
This blog will introduce you to some core concepts and building blocks of working with the official Elasticsearch Python client. We will cover connecting to the client, creating and populating an index, adding a custom mapping, and running some initial simple queries.
But wait, what is Elasticsearch? Elastic is a platform offering search-powered solutions - from the Elasticsearch engine to observability and dashboarding solutions like Kibaba, security software, and much more.
Elasticsearch is based on Lucene and is used by various companies and developers across the world to build custom search solutions.
Getting connected
You can deploy Elastic locally or in your cloud of choice.
In this example, I'm connecting to Elastic Cloud with an API Key (the recommended security option), but there are a lot of other authentication options you can see here.
Elasticsearch can be accessed via API calls through various interfaces, from the Dev Console available in the cloud browser to various language models, or tools like Postman that can send in requests.
The Python client is a high-level client that allows us to interact with Elasticsearch from our IDE and add functionalities like search to our projects.
You can install the client in your environment: ! pip install elasticsearch and start coding.
The docs for the client are available here.
Using your credentials you can create an instance of the Elasticsearch client that will communicate with your (in this case cloud) deployment.
from getpass import getpass # For securely getting user input
from elasticsearch import Elasticsearch
# Prompt the user to enter their Elastic Cloud ID and API Key securely
ELASTIC_CLOUD_ID = getpass("Elastic Cloud ID: ")
ELASTIC_API_KEY = getpass("Elastic API Key: ")
# Create an Elasticsearch client using the provided credentials
client = Elasticsearch(
cloud_id=ELASTIC_CLOUD_ID, # cloud id can be found under deployment management
api_key=ELASTIC_API_KEY
) # API keys can be generated under management / security
Creating an Index
Next up we want to add data.
Elasticsearch indexes data in the form of documents (that look like dictionaries or JSON files). Think of it as a collection of properties and values.
To make this example fun, I'll be using a dataset of Harry Potter Characters from Kaggle.
Then each entry in our dataset (or document in our index) will represent one character. A simplified version of such a document would look like:
document = {
"Name" : "Iulia",
"Eye colour": "hazel",
"House": "Slytherin",
"Loyalty": "Order of the Phoenix",
"Patronus": "Basset Hound Puppy"
}
So let's create this index! We can first create a mapping - which tells Elasticsearch what kind of features it can expect from the incoming data we want to add, to ensure everything is stored in the right format. Read more about the various field types here.
Custom Mapping
index = "hp_characters"
settings = {}
mappings = {
"_meta" : {
"created_by" : "Iulia Feroli"
},
"properties" : {
"Name" : {
"type" : "keyword",
"type" : "text"
},
"Eye colour": {
"type": "keyword"
},
"House": {
"type": "keyword"
},
"Loyalty": {
"type": "text"
},
"Patronus": {
"type": "keyword"
}
}
client.indices.create(index=index, settings=settings, mappings=mappings)
Adding data
Now, we can either add the documents to our index one at a time, like for our first example:
response = client.index(index = index, id = 1, document = doc_test)
Or we can do a bulk index, adding the entire dataset at once, leveraging the Elasticsearch bulk API.
def generate_operations(documents, index_name):
operations = []
for i, document in enumerate(documents):
operations.append({"index": {"_index": index_name, "_id": i}})
operations.append(document)
return operations
client.bulk(index=index_name, operations=generate_operations(characters, index_name), refresh=True)
Done! Now we have the index in Elastic - which means we can start searching.
You know, for search.
We can create simple queries based on just one feature and value, like this:
response = client.search(index="hp_characters", query={
"match": {
"Loyalty": "Dumbledores Army"
}
})
print("We get back {total} results, here are the top ones:".format(total=response["hits"]['total']['value']))
for hit in response["hits"]["hits"]:
print(hit['_source']['Name'])
You'll notice we also processed the result a little since by default Elasticsearch returns a pretty comprehensive JSON with loads of metadata from our search. In this case, we'll get the name of every character associated with Dumbledore's army (so pretty much the entire Gryffindor 5th years and their allies).
As an FYI, this is what a query and result would look like from the Dev Tools interface on Cloud:
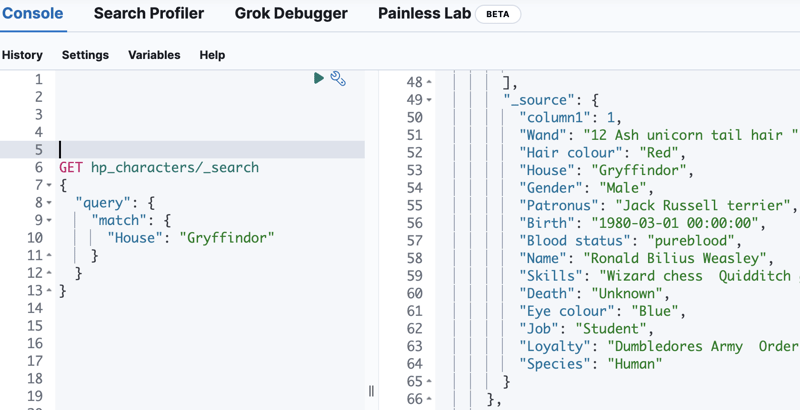
Building up
From here, we can start mixing and matching all kinds of query types to create increasingly specific searches:
response = client.search(index="hp", query = {
"bool": {
"must" : [
{
"multi_match" : {
"query": "quidditch chaser keeper beater seeker",
"fields": [ "Job", "Skills" ]
}
},
{
"match" : {
"House" : "Gryffindor"
}
}
],
"must_not": {
"range": {
"Birth": {
"lte":"1980-01-01"
}
}
},
"filter": {
"term": {
"Hair colour": "Red"
}
}
}
})
Can you guess the answer to this one? It translates to - Red-haired quidditch-associated Gryffindors born after 1980.
(the answer is Ginny & Ron)
That's it, everyone!
That's the basics of interacting with Elasticsearch via the Python client to run searches.
There's loads more you can do in Elastic, from observability & visualizations to semantic / vector search, and way more.
Stay tuned for the next articles :)


















