Retrieval Augmented Generation (RAG) stands out as a significant innovation in Natural Language Processing (NLP), designed to enhance text generation by integrating the retrieval of relevant information from a vast database. Developed by researchers including Patrick Lewis and his team, RAG combines the power of large pre-trained language models with a retrieval system that pulls data from extensive sources like Wikipedia to inform its responses.
What is Retrieval Augmented Generation (RAG)?
RAG is a hybrid model that merges the capabilities of generative and retrieval-based models in NLP. This approach addresses the limitations of pre-trained language models, which, despite storing vast amounts of factual knowledge, often need help accessing and manipulating this information accurately for complex, knowledge-intensive tasks. RAG tackles this by using a "neural retriever" to fetch relevant information from a "dense vector index" of data sources like Wikipedia (or your data), which the model then uses to generate more accurate and contextually appropriate responses.
Significance of RAG in NLP
The development of RAG has marked a substantial improvement over traditional language models, particularly in tasks that require deep knowledge and factual accuracy:
Enhanced Text Generation: By incorporating external data during the generation process, RAG models produce not only diverse and specific text but also more factually accurate compared to traditional seq2seq models that rely only on their internal parameters.
State-of-the-art Performance: RAG was fine-tuned and evaluated on various NLP tasks in the original RAG paper, particularly excelling in open-domain question answering. It has set new benchmarks, outperforming traditional seq2seq and task-specific models that rely solely on extracting answers from texts.
Flexibility Across Tasks: Beyond question answering, RAG has shown promise in other complex tasks, like generating content for scenarios modeled after the game "Jeopardy," where precise and factual language is crucial. This adaptability makes it a powerful tool across various domains of NLP.
For further details, the foundational concepts and applications of RAG are thoroughly discussed in the work by Lewis et al. (2020), available through their NeurIPS paper and other publications ( Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, https://ar5iv.labs.arxiv.org/html/2005.11401)
Chunking
"Chunking" refers to dividing a large text corpus into smaller, manageable pieces or segments. Each chunk acts as a standalone unit of information that can be individually indexed and retrieved. For instance, in the development of RAG models, as Lewis et al. (2020) described, Wikipedia articles are split into disjoint 100-word chunks to create a total of around 21 million documents that serve as the retrieval database. This technique is crucial for enhancing the efficiency and accuracy of the retrieval process, which in turn impacts the overall performance of RAG models in various aspects, such as:
Improved Retrieval Efficiency: By organizing the text into smaller chunks, the retrieval component of the RAG model can more quickly and accurately identify relevant information. This is because smaller chunks reduce the computational load on the retrieval system, allowing for faster response times during the retrieval phase.
Enhanced Accuracy and Relevance: Chunking enables the RAG model to pinpoint the most relevant information more precisely. Since each chunk is a condensed representation of information, it is easier for the retrieval system to assess the relevance of each chunk to a given query, thus improving the likelihood of retrieving the most pertinent information.
Scalability and Manageability: Handling massive datasets becomes more feasible with chunking. It allows the system to manage and update the database efficiently, as each chunk can be individually indexed and maintained. This is particularly important for RAG models, which rely on up-to-date information to generate accurate and relevant outputs.
Balanced Information Distribution: Chunking ensures that the information is evenly distributed across the dataset, which helps maintain a balanced retrieval process. This uniform distribution prevents the retrieval model from being biased towards longer documents that might otherwise dominate the retrieval results if the corpus were not chunked.
Detailed Exploration of Chunking Strategies in RAG Systems
Chunking strategies are crucial for optimizing the efficiency of RAG systems in processing and understanding large texts. Let’s go deeper into three primary chunking strategies—fixed-size chunking, semantic chunking, and hybrid chunking—and how they can be applied effectively in RAG contexts.
-
Fixed-Size Chunking: Fixed-size chunking involves breaking down text into uniformly sized pieces based on a predefined number of characters, words, or tokens. This method is straightforward, making it a popular choice for initial data processing phases where quick data traversal is needed.
- Strategy: This technique involves dividing text into chunks of a predetermined size, such as every 100 words or every 500 characters.
- Implementation: Implementing fixed-size chunking can be straightforward using programming libraries that handle string operations, such as Python's basic string methods or more complex libraries like NLTK or spaCy for more structured data. For example,
def fixed_size_chunking(text, chunk_size=100):
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]
-
Advantages:
- Simplicity and predictability in implementation, which makes it easier to manage and index the chunks.
- High computational efficiency and ease of implementation.
-
Disadvantages:
- It may cut off important semantic boundaries, leading to retrieval of out-of-context information.
- Not flexible, as it does not adapt to the natural structure of the text.
When to Use: This strategy is ideal for scenarios where speed is more crucial than depth of context, such as during the preliminary analysis of large datasets where detailed semantic understanding is less critical.
2) Semantic Chunking: Semantic chunking segments texts based on meaningful content units, respecting natural language boundaries such as sentences, paragraphs, or thematic breaks.
Strategy: Unlike fixed-size chunking, this method splits text based on natural breaks in content, such as paragraphs, sections, or topics.
Implementation: Tools like spaCy or NLTK can identify natural breaks in the text, such as end-of-sentence punctuation, to segment texts semantically.
-
Advantages:
- Maintains the integrity of the information within each chunk, ensuring that all content within a chunk is contextually related.
- Enhances the relevance and accuracy of the retrieved data, which directly impacts the quality of generated responses.
-
Disadvantages:
- More complex to implement as it requires understanding of the text structure and content.
-
When to Use: Semantic chunking is particularly beneficial in content-sensitive applications like document summarization or legal document analysis, where understanding the full context and nuances of the language is essential.
- Hybrid Chunking: Hybrid chunking combines multiple chunking methods to leverage the benefits of both fixed-size and semantic chunking, optimizing both speed and accuracy.
Strategy: Combines multiple chunking methods to leverage the advantages of each. For example, a system might use fixed-length chunking for initial data processing and switch to semantic chunking when more precise retrieval is necessary.
Implementation: An initial pass might use fixed-size chunking for quick indexing, followed by semantic chunking during the retrieval phase to ensure contextual integrity. Integrating tools like spaCy for semantic analysis with custom scripts for fixed-size chunking can create a robust chunking strategy that adapts to various needs.
Advantages: Balances speed and contextual integrity by adapting the chunking method based on the task requirements.
Disadvantages: Can be more resource-intensive to implement and maintain.
-
When to Use:
- Enterprise Systems: In customer service chatbots, hybrid chunking can quickly retrieve customer query-related information while ensuring the responses are contextually appropriate and semantically rich.
- Academic Research: Hybrid chunking is used in research to handle diverse data types, from structured scientific articles to informal interviews, ensuring detailed analysis and relevant data retrieval.
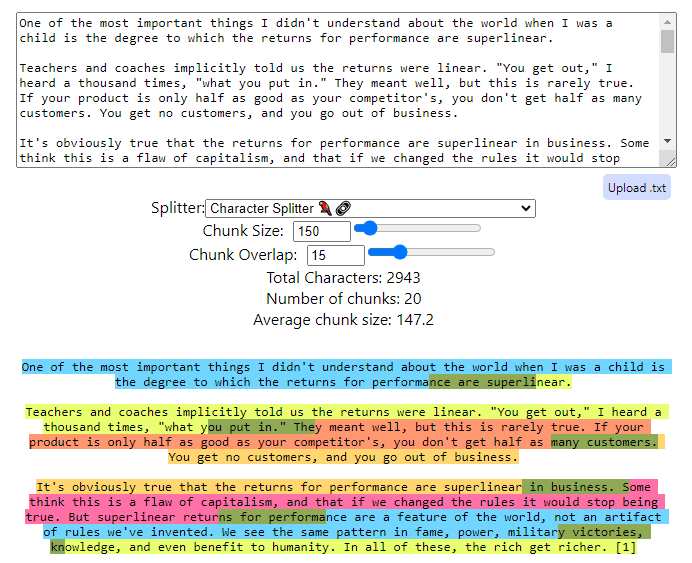
Here’s an example of Chunking using ChunkViz (https://chunkviz.up.railway.app/)
In the example given, Chunk size refers to the quantity of text (measured in terms of characters, words, or sentences) that makes up a single unit or "chunk" during text processing. The choice of chunk size is crucial because it determines how much information is handled at once during tasks such as text analysis, vectorization, or in systems like RAG.
Smaller Chunk Sizes: These are typically used when focusing on fine-grained analysis or when the text's detailed aspects are crucial. For instance, smaller chunks might be used in sentiment analysis where understanding specific phrases or sentences is essential.
Larger Chunk Sizes: These are suitable for capturing broader context or when the interplay between different text parts is essential, such as document summarization or topic detection. Larger chunks help preserve the narrative flow or thematic elements of the text, which might need fixing with finer chunking.
The selection of chunk size often depends on the balance between computational efficiency and the need for contextual accuracy. Smaller chunks can be processed faster but might lack context, while larger chunks provide more context but can be computationally heavier to process.
Chunk overlap allows chunks to share some standard text with adjacent chunks. This technique ensures that no critical information is lost at the boundaries between chunks, especially in cases where the cut-off point might split important semantic or syntactic structures.
- Role of Overlap: Overlap helps smooth the transitions between chunks, ensuring continuity of context, which is particularly useful in tasks like language modeling or when preparing data for training neural networks. For instance, if a sentence is cut off at the end of one chunk, starting the next chunk with the end of that sentence can provide continuity and context.
Using chunk overlap can significantly enhance the quality of the analysis by reducing the risk of context loss and improving the coherence of the output in NLP applications. However, it also increases the computational load since more text is processed multiple times, and this trade-off needs to be managed based on the specific requirements of the task.
In RAG systems, the choice of chunking strategy can significantly impact the effectiveness of the retrieval process and, by extension, the quality of the generated outputs. Whether through fixed-size, semantic, or hybrid chunking, the goal remains to optimize how information is segmented, indexed, and retrieved to support efficient and accurate natural language generation. The strategic implementation of chunking can be the difference between a performant system and one that struggles with latency and relevance, highlighting its critical role in the architecture of advanced NLP solutions.
Chunking and Vectorization in Text Retrieval
Chunking significantly influences the effectiveness of vectorization in text retrieval systems. Proper chunking ensures that text vectors encapsulate the necessary semantic information, which enhances retrieval accuracy and efficiency. For instance, chunking strategies that align with the natural structure of the text, such as those that consider sentences or paragraphs, help maintain the integrity of the information when converted into vector form. This structured approach ensures that the vectors generated reflect actual content relevance, facilitating more precise retrieval in systems like RAG.
Tools and Technologies for Effective Vectorization
Effective vectorization of text heavily relies on the tools and embedding models used. Popular models include Word2Vec and GloVe for word-level embeddings, while BERT and GPT offer capabilities at sentence or paragraph levels, accommodating larger chunks of text. These models are adept at capturing the nuanced semantic relationships within the text, making them highly suitable for sophisticated text retrieval systems. The choice of the model should align with the granularity of the chunking strategy to optimize performance. For example, sentence transformers are particularly effective when used with semantic chunking, as they are designed to handle and process sentence-level information efficiently.
Aligning Chunking Strategy with Vectorization for Optimal Performance
Aligning your chunking strategy with vectorization involves several key considerations:
Chunk Size and Model Capacity: It's crucial to match the chunk size with the capacity of the vectorization model. Optimized for shorter texts, models like BERT may require smaller, more concise chunks to operate effectively.
Consistency and Overlap: Ensuring consistency in chunk content and utilizing overlapping chunks can help maintain context between chunks, reducing the risk of losing critical information at the boundaries.
Iterative Refinement: Continuously refining the chunking and vectorization approaches based on system performance feedback is essential. This might involve adjusting chunk sizes or the vectorization model based on the system's retrieval accuracy and response time.
Implementing Chunking in RAG Pipelines
Implementing effective chunking in RAG systems involves a nuanced understanding of how chunking interacts with other components, such as the retriever and generator. This interaction is pivotal for enhancing the efficiency and accuracy of the RAG system.
Chunking and the Retriever: The retriever's function is to identify and fetch the most relevant chunks of text based on the user query. Effective chunking strategies break down enormous datasets into manageable, coherent pieces that can be easily indexed and retrieved. For instance, chunking by document elements like titles or sections rather than mere token size can significantly improve the retriever's ability to pull contextually relevant information. This method ensures that each chunk encapsulates complete and standalone information, facilitating more accurate retrieval and reducing the retrieval of irrelevant information.
Chunking and the Generator: The generator uses this information to construct responses once the relevant chunks are retrieved. The quality and granularity of chunking directly influence the generator's output. Well-defined chunks ensure the generator has all the necessary context, which helps produce coherent and contextually rich responses. If chunks are too granular or poorly defined, it may lead to responses that are out of context or lack continuity.
Tools and Technologies for Building and Testing Chunking Strategies
Several tools and platforms facilitate the development and testing of chunking strategies within RAG systems:
LangChain and LlamaIndex: These tools provide various chunking strategies, including dynamic chunk sizing and overlapping, which are crucial for maintaining contextual continuity between chunks. They allow for the customization of chunk sizes and overlap based on the application's specific needs, which can be tailored to optimize both retrieval and generation processes in RAG systems.
Preprocessing pipeline APIs by Unstructured: These pipelines enhance RAG performance by employing sophisticated document understanding techniques, such as chunking by document element. This method is particularly effective for complex document types with varied structures, as it ensures that only relevant data is considered for retrieval and generation, enhancing both the accuracy and efficiency of the RAG system.
Zilliz Cloud: Zilliz Cloud includes a capability called Pipelines that streamlines the conversion of unstructured data into vector embeddings, which are then stored in the Zilliz Cloud vector database for efficient indexing and retrieval. There are features that allow you to choose or customize the splitter that is included. By default, Zilliz Cloud Pipelines uses "\n\n", "\n", " ", "" as separators. You can also choose to split the document by sentences (use ".", "" as separators ), paragraphs (use "\n\n", "" as separators), lines (use "\n", "" as separators), or a list of customized strings.
Incorporating these tools into the RAG pipeline allows developers to experiment with different chunking strategies and directly observe their impact on system performance. This experimentation can significantly improve how information is retrieved and processed, ultimately enhancing the overall effectiveness of the RAG system.
Performance Optimization in RAG Systems Through Chunking Strategies
Optimizing RAG systems involves carefully monitoring and evaluating how different chunking strategies impact performance. This optimization ensures that the system not only retrieves relevant information quickly but also generates coherent and contextually appropriate responses.
Monitoring and Evaluating the Impact of Different Chunking Strategies
- Setting Performance Benchmarks: Before modifying chunking strategies, it's crucial to establish baseline performance metrics. This might include metrics like response time, information retrieval accuracy, and the generated text's coherence.
2) Experimentation: Implement different chunking strategies—such as fixed-size, semantic, and dynamic chunking—and measure how each impacts performance. This experimental phase should be controlled and systematic to isolate the effects of chunking from other variables.
- Continuous Monitoring: Use logging and monitoring tools to track performance over time. This ongoing data collection is vital for understanding long-term trends and the stability of improvements under different operational conditions.
Metrics and Tools for Assessing Chunking Effectiveness
Metrics:
Precision and Recall: These metrics are critical for evaluating the accuracy and completeness of the information retrieved by the RAG system.
Response Time: Measures the time taken from receiving a query to providing an answer, indicating the efficiency of the retrieval process.
Consistency and Coherence: The logical flow and relevance of text generated based on the chunked inputs are crucial for assessing chunking effectiveness in generative tasks.
Tools:
Analytics Dashboards: Tools like Grafana or Kibana can be integrated to visualize performance metrics in real-time.
Profiling Software: Profiling tools specific to machine learning workflows, such as Profiler or TensorBoard, can help identify bottlenecks at the chunking stage.
Strategies for Tuning and Refining Chunking Parameters Based on Performance Data
- Data-Driven Adjustments: Use the collected performance data to decide which chunking parameters (e.g., size, overlap) to adjust. For example, if larger chunks are slowing down the system but increasing accuracy, a balance needs to be found that optimizes both aspects.
2) A/B Testing: Conduct A/B testing using different chunking strategies to directly compare their impact on system performance. This approach allows for side-by-side comparisons and more confident decision-making.
- Feedback Loops: Implement a feedback system where the outputs of the RAG are evaluated either by users or through automated systems to provide continuous feedback on the quality of the generated content. This feedback can be used to fine-tune chunking parameters dynamically.
4) Machine Learning Optimization Algorithms: Utilize machine learning techniques such as reinforcement learning or genetic algorithms to find optimal chunking configurations based on performance metrics automatically.
By carefully monitoring, evaluating, and continuously refining the chunking strategies in RAG systems, developers can significantly enhance their systems' efficiency and effectiveness.
Case Studies on Successful RAG Implementations with Innovative Chunking Strategies
Case Study 1 - Dynamic Windowed Summarization: One notable example of a successful RAG implementation involved an additive preprocessing technique called windowed summarization. This approach enriched text chunks with summaries of adjacent chunks to provide a broader context. This method allowed the system to adjust the "window size" dynamically, exploring different scopes of context, which enhanced the understanding of each chunk. The enriched context improved the quality of responses by making them more relevant and contextually nuanced. This case highlighted the benefits of context-enriched chunking in a RAG setup, where the retrieval component could leverage broader contextual cues to enhance answer quality and relevance (Optimizing Retrieval-Augmented Generation with Advanced Chunking Techniques: A Comparative Study: https://antematter.io/blogs/optimizing-rag-advanced-chunking-techniques-study).
Case Study 2 - Advanced Semantic Chunking: Advanced Semantic Chunking: Another successful implementation of a successful RAG implementation involves advanced semantic chunking techniques to enhance retrieval performance. By dividing documents into semantically coherent chunks rather than merely based on size or token count, the system significantly improved its ability to retrieve relevant information. This strategy ensured each chunk maintained its contextual integrity, leading to more accurate and coherent generation outputs. Implementing such chunking techniques required a deep understanding of both the content structure and the specific demands of the retrieval and generation processes involved in the RAG system (Mastering RAG: Advanced Chunking Techniques for LLM Applications: https://www.rungalileo.io/blog/mastering-rag-advanced-chunking-techniques-for-llm-applications ).
Conclusion: The Strategic Significance of Chunking in RAG Systems
Throughout this guide, we've explored various facets of chunking strategies within Retrieval-Augmented Generation (RAG) systems. From understanding the basics of chunking to diving into advanced techniques and real-world applications, the discussion has emphasized the crucial role chunking plays in optimizing the performance of RAG systems.
Recap of Key Points
Basic Principles: Chunking refers to breaking down large text datasets into manageable pieces that improve the efficiency of information retrieval and text generation processes.
Chunking Strategies: Various chunking strategies like fixed-size, semantic, and dynamic chunking can be implemented, based on the use case, its advantages, scenarios of best use and disadvantages.
Impact on RAG Systems: The interaction between chunking and other RAG components such as the retriever and generator should be assessed, as different chunking approaches can influence the overall system performance.
Tools and Metrics: The tools and metrics that can be used to monitor and evaluate the effectiveness of chunking strategies are critical for ongoing optimization efforts.
Real-World Case Studies: Examples from successful implementations illustrated how innovative chunking strategies can lead to significant improvements in RAG systems.
Final Thoughts on Choosing the Right Chunking Strategy
Choosing the appropriate chunking strategy is paramount in enhancing the functionality and efficiency of RAG systems. The right strategy ensures that the system not only retrieves the most relevant information but also generates coherent and contextually rich responses. As seen in the discussed case studies, the impact of well-implemented chunking strategies on RAG performance can be profound, influencing both the precision of information retrieval and the quality of content generation.
Further Reading and Resources on RAG and Chunking
For those looking to deepen their understanding of Retrieval-Augmented Generation (RAG) and chunking strategies, there are several resources that provide comprehensive insights:
-
Books and Articles:
- For a foundational understanding, the original paper by Lewis et al. on RAG is essential. It offers in-depth explanations of the mechanisms and applications of RAG in knowledge-intensive NLP tasks.
- "Mastering RAG: Advanced Chunking Techniques for LLM Applications" on Galileo provides a deeper dive into various chunking strategies and their impact on RAG system performance, emphasizing the integration of LLMs for enhanced retrieval and generation processes.
-
Communities:
- Joining AI and NLP communities such as those found on Stack Overflow, Reddit (r/MachineLearning), or Towards AI can provide ongoing support and discussion forums. These platforms allow practitioners to share insights, ask questions, and find solutions related to RAG and chunking (https://towardsai.net/p/machine-learning/advanced-rag-05-exploring-semantic-chunking)
Each of these resources can offer valuable knowledge and practical tips for implementing effective RAG systems and optimizing them with advanced chunking techniques. Engaging with these materials and communities will not only enhance your understanding but also keep you at the forefront of developments in this rapidly evolving field.
References
From Fixed-Size to NLP Chunking - A Deep Dive into Text Chunking Techniques (https://safjan.com/from-fixed-size-to-nlp-chunking-a-deep-dive-into-text-chunking-techniques/)
Retrieval-Augmented Generation with Azure AI Document Intelligence (https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/concept-retrieval-augmented-generation?view=doc-intel-4.0.0)
Unstructured’s Preprocessing Pipelines Enable Enhanced RAG Performance (https://unstructured.io/blog/unstructured-s-preprocessing-pipelines-enable-enhanced-rag-performance)


















