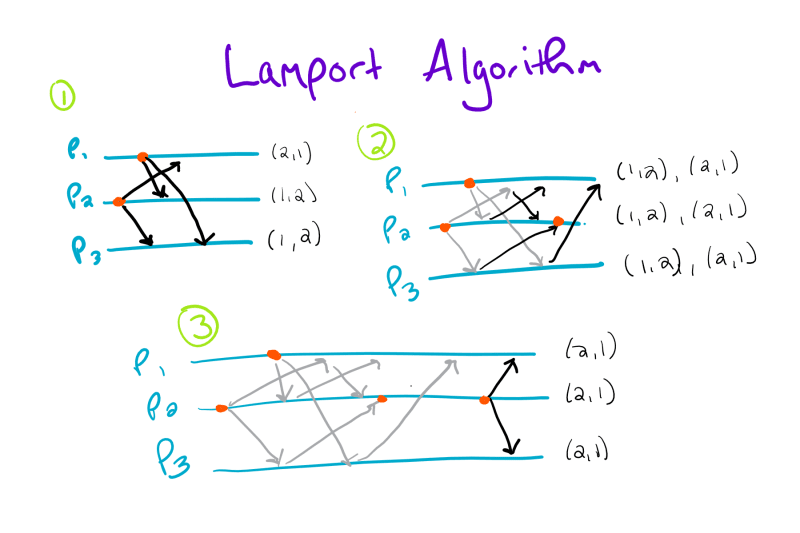
Each step shows the phases that the algorithm goes through. For example, step 1 shows the REQUEST message being sent out for processes one and two. Then, in step 2, the replies are sent. At which point, process two enters its critical section. Finally, in step 3, process two sends a pair of RELEASE messages, so process one can start executing.
Sadly, the main issue with the Lamport algorithm is its dependence on First-In-First-Out (FIFO) communication. In other words, the difference in transmission delays between processes can result in a destruction of mutual exclusion.
For example, imagine we have a two process distributed system. What happens if a process with an empty queue sends a request and receives a response? It should start executing, right? Well, as it turns out, it’s possible that the process that sent the reply happened to have sent a request earlier. Yet, somehow the reply beat the request to the other process. As a result, both processes may end up in their critical section.
Ricart-Agrawala Algorithm
Unfortunately, the Lamport algorithm has a couple drawbacks. For one, it assumes FIFO which isn’t realistic. In addition, there’s a lot of unnecessary message passing, and the algorithm relies on queues. Thankfully, the Ricart-Agrawala algorithm offers a few slight improvements over the previous algorithm.
Like the Lamport Algorithm, the Ricart-Agrawala algorithm leverages message passing and logical clocks for mutual exclusion. However, instead of three messages, the Ricart-Agrawala algorithm only uses two: REQUEST and REPLY.
Whenever a process needs to access its critical section, it sends a REQUEST message to all other processes—no queues needed. Each process that receives the REQUEST message sends a REPLY message if it is not executing its critical section or if its REQUEST has a larger timestamp. Otherwise, it defers its REPLY.
Ultimately, a process can only access its critical section if it has received replies from all processes. After accessing its critical section, the process sends a REPLY message to all deferred processes.
As always, its helpful to look at an example to really grasp this algorithm:
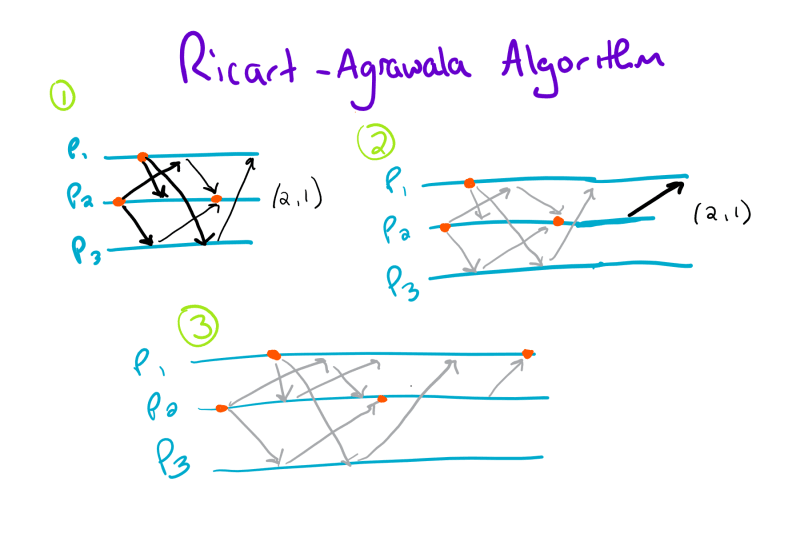
As we can see, there are a few less messages than the Lamport algorithm. In particular, we can compress steps one and two of the previous algorithm and eliminate a few messages in the process. In addition, the only queues we have to maintain are the deferred queues.
In step 1, process two gets the critical section. Then, in step two, process two messages the deferred process one after completing its critical section. At that point, process one enters its critical section.
Due to the nature of this algorithm, there’s no FIFO restriction. That’s because each process is personally responsible for granting permission. Even with out of order messages due to transmission delays, the REPLY message will never come thanks to the logical clocks.
Maekawa Algorithm
Normally, when a process wants to access its critical section, it blasts requests off to every other process in the distributed system. Of course, waiting on every process to reply can take time, so reducing the total number of messages that the process has to send can be a major performance boost.
Unlike the Lamport and Ricart-Agrawala algorithms, the Maekawa algorithm introduces request sets which are groups of processes with some special properties. In particular, each pair of request sets share at least one process.
Whenever a process wants to access its critical section, it sends a REQUEST message to all of the processes in its request set. When a process receives a REQUEST message, it sends a REPLY message if it has not sent a REPLY message since it last received a RELEASE message. Otherwise, the process stores the REQUEST message on a queue.
Naturally, a process is able to access its critical section once it has received all of the replies from its request set. When the process is finished executing, it sends a RELEASE message to all processes in its request set. As soon as a process receives a RELEASE message, it sends a REPLY message to the next process waiting in its queue.
While the algorithm alone is pretty simple, there are actually a lot of rules around setting up the request sets. For example, we already mentioned that every two sets should have at least one overlapping process. In addition, it’s a good idea to make sure all request sets are the same size and that each process appears an equal number of times across all sets. In other words, request sets should have a fixed size (K) and process should only be in a fixed number of sets (also K).
Apparently, the conditions above can be met using the following equation:
N = K(K - 1) + 1
In this equation, N is the number of processes and K is the size of each request site. For example, N = 7 and K = 3 would be a valid structure, and it might look like the following:

All that said, there’s a major caveat with this algorithm: it’s deadlock prone. After all, since pairs of sites deal with conflicts, it’s possible to have a cycle of conflicts between a handful of request sites.
Want to Learn More?
So far, we’ve mostly covered operating systems topics, and we’re only about halfway through. After this, there are about three more topics to cover: database concurrency control, deadlocks, and fault tolerance.
In terms of a timeline, finishing operating systems will bring me right up until two weeks before the exam. After that, I’ll start digging into the other two courses. Obviously, most of those articles won’t get published until I’ve already taken the exam, but I think they’ll still provide a lot of value to me.
At any rate, if you would like to support me in this journey, make sure to become a member. If you’re strapped for cash, you can always hop on the mailing list where you’ll receive updates every Friday.
While you’re here, why not take a look at some the following articles?
- Solutions to the Readers-Writers Problem
- Understanding the Number Theory Behind RSA Encryption
- The Difference Between Statements and Expressions
Once again, thanks for your support!
The post Distributed Mutual Exclusion Using Logical Clocks appeared first on The Renegade Coder.


















