Originally published in my blog: https://sobolevn.me/2020/03/do-not-log
Almost every week I accidentally get into this logging argument. Here's the problem: people tend to log different things and call it a best-practice. And I am not sure why. When I start discussing this with other people I always end up repeating the exact same ideas over and over again.
So. Today I want to criticize the whole logging culture and provide a bunch of alternatives.
Logging does not make sense
Let's start with the most important one. Logging does not make any sense!
Let's review a popular code sample that you can find all across the internet:
try:
do_something_complex(*args, **kwargs)
except MyException as ex:
logger.log(ex)
So, what is going on here? Some complex computation fails and we log it. It seems like a good thing to do, doesn't it? Well. In this situation, I usually ask several important questions.
The first question is: can we make bad states for do_something_complex() unreachable? If so, let's refactor our code to be type-safe. And eliminate all possible exceptions that can happen here with mypy. Sometimes this helps. And in this case, we would not have any exception handling and logging at all.
The second question I ask: is it important that do_something_complex() did fail? There are a lot of cases when we don't care. Because of the retries, queues, or it might be an optional step that can be skipped. If this failure is not important - then just forget about it. But, if this failure is important - I want to know exactly everything: why and when did it fail. I want to know the whole stack trace, values of local variables, execution context, the total number of failures, and the number of affected users. I also want to be immediately notified of this important failure. And to be able to create a bug ticket from this failure in one click.
And yes, you got it correctly: it sounds like a job for Sentry, not logging.
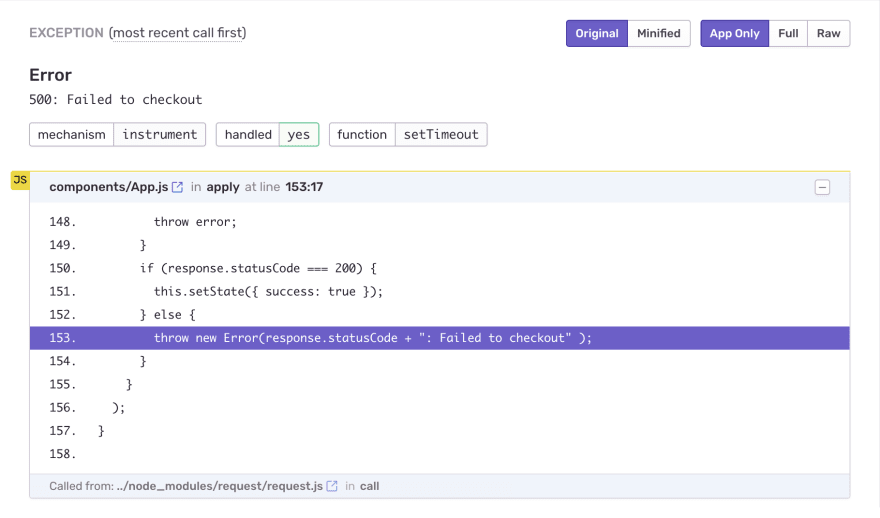
I either want a quick notification about some critical error with everything inside, or I want nothing: a peaceful morning with tea and youtube videos. There's nothing in between for logging.
The third question is: can we instead apply business monitoring to make sure our app works? We don't really care about exceptions and how to handle them. We care about the business value that we provide with our app. Sometimes your app does not raise any exception to be caught be Sentry. It can be broken in different ways. For example, your form validation can return errors when it should not normally happen. And you have zero exceptions, but a dysfunctional application. That's where business monitoring shines!

We can track different business metrics and make sure there are new orders, new comments, new users, etc. And if not - I want an emergency notification. I don't want to waste extra money on reading logging information after angry clients will call or text me. Please, don't treat your users as a monitoring service!
The last question is: do you normally expect do_something_complex() to fail? Like HTTP calls or database access. If so, don't use exceptions, use Result monad instead. This way you can clearly indicate that something is going to fail. And act with confidence. And do not log anything. Just let it fail.
Logging is a side effect
One more important monad-related topic is the pureness of the function that has a logger call inside. Let's compare two similar functions:
def compute(arg: int) -> float:
return (arg / PI) * MAGIC_NUMBER
And:
def compute(arg: int):
result = (arg / PI) * MAGIC_NUMBER
logger.debug('Computation is:', result)
return result
The main difference between these two functions is that the first one is a perfect pure function and the second one is IO-bound impure one.
What consequences does it have?
- We have to change our return type to
IOResult[float]because logging is impure and can fail (yes, loggers can fail and break your app) - We need to test this side effect. And we need to remember to do so! Unless this side effect is explicit in the return type
Wise programmers even use special Writer monad to make logging pure and explicit. And that requires to significantly change the whole architecture around this function.
We also might want to pass the correct logger instance, which probably implies that we have to use dependency injection based on RequiresContext monad.
All I want to say with all these abstractions is that proper logging architecture is hard. It is not just about writing logger.log() here and there. It is a complex process of creating proper abstractions, composing them, and maintaining strict layers of pure and impure code.
Is your team ready for this?
Logging is a subsystem
We used to log things into a single file. It was fun!
Even this simple setup required us to do periodical log file rotation. But still, it was easy. We also used grep to find things in this file. But, even then we had problems. Do you happen to have several servers? Good luck finding any required information in all of these files and ssh connections.
But, now it is not enough! With all these microservices, cloud-native, and other 2020-ish tools we need complex subsystems to work with logging. It includes (but is not limited to):
And here's an example of what it takes to set this thing up with ELK stack:
version: '3.2'
services:
elasticsearch:
build:
context: elasticsearch/
args:
ELK_VERSION: $ELK_VERSION
volumes:
- type: bind
source: ./elasticsearch/config/elasticsearch.yml
target: /usr/share/elasticsearch/config/elasticsearch.yml
read_only: true
- type: volume
source: elasticsearch
target: /usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
environment:
ES_JAVA_OPTS: "-Xmx256m -Xms256m"
ELASTIC_PASSWORD: changeme
discovery.type: single-node
networks:
- elk
logstash:
build:
context: logstash/
args:
ELK_VERSION: $ELK_VERSION
volumes:
- type: bind
source: ./logstash/config/logstash.yml
target: /usr/share/logstash/config/logstash.yml
read_only: true
- type: bind
source: ./logstash/pipeline
target: /usr/share/logstash/pipeline
read_only: true
ports:
- "5000:5000/tcp"
- "5000:5000/udp"
- "9600:9600"
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
networks:
- elk
depends_on:
- elasticsearch
kibana:
build:
context: kibana/
args:
ELK_VERSION: $ELK_VERSION
volumes:
- type: bind
source: ./kibana/config/kibana.yml
target: /usr/share/kibana/config/kibana.yml
read_only: true
ports:
- "5601:5601"
networks:
- elk
depends_on:
- elasticsearch
networks:
elk:
driver: bridge
volumes:
elasticsearch:
Isn't it a bit too hard?! Look, I just want to write strings into stdout. And then store it somewhere.
But no. You need a database. And a separate web-service. You also have to monitor your logging subsystem. And periodically update it, you also have to make sure that it is secure. And has enough resources. And everyone has access to it. And so on and so forth.
Of course, there are cloud providers just for logging. It might be a good idea to consider using them.
Logging is hard to manage
In case you are still using logging after all my previous arguments, you will find out that it requires a lot of discipline and tooling. There are several well-known problems:
Logging should be very strict about its format. Do you remember that we are probably going to store our logs in a NoSQL database? Our logs need to be indexable. You would probably end up using
structlogor a similar solution. In my opinion, this should be the defaultThe next thing to fight is levels. All developers will use their own ideas on what is critical and what's not. Unless you (as an architect) will write a clear policy that will cover most of the cases. You might also need to review it carefully. Otherwise, your logging database might blow up with useless data
-
Your logging usage should be consistent!
All people tend to write in their own style. There's a linter for that! It will enforce:
logger.info( 'Hello {world}', extra={'world': 'Earth'}, )Instead of:
logger.info( 'Hello {world}'.format(world='Earth'), )
And many other edge cases.
- Logging should be business-oriented.
I usually see people using logging with a minimal amount of useful information. For example, if you are logging an invalid current object state: it is not enough! You need to do more: you need to show how this object got into this invalid state. There are different approaches to this problem. Some use simple solutions like version history, some people use EventSourcing to compose their objects from changes. And some libraries log the entire execution context, logical steps that were taken, and changes made to the object. Like
dry-python/stories(docs on logging). And here's how the context looks like:
ApplyPromoCode.apply
find_category
find_promo_code
check_expiration
calculate_discount (errored: TypeError)
Context:
category_id = 1024 # Story argument
category = <example.Category> # Set by ApplyPromoCode.find_category
promo_code = <example.PromoCode> # Set by ApplyPromoCode.find_promo_code
See? It contains the full representation of what's happened and how to recreate this error. Not just some random state information here and there. And you don't even have to call logger yourself. It will handled for you. By the way, it even has a native Sentry integraion, which is better in my opinion.
- You should pay attention to what you log. There are GDPR rules on logging and specialized security audits for your logs. Common sense dictates that logging passwords, credit cards, emails, etc is not secure. But, sadly, common sense is not enough. This is a complex process to follow.
There are other problems to manage as well. My point here is to show that you will need senior people to work on that: by creating policies, writing down processes, and setting up your logging toolchain.
What to do instead?
Let's do a quick recap:
- Logging does not make much sense in monitoring and error tracking. Use better tools instead: like error and business monitorings with alerts
- Logging adds significant complexity to your architecture. And it requires more testing. Use architecture patterns that will make logging an explicit part of your contracts
- Logging is a whole infrastructure subsystem on its own. And quite a complex one. You will have to maintain it or to outsource this job to existing logging services
- Logging should be done right. And it is hard. You will have to use a lot of tooling. And you will have to mentor developers that are unaware of the problems we have just discussed
Is logging worth it? You should make an informed decision based on this knowledge and your project requirements. In my opinion, it is not required for the most of the regular web apps.
Please, get this right. I understand that logging can be really useful (and sometimes even the only source of useful information). Like for on-premise software, for example. Or for initial steps when your app is not fully functioning yet. It would be hard to understand what is going on without logging. I am fighting an "overlogging" culture. When logs are used just for no good reason. Because developers just do it without analyzing costs and tradeoffs.
Are you joining my side?


















