In just 3-4 days, DeepSeek took over our Twitter feeds. I decided to dive deep into it, and while doing so, I wrote this blog based on my notes. So here is a simplified version of what is DeepSeek doing under the hood (not really under the hood because they are open source, haha).
While OpenAI provides some of the best LLMs, DeepSeek is pushing the boundaries by improving reasoning capabilities using Reinforcement Learning (RL).
They have two models:
DeepSeek-R1-Zero: Trained purely on RL.
DeepSeek-R1: Trained on RL and Supervised Fine-Tuning (SFT).
What is RL? It’s a type of machine learning where an AI model learns by trial and error. It gets rewarded for good actions and penalized for bad ones, helping it improve over time. For example, in chess:
The model (or agent) tries different moves (actions) to achieve a goal (e.g., checkmate).
It doesn’t know the best move at every step but learns by experimenting and receiving feedback (rewards or penalties).
The goal is to create a policy (a strategy) that maximizes the total reward over time, even if the immediate outcome of each action isn’t certain.
What is SFT? SFT is a process where a model is further trained on a specific dataset with labeled examples (e.g., questions and correct answers). This helps the model specialize in certain tasks.
Approach
Let’s break down the three main approaches they used:
DeepSeek-R1-Zero: Pure RL training on the base model.
DeepSeek-R1: Multi-stage training with RL, SFT, and cold-start data.
Distillation: Transferring reasoning capabilities to smaller models.
DeepSeek-R1-Zero: Pure RL Training
Reinforcement Learning Algorithm
They use Group Relative Policy Optimization (GRPO),Here’s how it works:
"Think of GRPO like a teacher grading a group of students. The teacher compares each student’s performance to the class average, ensuring no one is too far ahead or behind. This keeps the training stable and prevents drastic changes.”
Group Sampling: For each question, the model generates a group of responses. The reward for each response is compared to the average reward of the group, which helps stabilize training.
Advantage Calculation: The advantage Ai for each response is calculated as:
Ai= (ri−mean({r1,r2,…,rG})) / std({r1,r2,…,rG})
where ri is the reward for the i-th response, and G is the group size.
Policy Update: The goal is to update the policy to maximize the expected reward while keeping the new policy close to the old one (to avoid drastic changes).
Reward Modeling
They use a rule-based reward system with two components:
Accuracy Rewards: The model gets rewarded for correct answers. For example:
In math problems, the final answer must be in a specific format (e.g., inside a box) for automated verification.
In coding tasks, the code is compiled and tested against predefined test cases.
Format Rewards: The model is rewarded for following the correct format, such as enclosing the reasoning process in tags and the final answer in tags.
Let’s move to an important term: Chain of thoughts (CoT)
What it is: CoT is a technique where the model explains its reasoning step-by-step before giving the final answer. For example, instead of just saying "2 + 2 = 4," the model might say, "First, I add 2 and 2, which equals 4."
In DeepSeek, they encourage the model to use CoT to improve its reasoning and make its thought process more transparent.
While using DeepSeek you can use the “think” button to check how the model is reaching to a particular response.
DeepSeek-R1: Multi-Stage Training
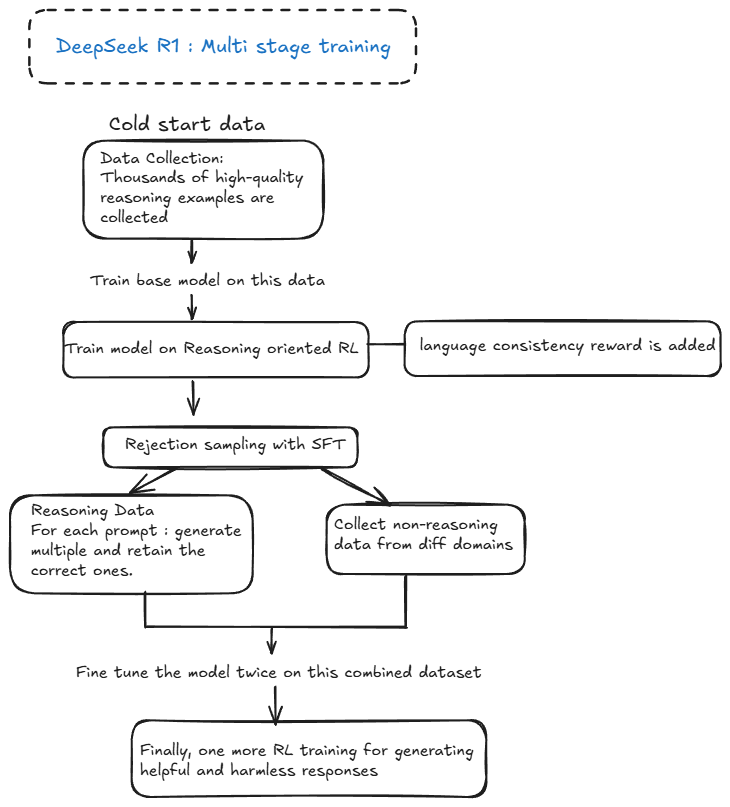
Cold Start
To address the readability and language mixing issues of DeepSeek-R1-Zero, they introduced cold-start data:
Data Collection: Thousands of high-quality reasoning examples are collected using few-shot prompting, model-generated outputs, and human annotation.
Fine-Tuning: The base model (DeepSeek-V3-Base) is fine-tuned on this cold-start data before applying RL.
Reasoning-Oriented RL
After fine-tuning, the model undergoes RL training similar to DeepSeek-R1-Zero. However, they also introduce a language consistency reward to reduce language mixing:(chinese and english)
Language Consistency: The reward is based on the proportion of target language words in the reasoning process. This aligns the model with human preferences for readability.
Rejection Sampling and SFT
Once the RL model converges, rejection sampling is used to generate high-quality training data:
“Rejection sampling is a technique where the model generates multiple responses, and only the best ones (based on correctness and quality) are kept for further training”
Reasoning Data: The model generates multiple responses for each prompt, and only the correct ones are retained. This results in ~600k reasoning-related training samples.
Non-Reasoning Data: Additional data from domains like writing, factual QA, and self-cognition are collected, totaling ~200k samples.
Fine-Tuning: The base model is fine-tuned on this combined dataset for two epochs.
RL for All Scenarios
A second RL stage is applied to align the model with human preferences across all scenarios:
Helpfulness and Harmlessness: The model is trained to prioritize helpful and harmless responses, using reward models to capture human preferences in complex scenarios.
Distillation: They also introduce distillation but we won’t go deep into it. Distillation in basic terms is the process that transfers reasoning capabilities from larger models to smaller models( which are faster and cheaper).
The Magic of Self-Evolution
The most magical part about their models is self-evolution. The model naturally develops advanced reasoning behaviors like reflection (revisiting previous steps) and long-chain reasoning (generating hundreds of reasoning tokens). These behaviors emerge without explicit programming, showcasing the power of RL.
That’s all!
As a result, DeepSeek’s R1 model is on par with OpenAI’s o1 series models in multiple benchmarks(and it’s free). Hope this was simple and clear enough to get a basic idea of how it’s working.
If you’re curious to learn more, I highly recommend reading their paper here.
Feel free to reach out to me on: X(Twitter) | LinkedIn


















