
Photo by Nathan John on Unsplash
Managing big data no longer means just buying bigger and faster servers
It now also means needing to understand the concept of parallel computing.
The list of tools and data systems that are helping manage this specific concept continues to grow on a yearly basis. Whether it be using AWS and querying on Redshift or custom libraries, the need to learn how to wrangle data in parallel is very valuable.
Python --- being the most popular language owing to its ease of use --- offers a number of libraries that enable programmers to develop more powerful software for the purpose of running models and data transforms in parallel.
What if a magical solution appears and offers parallel computing, speeded up algorithms, and even allows you to integrate NumPy and pandas with the XGBoost libraries?
Well, we do have that magic potion and it goes by the name of "Dask".
In this article, we will discuss what Dask is and why you might consider using it.
What Is Dask?
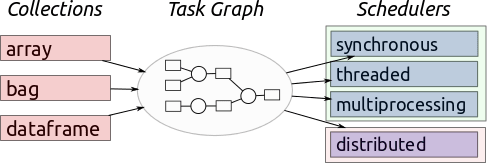
Dask is an open-source project that allows developers to build their software in coordination with scikit-learn, pandas, and NumPy. It is a very versatile tool that works with a wide array of workloads.
This tool includes two important parts; dynamic task scheduling and big data collections. The prior portion is very similar to Luigi, Celery, and Airflow, with the exception that it is specifically optimized for interactive computational workloads.
The latter portion includes data frames, parallel arrays, and lists extended to popular interfaces like pandas and NumPy.
In fact, Mr. Matthew Rocklin --- creator of Dask --- confirms that Dask was originally created to parallelize pandas and NumPy though it now offers many more benefits than a generic parallel system.
The data frames by Dask are ideal for scaling pandas workflows and enabling applications for time series. Besides, the Dask array offers multi-dimensional data analysis for biomedical applications as well as machine learning algorithms.
The Scalable Analytics Wizard
What makes Dask so popular is the fact that it makes analytics scalable in Python.
The magical feature is that this tool requires minimum code changes. This tool runs on clusters resiliently with over 1000 cores! Besides, you can run this code in parallel while processing data which simply translates to less execution time, less waiting time!
The Dask DataFrame comprises smaller pandas data frames which is why it allows subsets of pandas query syntax.
source:https://docs.dask.org/en/latest/
This tool is fully capable of scheduling, building, and even optimizing complex computational calculations into graphs. This is the reason why companies operating on 100s of terabytes can opt for this tool as a go-to option.
Dask also allows you to build pipelines for data arrays, which can later be shuttled off to relevant computing resources. All in all, this tool is much more than a parallel version of pandas.
How Dask Works
Now that we have understood the basic concept of Dask, let us take a look at a sample code to understand further:
import dask.array as da
f = h5py.File('myfile.hdf5')
x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
For those familiar with data frames and arrays, this is pretty much exactly where you are putting this data.
In this case, you have placed your data into the Dask version, you can utilize the distribution features provided by Dask to run similar functions as you would with pandas.
This is what makes Dask great when you are running it on the correct setup.
What About scikit-learn?
A popular library that is used by data scientists on a daily basis is scikit-learn. Sometimes, the amount of data you are processing is just too large to run on a single server.
Dask can help here too.
Dask has several options, for example, you can take pretty much any model and wrap it using the incremental wrapper. This wrapper allows the end-user to take advantage of the fact that some estimators can be trained incrementally without seeing the entire data set.
"For example,
[dask_ml.wrappers.Incremental](https://dask-ml.readthedocs.io/en/latest/modules/generated/dask_ml.wrappers.Incremental.html#dask_ml.wrappers.Incremental)provides a bridge between Dask and scikit-learn estimators supporting thepartial_fitAPI. You wrap the underlying estimator inIncremental.Dask-ML will sequentially pass each block of a Dask array to the underlying estimator's
partial_fitmethod."-Source
from dask_ml.wrappers import Incremental
from dask_ml.datasets import make_classification
import sklearn.linear_model
from sklearn.naive_bayes import BernoulliNB
est = sklearn.linear_model.SGDClassifier()
clf = Incremental(est, scoring='accuracy')
# OR
nb = BernoulliNB()
parallel_nb = Incremental(nb)
You can see the example below where you can use the incremental wrapper on your models pretty easily.
From here, it would just depend on how you decided to run your specific model and what set up your company has on the infrastructure side.
Why Is Dask So Popular?
As a modern framework generated by PyData, Dask is getting a lot of attention due to its parallel processing capabilities.
It is awesome when processing large amounts of data --- especially data chunks larger than RAM --- so as to gain useful insights. Companies benefit from the powerful analytics that Dask supplies, owing to its efficient parallel computations on single machines.
This is mainly why multinational firms such as Gitential, Oxlabs, DataSwot, and Red Hat BIDS are already employing Dask with their routine work systems. Overall, Dask is considered super-popular because:
- Integrations: Dask offers integration with many popular tools which include PySpark, pandas, OpenRefine, and NumPy.
- Dynamic task scheduling: It offers dynamic task scheduling and supports a number of workloads.
- Familiar API: Not only does this tool allow a developer to scale workflows more natively, with minimal code rewriting, but it also integrates well with the tools and even their APIs.
- Scaling out clusters: Dask figures out how to break down large computations and efficiently routes them onto distributed hardware.
- Security: Dask supports encryption and is authenticated via the usage of TLS/SSL certifications.
Pros and Cons of Dask
Now, we do have some alternatives to Dask such as Apache Spark and Anaconda, so why go for Dask? Let us weigh up the pros and cons in this regard.
Pros of using Dask
- It offers parallel computing with pandas.
- Dask offers similar syntax to the pandas API so it is less difficult to get acquainted with.
Cons of using Dask
- In the case of Dask, unlike Spark, you won't find a standalone mode in case you wish to try the tool before creating a cluster.
- It is not scalable with Scala and R.
Is It Time for You to Look Into Dask?
As a flexible Python library enabling parallel computing, Dask has a lot to offer. Not only can Dask run on distributed clusters but it also allows users to replace it with a single-machine scheduler as per their benefit.
On the other end of the spectrum, developers find this tool super convenient owing to its simple syntax which is very similar to Python libraries.
All in all, this tool comes as a win-win for all. So, if your organization is operating with big data, this is the tool you require. If you are a developer then you must get acquainted with Dask as soon as possible because "the future is here."
Are You Interested In Learning About Data Science Or Tech?
What Is Data Ops And How It Is Changing The Data World
Our Favorite Machine Learning Courses On Coursera For Free
Dynamically Bulk Inserting CSV Data Into A SQL Server
4 Must Have Skills For Data Scientists
SQL Best Practices --- Designing An ETL Video


















