References - Website Scrapping
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. The web scraping software may directly access the World Wide Web using the Hypertext Transfer Protocol or a web browser. Wikipedia
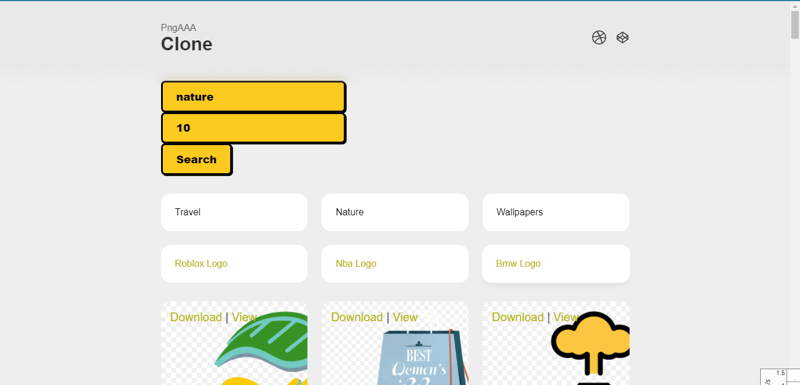
See this website https://www.pngaaa.com/ has no feature of API so that a user can not show the website's (https://www.pngaaa.com/) content on their website.
But after scrapping it and made a API for the users. Users can fetch the websites content on there website even using Pure JavaScript.
The different URLs will return you different results in JSON format. Just grab the JSON Using any Server Side or Client Side Language and Show on website.
Some API Uses are Given Below :-
If PngAAA.com have any worry or problem for this just contact me. I will remove it. This is Just made for educational purpose.
Web scraping itself is not illegal. As a matter of fact, web scraping – or web crawling, were historically associated with well-known search engines like Google or Bing. These search engines crawl sites and index the web. ... A great example when web scraping can be illegal is when you try to scrape nonpublic data.
Still -
If PngAAA.com have any worry or problem for this just contact me. I will remove it. This is Just made for educational purpose.
WebScrapper.get() will return you the content of the provided url in a String.
WebScrapper.gethtml() will return you the content of the provided url as Parsed DOM. ( Will get the html and Parse it as a DOM object . Will return you a #Document)
WebScrapper.getjson() will return you the content of the provided url as Parsed JSON.
To Get HTML/Text/Content of Any Website in a String.
varhtml=WebScrapper.get('https://webscrapperjs.sh20raj.repl.co/');//This will be return the HTML/Text inside the webpage in a String.console.log(html);
This will be return the HTML/Text inside the webpage in…