Introduction
The full-archive search endpoint lets you search the entire history of public Twitter data, which dates back to the first Tweet in March 2006. It works similarly to the recent search endpoint, used to search Tweets for events from the last 7 days; both endpoints return Tweets related to the topics you are interested in, based on your search query. Full-archive search helps address one of the most common use cases for academic researchers, who might use this for longitudinal studies, or analyzing a past topic or event. Note: v2 full-archive search is currently available only on the newly launched Academic Research product track. See the prerequisite section below to learn more.
This tutorial provides a step-by-step guide for researchers who wish to use this endpoint to search the complete history of public Twitter data. It will also demonstrate the different ways to build a dataset, such as by retrieving geo-tagged Tweets, and how to page through the available Tweets for a query.
Prerequisites
Currently this endpoint is only available as part of the Academic Research product track. In order to use this endpoint, you must apply for access. Learn more about the application and requirements for this track here.
Connect an app to the academic project
Once you are approved to use the Academic Research product track, you will see your Academic Project in the developer portal. From the Projects and Apps section, click on ‘Add App’ to connect your app to the Project.
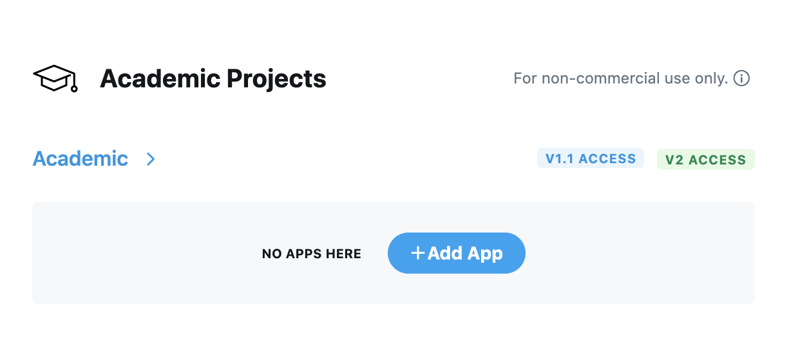
Then, you can either choose an existing app and connect it to your project (as shown below)
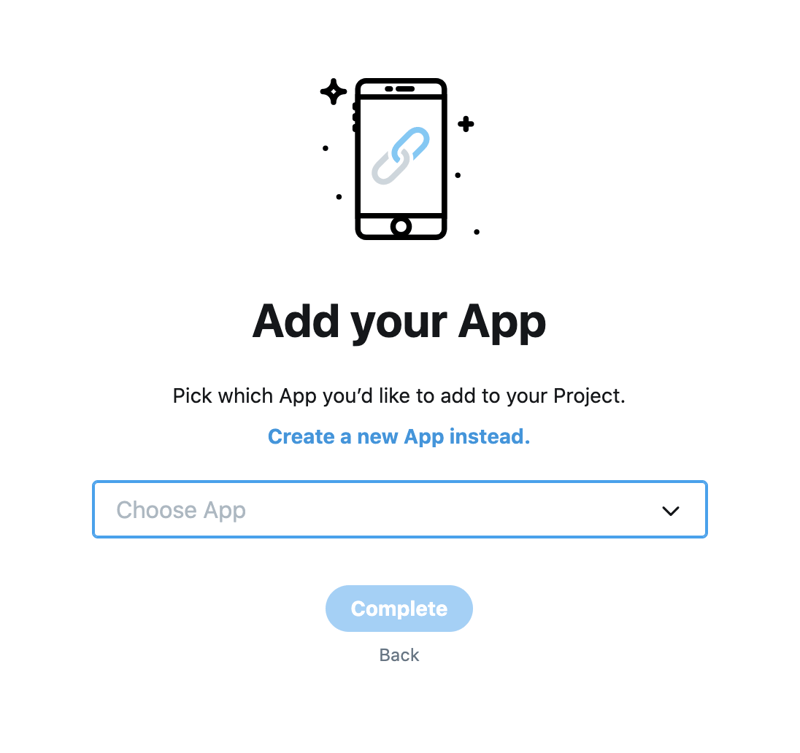
Or you can create a new app, give it a name and click complete, to connect a new app to your academic project.
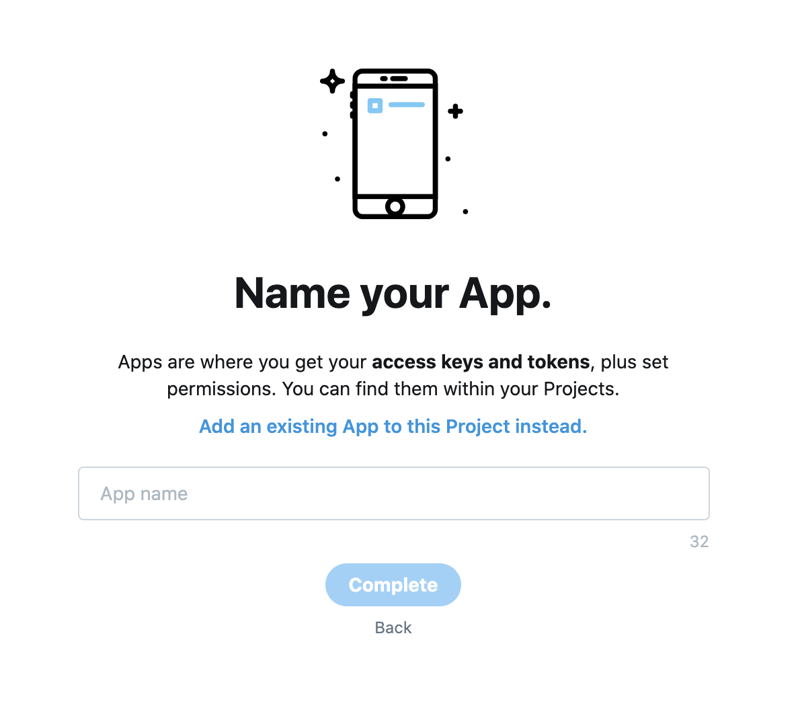
This will give you your API keys and Bearer token that you can then use to connect to the full-archive search endpoint.
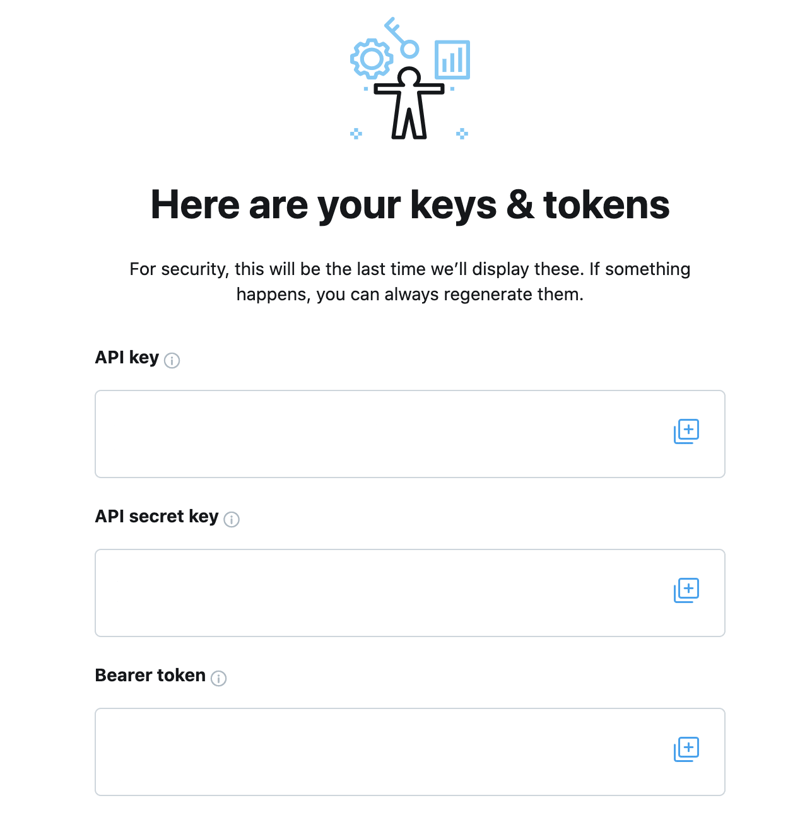
Note: The keys in the screenshot above are hidden, but in your own developer portal, you will be able to see the actual values for the API key, API secret key and Bearer token. Save these keys and the bearer token because you will need those for calling the full-archive search endpoint.
If you want to learn more or have questions, check our documentation about Projects and Apps here.
Connecting to the full-archive search endpoint
The cURL command below shows how you can get historical Tweets from @TwitterDev handle:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=from:twitterdev' --header 'Authorization: Bearer XXXXX'
Replace the XXXXX with your own bearer token and paste it in your terminal. You will see the response JSON.
By default, only 10 most recent Tweets will be returned. If you want more than 10 Tweets per request, you can use the max_results parameter and set it to a maximum of 500 Tweets per request, as shown below:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=from:twitterdev&max_results=500' --header 'Authorization: Bearer XXXXX'
Building queries
As you can see in the example calls above, using the query parameter, you can specify the data that you want to search for. As an example, if you wanted to get all Tweets that contain the word covid or the word coronavirus, you can use the OR operator within brackets, and your query can be (covid OR coronavirus) and thus your API call will be:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=(covid%20OR%20coronavirus)&max_results=500' --header 'Authorization: Bearer XXXXX'
Similarly, if you want all Tweets that contain the words covid19 that are not retweets, you can use the is:retweet operator with the logical NOT (represented by -), so your query can be covid19 -is:retweet and your API call will be:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=covid19%20-is:retweet&max_results=500' --header 'Authorization: Bearer XXXXX'
Check out this guide for a complete list of operators that are supported in the full-archive search endpoint.
Using the start_time and end_time parameters to get historical Tweets
When using the full-archive search endpoint, by default Tweets from the last 30 days will be returned. If you want to get Tweets that are older than 30 days, you can use the start_time and end_time parameters in your API call. These parameters must be in a valid RFC3339 date-time format e.g. 2020-12-21T13:00:00.00Z. Thus, if you want to get all Tweets from the Twitterdev account for the month of December 2020, your API call will be:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=from:Twitterdev&start_time=2020-12-01T00:00:00.00Z&end_time=2021-01-01T00:00:00.00Z' --header 'Authorization: Bearer XXXXX'
Getting geo-tagged historical Tweets
Geo-tagged Tweets are Tweets that have geographic information associated with them such as city, state, country etc.
Using has:geo operator
If you want to get Tweets that have geo data, you can use the has:geo operator. For example, the following cURL request will get only those Tweets from the Twitterdev handle that have geo data:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=from:twitterdev%20has:geo' --header 'Authorization: Bearer XXXXX'
Using place_country operator
Similarly, you can limit Tweets that have geo data, to a specific country, using the place_country operator. The cURL command below will get all Tweets from the TwitterDev handle from the United States:
curl --request GET 'https://api.twitter.com/2/tweets/search/all?query=from:twitterdev%20place_country:US' --header 'Authorization: Bearer XXXXX'
The country is specified above using the ISO alpha-2 character code. Valid ISO codes can be found here.
Getting more than 500 historical Tweets using the next_token
As mentioned above, by default you can only get up to 500 Tweets per request for a query to the full-archive search endpoint. If there are more than 500 Tweets available for your query, your json response will include a next_token which you can append to your API call in order to get the next available Tweets for this query. This next_token is available in the meta object of your JSON response, which looks something:
{
"newest_id": "12345678...",
"oldest_id": "12345678...",
"result_count": 500,
"next_token": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
}
Hence, to get the next available Tweets, use the next_token value from this meta object and use the value as the value for the next_token in your API call to the full-archive search endpoint as shown below (You will use your own bearer token and the value that you get for the next token for your previous API call)
curl --request GET 'https://api.twitter.com/2/tweets/search/all?max_results=500&query=covid&next_token=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' --header 'Authorization: Bearer XXXXX'
This way, you can keep checking if a next_token is available and if you have not reached your desired number of Tweets to be collected, you can keep calling the full-archive endpoint with the new next_token for each request. Keep in mind that full-archive search endpoint counts towards your total Tweet cap i.e. the number of Tweets per month that you can get from the Twitter API, so be mindful of your code logic when paging through the results in order to make sure you do not end up inadvertently exhausting your Tweet cap.
Below are some resources that can help you when using the full-archive search endpoint. We would love to hear your feedback. Reach out to us on @TwitterDev or on our community forums with questions about this endpoint.


















