 on[ Unsplash](https://unsplash.com/s/photos/chaos?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)](https://res.cloudinary.com/practicaldev/image/fetch/s--XrOxOpEA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/3200/0%2ACqGpxPfdlWhgIHm9)
During Summer Hackdays 2022, I worked on a project called “Zeebe chaos” (zbchaos), a fault injection CLI tool. This allows us engineers to more easily run chaos experiments against Zeebe, build up confidence in the system’s capabilities, and discover potential weaknesses.
Requirements
To understand this blog post, it is useful to have a certain understanding of Kubernetes and Zeebe itself.
Summer Hackdays:
Hackdays are a regular event at Camunda, where people from different departments (engineering, consulting, DevRel, etc.) work together on new ideas, pet projects, and more.
Often, the results are quite impressive and are also presented in the following CamundaCon. For example, check out the agenda of this year’s CamundaCon 2022.
Check out previous Summer Hackdays here:
Zeebe chaos CLI
Working on the Zeebe project is not only about engineering a distributed system or a process engine, it is also about testing, benchmarking, and experimenting with our capabilities.
We run regular chaos experiments against Zeebe to build up confidence in our system and to determine whether we have weaknesses in certain areas. In the past, we have written many bash scripts to inject faults (chaos). We wanted to replace them with better tooling: a new CLI. This allows us to make it more maintainable, but also lowers the barrier for others to experiment with the system.
The CLI targets Kubernetes, as this is our recommended environment for Camunda Platform 8 Self-Managed, and the environment our own SaaS offering runs on.
The tool builds upon our existing Helm charts, which are normally used to deploy Zeebe within Kubernetes.
Requirements
To use the CLI you need to have access to a Kubernetes cluster, and have our Camunda Platform 8 Helm charts deployed. Additionally, feel free to try out Camunda Platform 8 Self-Managed.
Chaos Engineering:
You might be wondering why we need this fault injection CLI tool or what this “chaos” stands for. It comes from chaos engineering, a practice we introduced back in 2019 to the Zeebe Project.
Chaos Engineering was defined by the Principles of Chaos. It should help to build confidence in the system's capabilities and find potential weaknesses through regular chaos experiments. We define and execute such experiments regularly.
Chaos experiments
As mentioned, we regularly write and run new chaos experiments to build up confidence in our system and undercover weaknesses. The first thing you have to do for your chaos experiment is to define a hypothesis that you want to prove. For example, processing should still be possible after a node goes down. Based on the hypothesis, you know what kind of property or steady state you want to verify before and after injecting faults into the system.
A chaos experiment consists of three phases:
- Verify the steady state.
- Inject chaos.
- Verify the steady state.
For each of these phases, the zbchaos CLI provides certain features outlined below.
Verify steady state
In the steady state phase, we want to verify certain properties of the system, like invariants, etc.
One of the first things we typically want to check is the Zeebe topology. With zbchaos you can run:
$ zbchaos topology
0 |LEADER (HEALTHY) |FOLLOWER (HEALTHY) |LEADER (HEALTHY)
1 |FOLLOWER (HEALTHY) |LEADER (HEALTHY) |FOLLOWER (HEALTHY)
2 |FOLLOWER (HEALTHY) |FOLLOWER (HEALTHY) |FOLLOWER (HEALTHY)
Zbchaos will do all the necessary magic for you. Finding a Zeebe gateway, do a port-forward, request the topology, and print it in a compact format. This makes the chaos engineers’ life much easier.
Another basic check is verifying the readiness of all deployed Zeebe components. To achieve this, we can use:
$ zbchaos verify readiness
All Zeebe nodes are running.
This verifies the Zeebe Broker Pod status and the status of the Zeebe Gateway deployment status. If one of these is not ready yet, it will loop and not return before they are ready. This is beneficial in automation scripts.
After you have verified the general health and readiness of the system, you also need to verify whether the system is working functionally. This is also called “verifying the steady state.” This can be achieved by:
$ zbchaos verify steady-state — partitionId 2
This command checks that a process model can be deployed and a process instance can be started for the specified partition. As you cannot influence the partition for new process instances, process instances are started in a loop until that partition is hit. If you don’t specify the partitionId, partition one is used.
Inject chaos
After we verify our steady state we want to inject faults or chaos into our system, and afterward check again our steady state. The zbchaos CLI already provides several possibilities to inject faults outlined below.
Before we step through how we can inject failures, we need to understand what kind of components a Zeebe cluster consists of and what the architecture looks like.
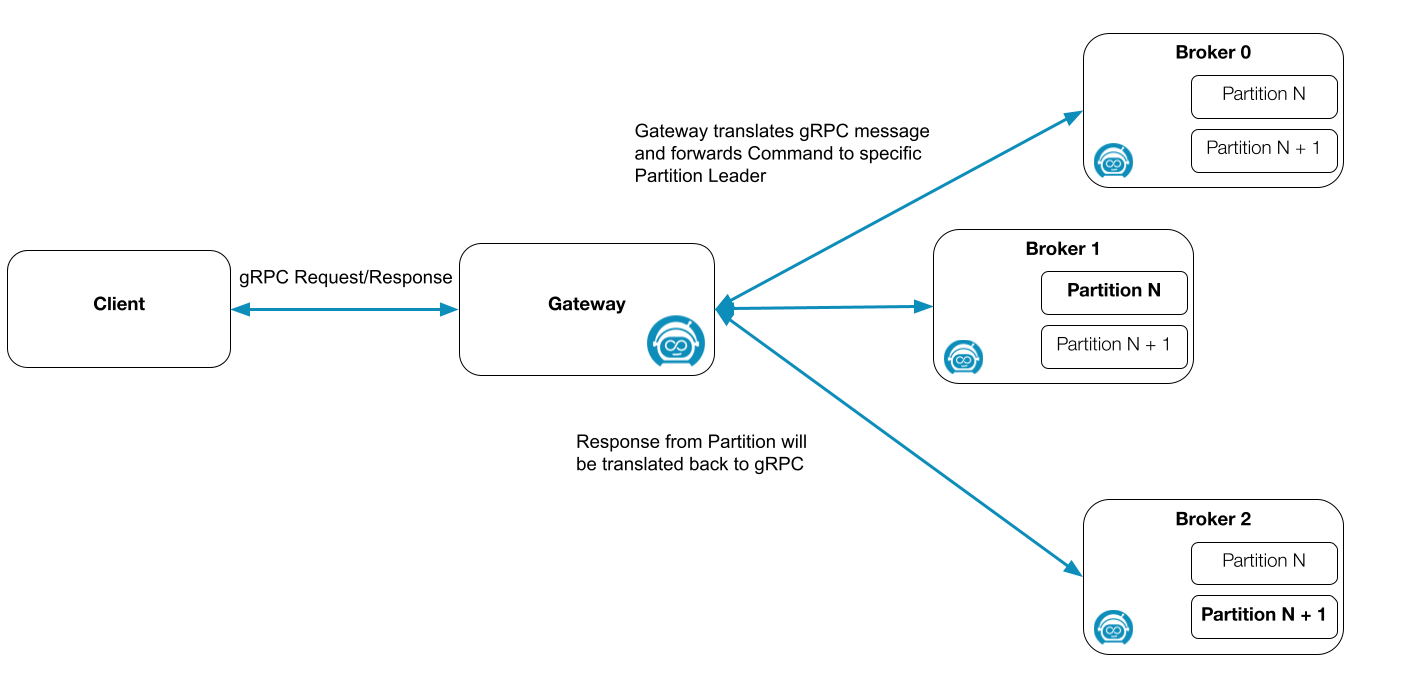](https://res.cloudinary.com/practicaldev/image/fetch/s--YwjJZWwX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/2810/0%2AbzpYhhsYYz4ATUpL)
We have two types of nodes: the broker, and the gateway.
A broker is a node that does the processing work. It can participate in one or more Zeebe partitions (internally each partition is a raft group, which can consist of one or more nodes). A broker can have different roles for each partition (Leader, Follower, etc.)
For more details about the replication, check our documentation and the raft documentation.
The Zeebe gateway is the contact point to the Zeebe cluster to which clients connect. Clients send commands to the gateway and the gateway is in charge of distributing the commands to the partition leaders. This depends on the command type of course. For more details, check out the documentation.
By default, the Zeebe gateways are replicated as if Camunda Platform 8 Self-Managed was installed via our Helm charts, which makes it interesting to also experiment with the gateways.
Shutdown nodes
With zbchaos we can shutdown brokers (gracefully and non-gracefully) which have a specific role and take part in a specific partition. This is quite useful in experimenting since we often want to terminate or restart brokers based on the participation and role (e.g. terminate the Leader of partition X or restart all followers of partition Y.)
Graceful
A graceful restart can be initiated like this:
$ zbchaos restart -h
Restarts a Zeebe broker with a certain role and given partition.
Usage:
zbchaos restart [flags]
Flags:
-h, --help help for restart
--partitionId int Specify the id of the partition (default 1)
--role string Specify the partition role [LEADER, FOLLOWER, INACTIVE] (default “LEADER”)
Global Flags:
-v, — verbose verbose output
This sends a Kubernetes delete command to the pod, which takes part of the specific partition and has the specific role. This is based on the current Zeebe topology, provided by the Zeebe gateway. All of this is handled by the zbchaos toolkit. The chaos engineer doesn’t need to find this information manually.
Non-graceful
Similar to the graceful restart is the termination of the broker. It will send a delete to the specific Kubernetes Pod, and will set the **–gracePeriod **to zero.
$ zbchaos terminate -h
Terminates a Zeebe broker with a certain role and given partition.
Usage:
zbchaos terminate [flags]
zbchaos terminate [command]
Available Commands:
gateway Terminates a Zeebe gateway
Flags:
-h, --help help for terminate
--nodeId int Specify the nodeId of the Broker (default -1)
--partitionId int Specify the id of the partition (default 1)
--role string Specify the partition role [LEADER, FOLLOWER] (default “LEADER”)
Global Flags:
-v, --verbose verbose output
Use “zbchaos terminate [command] --help” for more information about a command.
Gateway
Both commands above target the Zeebe brokers. Sometimes, it is also interesting to target the Zeebe gateway. For that, we can just append the gateway subcommand to the restart or terminate command.
Disconnect brokers
It is not only interesting to experiment with graceful and non-graceful restarts, but it is also interesting to experiment with network issues. This kind of fault undercovers other interesting weaknesses (bugs).
With the zbchaos CLI, it is possible to disconnect different brokers. We can specify at which partition they participate and what kind of role they have. These network partitions can also be set up in one direction if the –one-direction flag is used.
$ zbchaos disconnect -h
Disconnect Zeebe nodes, uses sub-commands to disconnect leaders, followers, etc.
Usage:
zbchaos disconnect [command]
Available Commands:
brokers Disconnect Zeebe Brokers
Flags:
-h, — help help for disconnect
Global Flags:
-v, — verbose verbose output
Use “zbchaos disconnect [command] — help” for more information about a command.
[zell ~/ cluster: zeebe-cluster ns:zell-chaos]$ zbchaos disconnect brokers -h
Disconnect Zeebe Brokers with a given partition and role.
Usage:
zbchaos disconnect brokers [flags]
Flags:
— broker1NodeId int Specify the nodeId of the first Broker (default -1)
— broker1PartitionId int Specify the partition id of the first Broker (default 1)
— broker1Role string Specify the partition role [LEADER, FOLLOWER] of the first Broker (default “LEADER”)
— broker2NodeId int Specify the nodeId of the second Broker (default -1)
— broker2PartitionId int Specify the partition id of the second Broker (default 2)
— broker2Role string Specify the partition role [LEADER, FOLLOWER] of the second Broker (default “LEADER”)
-h, — help help for brokers
— one-direction Specify whether the network partition should be setup only in one direction (asymmetric)
Global Flags:
-v, — verbose verbose output
The network partition will be established with ip route tables, which are installed on the specific broker pods.
Right now this is only supported for the brokers, but hopefully, we will add support for the gateways soon as well.
To connect the brokers again, the following can be used:
$ zbchaos connect brokers
This removes the ip routes on all pods again.
Other features
All the described commands support a verbose flag, which allows the user to determine what kind of action is done, how it connects to the cluster, and more.
For all of the commands, a bash-completion can be generated via zbchaos completion, which is very handy.
Outcome and future
In general, I was quite happy with the outcome of Summer Hackdays 2022, and it was a lot of fun to build and use this tool already. I was able to finally spend some more time writing go code and especially a go CLI. I learned to use the Kubernetes go-client and how to write go tests with fakes for the Kubernetes API, which was quite interesting. You can take a look at the tests here.
We plan to extend the CLI in the future and use it in our upcoming experiments.
For example, I recently did a new chaos day, a day I use to run new experiments, and wrote a post about it. In this article, I extended the CLI, with features like sending messages to certain partitions.
At some point, we want to use the functionality within our automated chaos experiments as Zeebe workers and replace our old bash scripts.
Thanks to Christina Ausley and Bernd Ruecker for reviewing this post :)


















