In this brief post, I will demonstrate how you can repave/re-image your CockroachDB cluster VMs while still being online and without much data movement and replication.
The process is simple. For each node in the cluster:
- Stop VM.
- Detach data disks.
- Upgrade/replace VM image with your new image (or use a new VM pre-configured with CockroachDB).
- Attach disks to re-imaged/repaved VM (or the new VM).
- Start VM and CockroachDB process.
- Wait few minutes for cluster to adjust.
Demo
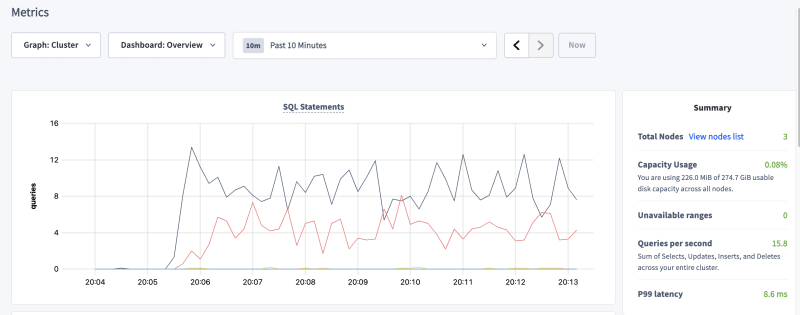
I created a basic 3 nodes cluster on AWS with 1 attached EBS volume each. I started some sample load, and let it run for about 10 minutes.
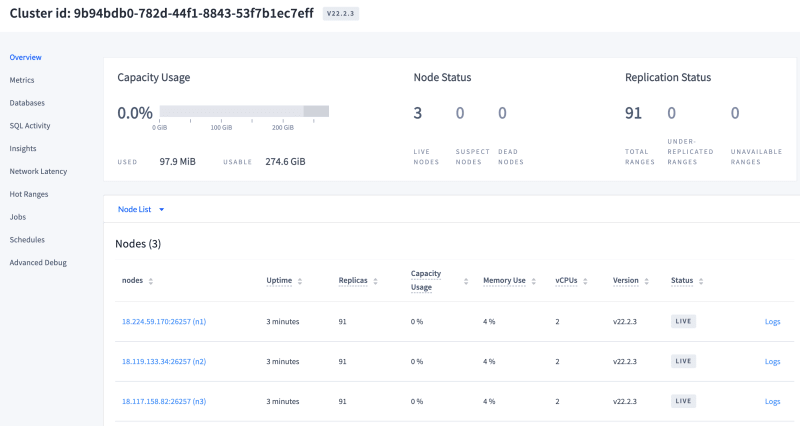
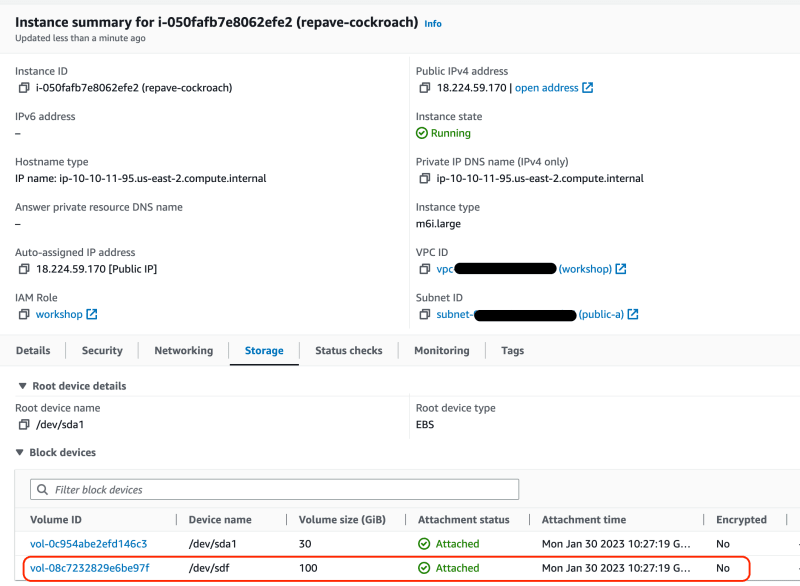
Here is the view of one of these nodes, see the mounted disk at /dev/sdf? That's an EBS volume.
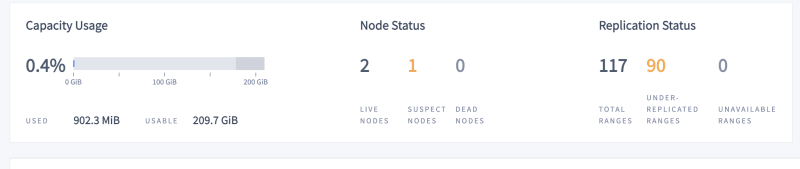
I then reached out to the AWS Console and stopped a node, n3. CockroachDB complains about a suspect/dead node, and shows that some ranges are under-replicated.
Once the VM was stopped, I detached the EBS volume (see green banner)...
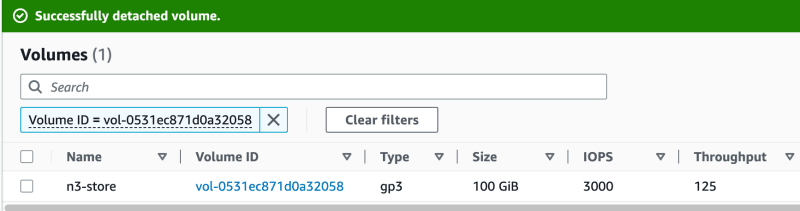
...and attached it to a new and up and running VM.
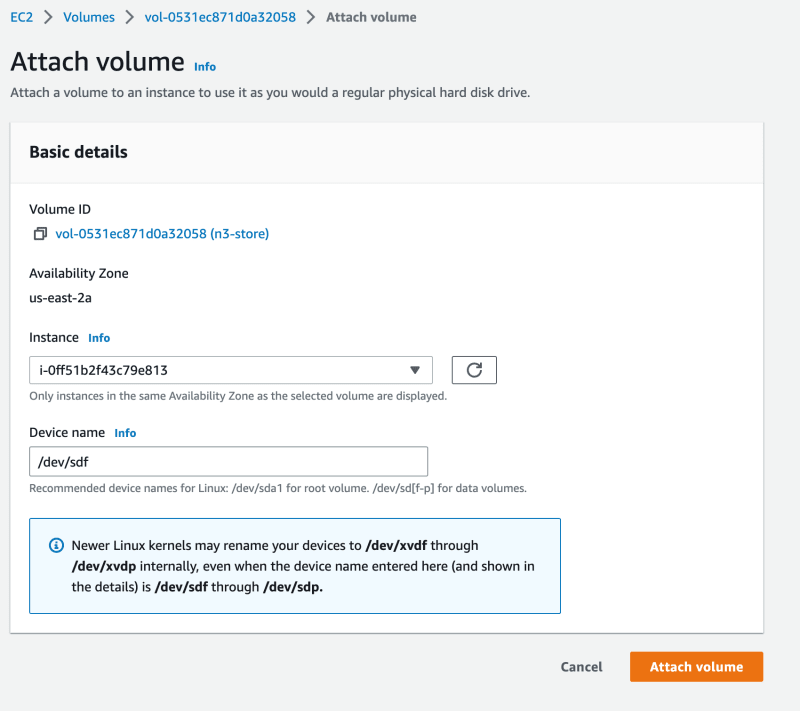
I then ssh'ed into the new VM, and started the CockroachDB process. If you are repaving into a new VM, make sure the TLS certificates for inter-node communication are correctly installed.
Immediately, the node connects to the cluster and complains about under-replicated ranges are gone.
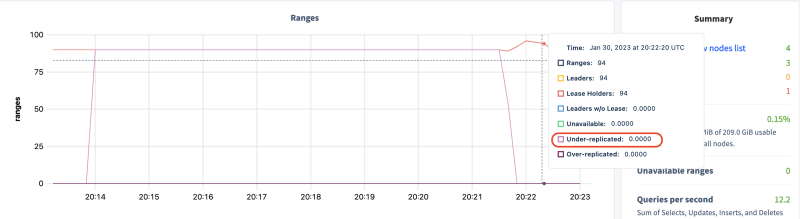
That's it! Confirm under-replicated ranges are gone, then wash, rinse and repeat for every other node!
While, as you can see from the charts, the whole process took about 5 minutes, this can be greatly simplified and improved upon by using a dev-ops automation tool such as Ansible.
Cleaning up the old nodes
Once repaved, we can remove the notion of the old, repaved node n3 from the cluster using the decommission command.
root@ip-10-10-11-95:/home/ubuntu# cockroach node status --certs-dir /var/lib/cockroach/certs/
id | address | sql_address | build | started_at | updated_at | locality | is_available | is_live
-----+---------------------+---------------------+---------+--------------------------------------+--------------------------------------+-------------------------+--------------+----------
1 | 18.224.59.170:26257 | 18.224.59.170:26257 | v22.2.3 | 2023-01-30 20:03:59.66018 +0000 UTC | 2023-01-30 20:26:07.183524 +0000 UTC | region=us-east-2,zone=a | true | true
2 | 18.119.133.34:26257 | 18.119.133.34:26257 | v22.2.3 | 2023-01-30 20:04:00.13035 +0000 UTC | 2023-01-30 20:26:07.642953 +0000 UTC | region=us-east-2,zone=a | true | true
3 | 18.117.158.82:26257 | 18.117.158.82:26257 | v22.2.3 | 2023-01-30 20:04:00.944523 +0000 UTC | 2023-01-30 20:13:52.332716 +0000 UTC | region=us-east-2,zone=a | false | false
4 | 3.141.0.11:26257 | 3.141.0.11:26257 | v22.2.3 | 2023-01-30 20:21:37.594691 +0000 UTC | 2023-01-30 20:26:07.609098 +0000 UTC | region=us-east-2,zone=a | true | true
(4 rows)
root@ip-10-10-11-95:/home/ubuntu#
root@ip-10-10-11-95:/home/ubuntu#
root@ip-10-10-11-95:/home/ubuntu# cockroach node decommission 3 --certs-dir /var/lib/cockroach/certs/
id | is_live | replicas | is_decommissioning | membership | is_draining
-----+---------+----------+--------------------+-----------------+--------------
3 | false | 0 | true | decommissioning | true
(1 row)
No more data reported on target nodes. Please verify cluster health before removing the nodes.

The cluster is now updated and as good as new.


















