
Recommending relevant content to the user is essential to keep the user interested in the app. Although it is a common feature that we would like to have in our apps, building it is not straightforward. This changed as vector databases and Open AI emerged. Today, we can perform semantic searches that are highly aware of the context of the content with just a single query into our vector database.
In this article, we will go over how you can create a Flutter movie-viewing app that recommends another movie based on what the user is viewing.
A quick disclaimer, this article provides an overview of what you can build with a vector database, so it will not go into every detail of the implementation. You can find the full code base of the app in this article here to find more details.
Why use a vector database for recommending content
In machine learning, a process of converting a piece of content into a vector representation, called embeddings, is often used, because it allows us to analyze the semantic content mathematically. Assuming we have an engine that can create embeddings that are well aware of the context of the data, we can look at the distance between each embedding to see if the two content are similar or not. Open AI provides a well-trained model for converting text content into an embedding, so using it allows us to create a high-quality recommendation engine.
There are numerous choices for vector databases, but we will use Supabase as our vector database in this article, because we want to also store non-embedding data, and we want to be able to query them easily from our Flutter application.
What we will build
We will be building a movie listing app. Think Netflix except the users will not be able to actually view the movie. The purpose of this app is to demonstrate how to surface related content to keep the users engaged.

Tools/ technologies used
- Flutter - Used to create the interface of the app
- Supabase - Used to store embeddings as well as other movie data in the database
- Open AI API - Used to convert movie data into embeddings
- TMDB API - A free API to get movie data
Creating the app
We first need to populate the database with some data about movies and its embeddings. For that, we will use the Supabase edge functions to call the TMDB API and the Open AI API to get the movie data and generate the embeddings. Once we have the data, we will store them in Supabase database, and query them from our Flutter application.
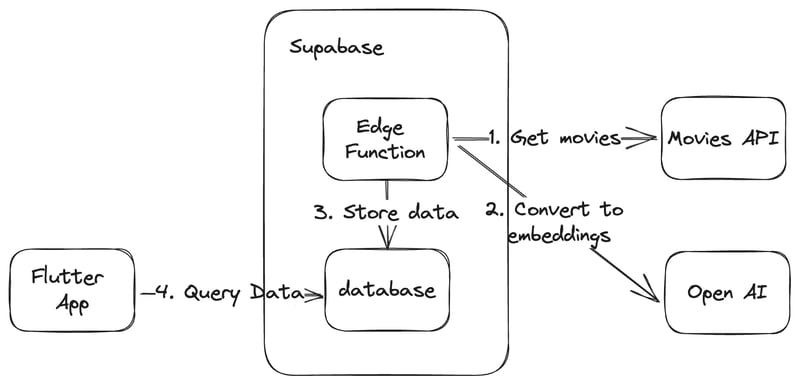
Step 1: Create the table
We will have one table for this project, and it is the films table. films table will store some basic information about each movie like title or release data, as well as embedding of each movie’s overview so that we can perform vector similarity search on each other.
-- Enable pgvector extension
create extension vector
with
schema extensions;
-- Create table
create table public.films (
id integer primary key,
title text,
overview text,
release_date date,
backdrop_path text,
embedding vector(1536)
);
-- Enable row level security
alter table public.films enable row level security;
-- Create policy to allow anyone to read the films table
create policy "Fils are public." on public.films for select using (true);
Step 2: Get movie data
Getting movie data is relatively straightforward. TMDB API provides an easy-to-use movies endpoint for querying information about movies while providing a wide range of filters to narrow down the query results.
We need a backend to securely call the API, and for that, we will use Supabase Edge Functions. Steps 2 through 4 will be constructing this edge function code, and the full code sample can be found here.
The following code will give us the top 20 most popular movies in a given year.
const searchParams = new URLSearchParams()
searchParams.set('sort_by', 'popularity.desc')
searchParams.set('page', '1')
searchParams.set('language', 'en-US')
searchParams.set('primary_release_year', `${year}`)
searchParams.set('include_adult', 'false')
searchParams.set('include_video', 'false')
searchParams.set('region', 'US')
searchParams.set('watch_region', 'US')
searchParams.set('with_original_language', 'en')
const tmdbResponse = await fetch(
`https://api.themoviedb.org/3/discover/movie?${searchParams.toString()}`,
{
method: 'GET',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${tmdbApiKey}`,
},
}
)
const tmdbJson = await tmdbResponse.json()
const tmdbStatus = tmdbResponse.status
if (!(200 <= tmdbStatus && tmdbStatus <= 299)) {
return returnError({
message: 'Error retrieving data from tmdb API',
})
}
const films = tmdbJson.results
Step 3: Generate embeddings
We can take the movie data from the previous step and generate embedding for each of them. Here, we are calling the Open AI Embeddings API to convert the overview of each movie into embeddings. overview contains the summary of each movie, and is a good source to create embedding representing each of the movies.
const response = await fetch('https://api.openai.com/v1/embeddings', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${openAiApiKey}`,
},
body: JSON.stringify({
input: film.overview,
model: 'text-embedding-ada-002',
}),
})
const responseData = await response.json()
if (responseData.error) {
return returnError({
message: `Error obtaining Open API embedding: ${responseData.error.message}`,
})
}
const embedding = responseData.data[0].embedding
Step 4: Store the data in the Supabase database
Once we have the movie data as well as embedding data, we are left with the task of storing them. We can call the upsert() function on the Supabase client to easily store the data.
Again, I omitted a lot of code here for simplicity, but you can find the full edge functions code of step 2 through step 4 here.
// Code from Step 2
// Get movie data and store them in `films` variable
...
for(const film of films) {
// Code from Step 3
// Get the embedding and store it in `embeddings` variable
filmsWithEmbeddings.push({
id: film.id,
title: film.title,
overview: film.overview,
release_date: film.release_date,
backdrop_path: film.backdrop_path,
embedding,
})
}
// Store each movies as well as their embeddings into Supabase database
const { error } = await supabase.from('films').upsert(filmsWithEmbeddings)
Step 5: Create a database function to query similar movies
In order to perform a vector similarity search using Supabase, we need to create a database function. This database function will take an embedding and a film_id as its argument. The embedding argument will be the embedding to search through the database for similar movies, and the film_id will be used to filter out the same movie that is being queried.
Additionally, we will set an HSNW index on the embedding column to run the queries efficiently even with large data sets.
-- Set index on embedding column
create index on films using hnsw (embedding vector_cosine_ops);
-- Create function to find related films
create or replace function get_related_film(embedding vector(1536), film_id integer)
returns setof films
language sql
as $$
select *
from films
where id != film_id
order by films.embedding <=> get_related_film.embedding
limit 6;
$$ security invoker;
Step 6: Create the Flutter interface
Now that we have the backend ready, all we need to do is create an interface to display and query the data. Since the main focus of this article is to demonstrate similarity search using vectors, I will not go into all the details of the Flutter implementations, but you can find the full code base here.
Our app will have the following pages:
- HomePage: entry point of the app, and displays a list of movies
- DetailsPage: displays the details of a movie as well as its related movies
components/film_cell.dart is a shared component to display a tappable cell for the home and details page. models/film.dart contains the data model representing a single movie.
The two pages look like the following. The magic is happening at the bottom of the details page in the section labeled You might also like:. We are performing a vector similarity search to get a list of similar movies to the selected one using the database function we implemented earlier.
The following is the code for the home page. It’s a simple ListView with a standard select query from our films table. Nothing special going on here.
import 'package:filmsearch/components/film_cell.dart';
import 'package:filmsearch/main.dart';
import 'package:filmsearch/models/film.dart';
import 'package:flutter/material.dart';
class HomePage extends StatefulWidget {
const HomePage({super.key});
@override
State<HomePage> createState() => _HomePageState();
}
class _HomePageState extends State<HomePage> {
final filmsFuture = supabase
.from('films')
.select<List<Map<String, dynamic>>>()
.withConverter<List<Film>>((data) => data.map(Film.fromJson).toList());
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('Films'),
),
body: FutureBuilder(
future: filmsFuture,
builder: (context, snapshot) {
if (snapshot.hasError) {
return Center(
child: Text(snapshot.error.toString()),
);
}
if (!snapshot.hasData) {
return const Center(child: CircularProgressIndicator());
}
final films = snapshot.data!;
return ListView.builder(
itemBuilder: (context, index) {
final film = films[index];
return FilmCell(film: film);
},
itemCount: films.length,
);
}),
);
}
}
In the details page, we are calling the get_related_film database function created in step 5 to get the top 6 most related movies and display them.
import 'package:filmsearch/components/film_cell.dart';
import 'package:filmsearch/main.dart';
import 'package:filmsearch/models/film.dart';
import 'package:flutter/material.dart';
import 'package:intl/intl.dart';
class DetailsPage extends StatefulWidget {
const DetailsPage({super.key, required this.film});
final Film film;
@override
State<DetailsPage> createState() => _DetailsPageState();
}
class _DetailsPageState extends State<DetailsPage> {
late final Future<List<Film>> relatedFilmsFuture;
@override
void initState() {
super.initState();
// Create a future that calls the get_related_film function to query
// related movies.
relatedFilmsFuture = supabase.rpc('get_related_film', params: {
'embedding': widget.film.embedding,
'film_id': widget.film.id,
}).withConverter<List<Film>>((data) =>
List<Map<String, dynamic>>.from(data).map(Film.fromJson).toList());
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.film.title),
),
body: ListView(
children: [
Hero(
tag: widget.film.imageUrl,
child: Image.network(widget.film.imageUrl),
),
Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
crossAxisAlignment: CrossAxisAlignment.stretch,
children: [
Text(
DateFormat.yMMMd().format(widget.film.releaseDate),
style: const TextStyle(color: Colors.grey),
),
const SizedBox(height: 8),
Text(
widget.film.overview,
style: const TextStyle(fontSize: 16),
),
const SizedBox(height: 24),
const Text(
'You might also like:',
style: TextStyle(
fontSize: 16,
fontWeight: FontWeight.bold,
),
),
],
),
),
// Display the list of related movies
FutureBuilder<List<Film>>(
future: relatedFilmsFuture,
builder: (context, snapshot) {
if (snapshot.hasError) {
return Center(
child: Text(snapshot.error.toString()),
);
}
if (!snapshot.hasData) {
return const Center(child: CircularProgressIndicator());
}
final films = snapshot.data!;
return Wrap(
children: films
.map((film) => InkWell(
onTap: () {
Navigator.of(context).push(MaterialPageRoute(
builder: (context) =>
DetailsPage(film: film)));
},
child: FractionallySizedBox(
widthFactor: 0.5,
child: FilmCell(
film: film,
isHeroEnabled: false,
fontSize: 16,
),
),
))
.toList(),
);
}),
],
),
);
}
}
And that is it. We now have a functioning similarity recommendation system powered by Open AI built into our Flutter app. The context used today was movies, but you can easily image that the same concept can be applied to other types of content as well.
Afterthoughts
In this article, we looked at how we could take a single movie, and recommend a list of movies that are similar to the selected movie. This works well, but we only have a single sample to get the similarity from. What if we want to recommend a list of movies to watch based on say the past 10 movies that a user watched? There are multiple ways you could go about solving problems like this, and I hope reading through this article got your intellectual curiosity going to solve problems like this.


















