by Richard Artoul
Zero Disk Architectures
In our previous post, we discussed why tiered storage won’t fix Kafka and how it will actually make your Kafka workloads more unpredictable and more difficult to manage. The fundamental problem with tiered storage is that it only gets rid of some of the disks. Even if we minimized the amount of time that data was buffered on the local broker disks to 1 minute, all of the issues in our previous post would still remain.
Tiered storage is all about using fewer disks. But if you could rebuild streaming from the ground up for the cloud, you could achieve something a lot better than fewer disks — zero disks. As we’ll demonstrate in the rest of this post (using WarpStream as a concrete example), the difference between some disks and zero disks is night and day. Zero Disk Architectures (ZDAs), with everything running directly through object storage with no intermediary disks, is better if you can tolerate a little extra latency. Much better.
Don’t just take it from me, though. Less than one year after our initial product launch and announcement that “Kafka is Dead, Long Live Kafka”, almost every other vendor on the market (Confluent included) has announced their plans to follow suit and retrofit their existing architectures over the next few years. With Confluent effectively abandoning the official open-source project in favor of their proprietary Kafka-compatible cloud product, it’s safe to say that Apache Kafka is well and truly dying, and what will live on is the protocol itself.
That said, I think that the industry conversations around Zero Disk Architectures have missed the forest for the trees by focusing exclusively on reducing costs. Don’t get me wrong, reducing the cost of using Kafka by an order of magnitude is a huge deal that cannot be understated, but it’s also only one small part of a much broader story.
In the rest of this post, I will do my best to tell the rest of the story and explain how WarpStream’s Zero Disk Architecture enables developers to do so much more than they ever could before, not just because they reduce costs by an order of magnitude, but because the architecture itself enables radically new functionality and deployment strategies that were previously impossible.
Specifically, I’ll cover three different topics that have been left out of the conversation so far and explain how Zero Disk Architectures:
- They are radically simpler and eliminate huge amounts of complexity and operational burden.
- Enable completely novel functionality that was previously impossible.
- Heavily tilt the scales in the SaaS vs. BYOC debate in favor of a completely new “Zero Access” BYOC model, at least for Kafka and the data streaming space.
Maximum Simplicity
Stateless compute enables elastic scaling
Let’s start with the basics. The most obvious benefit of WarpStream’s Zero Disk Architecture is auto-scaling. Since the “brokers” (Agents in WarpStream’s case) are completely stateless with zero local disks, they can be trivially auto-scaled in the same way that a traditional stateless web application can: add containers when CPU usage is high, and take them away when it’s low. No custom tooling, scripts, or Kubernetes operator required. In fact, when deployed in Kubernetes, WarpStream Agents are deployed using a Deployment resource just like a traditional stateless web server, not a StatefulSet.

WarpStream cluster auto-scaling in ECS
The graph above shows a real WarpStream cluster auto-scaling automatically based on CPU usage. Think about just how many moving parts would be required to pull that off with a stateful system like Apache Kafka that has any local disks or EBS volumes, and by contrast how it just falls out of the architecture, effectively for free, with WarpStream.
This operational simplicity completely changes how developers run and use the software. The number of users of existing data streaming products who can actually take advantage of anything remotely resembling actual auto-scaling is infinitesimally small. By contrast, almost every WarpStream BYOC customer is leveraging auto-scaling. It’s so easy that it becomes the default.
Isolate workloads with Agent Groups
Another benefit of WarpStream’s simple architecture is that since no Agent is “special” and any Agent can handle writes or reads for any topic-partition, massively scaling out writes or reads on a moment’s notice is feasible, just like with a traditional data lake.

If you’re worried that your massive data lake queries will interfere with your production workloads, you can just deploy an entirely new “group” of dedicated nodes whose only job is to act as thick proxies/caches for the data lake workloads while a completely different (and isolated) set of nodes handles the transactional workloads.

This approach brings the promise of HTAP to the data streaming space, with both transactional and analytical workloads completely isolated from each other but operating on the exact same dataset and with zero replication delay. No ETL is required.
WarpStream calls this feature Agent Groups and it underpins a deeper insight about Zero Disk Architectures: they enable radically flexible topologies and deployment models. For example, in addition to using Agent Groups to isolate transactional workloads from analytical ones, you can also use this feature to completely isolate producers from consumers:

Agent Groups can also be used to sidestep networking barriers entirely by deploying different groups of Agents into different VPCs, cloud accounts, or even regions and using the object storage bucket as the shared network layer:

This makes it trivial to create single logical clusters that span traditional cloud networking boundaries in an easy, simple, and cost-effective manner. While this may seem “boring”, in practice, many modern organizations need their data to be available across multiple “environments” and without the ability to leverage the object storage layer as a network, they have to resort to a complex, brittle, and expensive mess of solutions involving VPC peering, NAT gateways, load balancers, private links, and other exotic cloud networking products. With WarpStream, traditional cloud networking can be bypassed entirely in favor of using the object store itself as the network.
I know what you’re thinking at this point: “Come ON Richie, I thought this was going to be a cool article about some brand new whiz bang tech. Cloud networking!? Really? Who cares!?” And I get it. Cloud networking is mind-numbingly boring. But it is also really important, especially for Kafka, because Kafka is the beating heart of many organizations’ tech stack. It powers their internal observability pipelines, enables different teams to share data with each other, serves as the source of truth write ahead log for internal databases, enables CDC from operational datastores to analytical ones, and so much more. At its core, Kafka decouples the producer of a specific piece of data from its (often many) different consumers. None of that is possible if those producers and consumers are separated by an impermeable (technically or financially) network boundary.
Integrate All the Things with Managed Data Pipelines
Another great example of how Zero Disk Architectures enable completely novel functionality is that since the WarpStream Agents are completely stateless, they can be made significantly more feature-rich than traditional Kafka brokers. For example, imagine you’re using WarpStream to ingest application and AI/ML inference logs into an external system like ClickHouse. Another team requests that the data be made available as parquet files in object storage so that they can interact with it using a variety of different tools, and also because the security/compliance teams want a historical archive outside of Kafka.
With WarpStream’s Managed Data Pipelines, all you have to do to enable this functionality is click a few buttons in the WarpStream UI and paste in this configuration file:
input:
kafka_franz_warpstream:
topics:
- logs
output:
aws_s3:
batching:
byte_size: 32000000
count: 0
period: 5s
processors:
- mutation: |
root.value = content().string()
root.key = @kafka_key
root.kafka_topic = @kafka_topic
root.kafka_partition = @kafka_partition
root.kafka_offset = @kafka_offset
- parquet_encode:
default_compression: zstd
default_encoding: PLAIN
schema:
- name: kafka_topic
type: BYTE_ARRAY
- name: kafka_partition
type: INT64
- name: kafka_offset
type: INT64
- name: key
type: BYTE_ARRAY
- name: value
type: BYTE_ARRAY
bucket: $YOUR_S3_BUCKET
path: parquet_logs/${! timestamp_unix() }-${! uuid_v4() }.parquet
region: $YOUR_S3_REGION
warpstream:
cluster_concurrency_target: 6
The WarpStream Agents will now automatically consume the logs topic and generate the parquet files in S3. No custom code or additional services are required, and the entire data pipeline will run in your cloud account, on your VMs, and store data in your object storage buckets.
Now, if you’re an SRE or engineer who has ever been on-call for Apache Kafka, you might be feeling extremely uncomfortable right now. “Won’t that increase CPU usage on the Agents!?” The answer to that question is: “Yes.”, but also: “Who cares?”. The CPU auto-scaler will add more Agents if necessary without any manual intervention, and you can leverage WarpStream’s Agent Roles and Agent Groups functionality to run the data pipelines on isolated pools of Agents for larger workloads.
Is this the most efficient way to perform this task at a massive scale? Definitely not. Is it a reasonable and extremely cost-effective solution for 99% of use-cases? Absolutely. Unlike Kafka brokers, WarpStream Agents are cattle, not pets, and can be treated as such.
Zero Access and BYOC-native
The SaaS vs. BYOC debate has raged in the data streaming industry for a long time, and for good reason. To recap briefly: the BYOC deployment model is unbeatable in terms of unit economics and data sovereignty, which makes it very appealing for the highest scale workloads.
However, legacy BYOC models come with a lot of trade-offs as well. For example, legacy BYOC doesn’t necessarily present as a “fully managed” service in the way that most customers would expect from a, well, “managed” service. Historically most of the BYOC solutions on the market were just repackaged versions of the same stateful datacenter software that end-users have been struggling with for almost a decade now. Having that stateful datacenter software managed inside the customer’s cloud account / VPC by the vendor certainly helps, but it also doesn’t eliminate all of the fundamental problems associated with running that software in the cloud in the first place.
In addition, to make it all work, the customer has to grant the vendor high level cross-account IAM access and privileges so that when something inevitably goes wrong with one of the stateful components, the vendor can tunnel into the customer’s environment and manually fix it. This works, but it represents a huge security risk and liability for the customer, since the vendor (and all of their support staff) effectively have root access to the customer’s account and data.
It’s easy to see why BYOC architectures occupy a unique niche in the space. They can dramatically reduce costs, but they also come with a lot of serious tradeoffs and risks. However, the emergence of Zero Disk Architectures changes the calculus significantly.
Specifically, since all the tricky problems related to storage (durability, availability, scalability, etc) can be offloaded to the cloud provider’s object store implementation, it’s now feasible for the customer to manage all of the (now stateless) compute / data plane on their own, with zero cross-account IAM access or privileges granted to the vendor. This makes it impossible for the vendor to access the customer’s production environment or data.
Of course, storage isn’t the only tricky part about running a data streaming system. The other part that can be really hard to manage is the metadata / consensus layer. That’s why WarpStream was designed from Day 1 with a “BYOC-native” architecture that not only separates compute from storage, but also data from metadata. This creates a shared responsibility model that looks something like this:
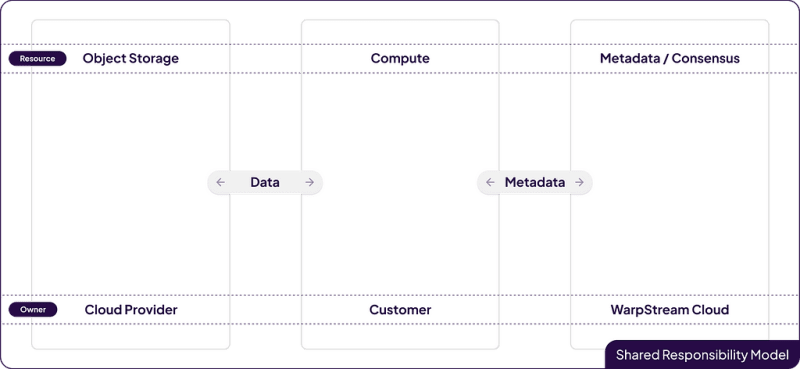
Storage scaling is handled by the cloud provider, metadata scaling is handled by WarpStream Cloud, and compute scaling is trivially managed by the customer by auto-scaling on CPU usage. We think that’s a game changer because the end-user is responsible for only one thing: providing compute, and that’s the one thing that everyone running software in the cloud knows how to do: schedule and run stateless containers.
When a customer deploys WarpStream into their environment, they don’t grant WarpStream Cloud any permissions or give WarpStream engineers the ability to SSH into their environment in an emergency. Instead, they just deploy the single WarpStream Agent docker image into their environment, however they prefer to deploy containers. Everything “just works” as long as that container has access to an object storage bucket and can reach WarpStream’s control plane to handle metadata operations. There’s really nothing more to it. In fact, this model is so secure that we even have customers leveraging this model in GovCloud environments!
In summary, this new “Zero Access BYOC-native” approach strengthens all of the core value propositions of existing BYOC deployment models (low costs, full data sovereignty), while also eliminating almost all of their drawbacks (remotely administering/scaling stateful storage services, security holes).
Zero Disk Architectures are Changing Everything (about Kafka)
I’ll conclude with this: Zero Disk Architectures are going to transform the entire data streaming space as we know it. Everything from pricing to capabilities and even deployment models is going to be flipped entirely on its head. But right now, WarpStream is the only Zero Disk Architecture streaming system on the market that you can actually buy and use today.
If you’re an existing Kafka user who’s struggling with operations, costs, or lack of flexibility, there’s never been a better time to try something new. WarpStream’s BYOC product is cheaper to run than self-hosting Apache Kafka, and its Zero Disk Architecture means you’ll never have to deal with partition rebalancing, replacing nodes, broker imbalances, full disks, Zookeeper/Kraft, or fussy cloud networking products.
Click here to get started for free. No credit card is required, and your first $400 in platform fees is on us.


















