
Kafka Streams is a powerful tool that adds a high-level abstraction on top of Kafka’s rock-solid infrastructure to enable building streaming applications. It has several features mainly grouped around two concepts, KStreams which represents an infinite stream of data, and KTables which represent a projection of a stream’s data. Even calling these two concepts different is not completely true due to the stream-table duality. While it is not required to have a perfect understanding of the stream-table duality to work with Kafka streams I do find having some level of understanding of it is useful when working with streams. Using these core building blocks of streams and tables (stored projections of stream data) many impressive things can be built. That said, working with infinite streams of data and with the limited query model of a KTable can be tricky and has a steep learning curve. Streams actually provides another way to query your data that follows a more comfortable pattern for many developers and one that adds the ability to query your stream state from outside a stream. This is where interactive queries can come into the picture.
At a high level, interactive queries allow a developer to query the state of a KTable (in reality the data store that backs the KTable) from outside the stream processing code. This allows ad-hoc key-value queries that are performant and, especially for developers new to stream processing code, much easier to understand than querying via a stream. That said, there are some major pitfalls to using interactive queries that may not be apparent when first using them. The pitfall that this post is going to focus on is that the data that a particular instance of a service can query is only a subset of all the data available. To understand why this is, let us briefly remind ourselves how Kafka Streams works and how KTables are populated.
Each KStream is backed by one or more topics each with one or more partitions. Outside of the case where you are only using one partition and/or you only have one instance of your streams application running at a time, different processes will be handling different slices of the data within the topic. One of the great capabilities of Kafka is that it handles this balancing of cooperating consumers automatically for you. As new instances come online they will be assigned one or more partitions that it will be in charge of processing. This allows you to scale out horizontally up to the number of partitions in your topic. This means each instance of the stream application will have its own view of the world. Records that exist on one node won’t exist on another node. This is great for scalability as no one instance needs to shoulder all the load. A simplified model of this can be seen here:

So how does this interact with interactive queries? The interactive query functionality allows an instance of the streams application to perform ad-hoc queries of the local state by key. If the partition that a specific key is assigned is the same partition that the current instance is assigned, all will work wonderfully as the data will be there in the local state store. However, if the key is assigned a partition that is not assigned to the querying instance then you are out of luck. The interactive streams documentation acknowledges this fact and leaves resolving it to the user with the hint that some kind of remote procedure call (RPC) method would likely need to be employed. While I understand that the library cannot solve all problems, not having an out-of-the-box solution for this leaves developers in a tough spot. What makes this particularly troublesome is developers may initially develop against a small data set with a topic that only has one partition and/or instance and thus not see this issue until they release it into a more production-like, horizontally-scaled environment. Of note, using streams to query a KTable does not have this issue because the stream will be co-partitioned with the KTable and thus will always be on the correct node to do the lookup.
This post strives to propose an idea of how we can account for this issue of data locality and allow any instance of a streams application to query any data. As a scaffold to discuss this solution I have developed a simple example application that loads up a topic with various records and then exposes a REST endpoint that allows someone to retrieve the information by key. There are a lot of interesting things even in this simple application but I will focus mainly on the parts of it that enable the cross node interactive query functionality.
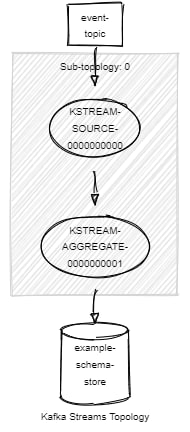
The topology for our application is quite basic. Events come in on the “event-topic” are consumed into a stream then aggregated into a state store.
The first thing we need to handle is enabling each instance of our application to self-identify where it is being hosted and provide that information to the streams library so that it can provide that information to other nodes in the future. In this example application we have a simple configuration that gathers the current host information that looks like this:
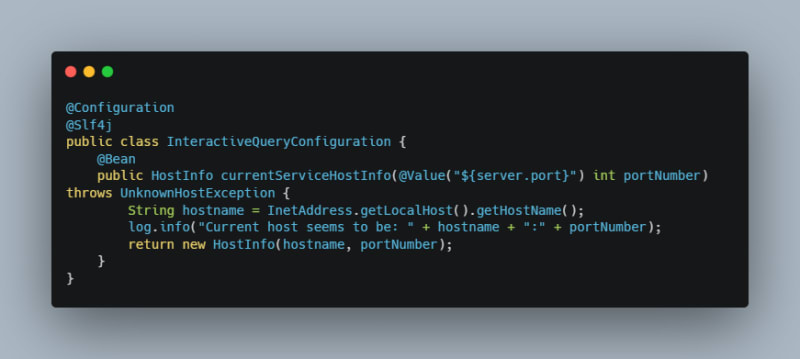
The above is extremely simplistic and likely won’t work in many environments where hostnames are not as immediately available as in the above but the same concept can be used. At this point, we can use the above configuration in our streams configuration.
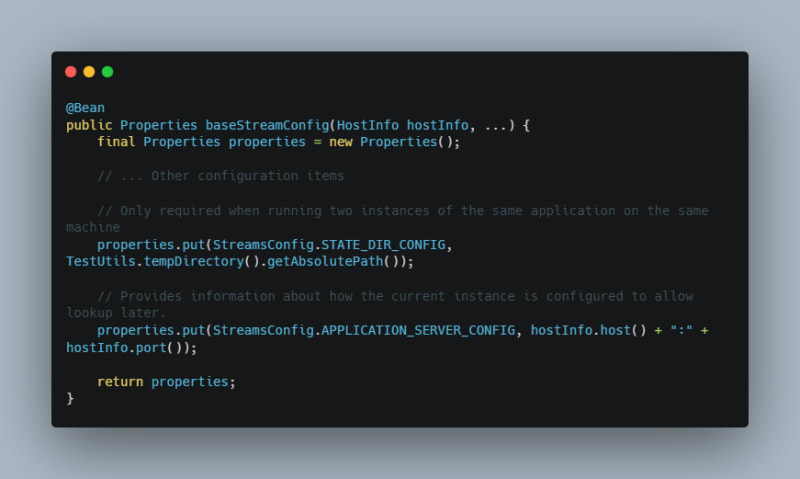
I have truncated much of the streams configuration here but left the two interesting things. The first is that, because we will be running two instances of this application locally, I changed the directory that state is stored so that multiple state stores can coexist on the same machine. This shouldn’t be required when using different servers but also shouldn’t hurt anything. The second is that we are telling Kafka Streams where our current service is hosted. The streams library will pass back this information later when we need to find out where a particular key is stored.
The high-level concept of how this system is going to work is that a request will come into our application, we will check with streams to determine if the queried key is stored on the local node or if it is on a remote node. If it is local we will query the state store locally and return the result. If the data is remote we will retrieve the host information about where it is stored and then make a HTTP call to that service which can do the same lookup which will now be local, return the result via the HTTP response, and then the original service can return the result as if it had it locally. To support this we have a few pieces of code.
The first piece of code that we need is a class that can hold all the pieces of information that are needed to determine if a remote call needs to be made and information needed to make the remote call.

A querying service then can call a method with the following signature to do the lookup:

The StoreInfo class is passed in as seen above as well as the key that will be queried and then a higher-order function to be used if the data is determined to be local to pull the data from the local store. The body of the above function is something like the following:

As discussed above this queries the metadata for a particular state store, retrieves its host info (the information we stored at configuration time), determines if it is local, if so it calls the higher-order function for processing passed in, if not it generates the body from the key, sets the right “Content-type” header, copies the authorization header from the current request to the outgoing request, generates the URL to query based on the metadata and information passed in, queries the remote service, and passes on an appropriate response.
The final chunk of code we will look at is what it looks like to call this service.
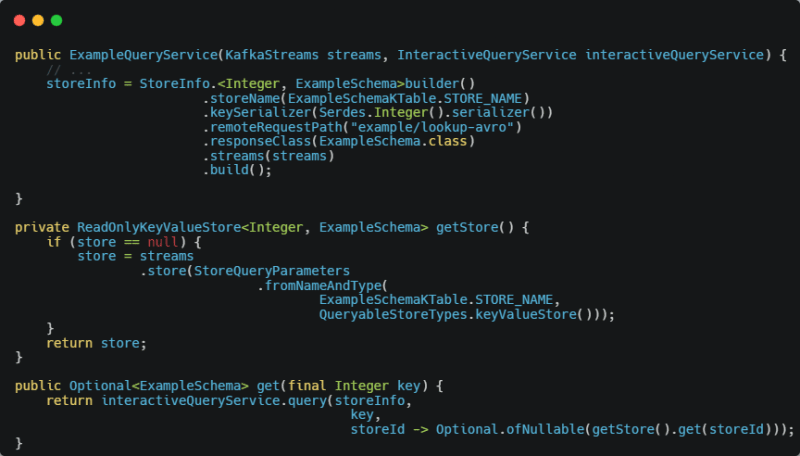
In reality, there is not much more code required compared to if we were only doing the local query which is nice. The InteractiveQueryService is also coded in such a way that it can handle various types of keys and responses.
Environment Setup
Let’s see how it works. To save ourselves some effort of setting up Kafka locally we will use Upstash as our Kafka service. Upstash is a Serverless Kafka offering where you pay per message you produce/consume. They have a free tier which is more than sufficient for this test and gives you a good idea of how the service works. To get ready to run the application you have two options. You can set up the cluster manually or use some additional code I added to the repo to create the needed infrastructure via the Upstash API. I’ll walk through both.
Manual Setup
After verifying your email address and logging into the console go to the Kafka section:

Press create cluster and fill out the information. There is no required setup as far as the cluster is concerned for this POC so give the cluster any name and choose the region closest to you.

Then you can create your first topic. Unfortunately (at least with the free tier) the credentials you get from Upstash don’t allow the application to create its own topics. This is safer for production but just requires a little more work for this POC. Create a topic with the following information, the rest of the defaults are fine.
Now we need to create another topic that will be used to back the state store inside of Kafka Streams.
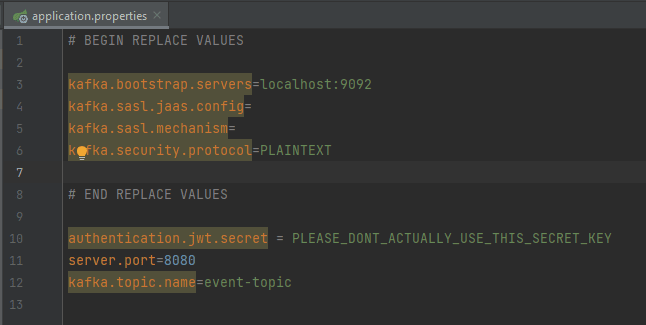
Now we can go back to the “Details” tab and grab our configuration.

Copy those values and paste them over the existing values in the application.properties file in our repository. Make sure to prefix each of the keys with "kafka.".
Now you are ready to go.
Automated Setup
For the automated setup, we first need to create a “Management API Key” by going up to “Account” -> “Management API” -> “Create API Key”

Grab that value and the email address you signed up with and put them into the variables at the top of the ConfgureEnvironment.java class
Run that class and grab the output.

Finally, paste those values over the existing values in the application.properties file.
Seeing the Code In Action
With our environment setup complete we can now test our application. Run the bootJar gradle task to build the jar and then, in two different terminal windows, navigate to the folder with the jar. We will then run the application with the following commands:
java -jar cross-node-iq-0.0.1-SNAPSHOT.jar
java -jar cross-node-iq-0.0.1-SNAPSHOT.jar --server.port=8081
After both nodes have come up and the logs have quieted down (indicating that rebalancing is complete) we are ready to query the application. You can choose to query either the node on 8080 or the one on 8081 since the whole point of this is it doesn’t matter which node is in charge or which key, it should work with either. For my test I will make the following request:
curl -i -H “Authorization:Bearer eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MSwic3ViIjoidGVzdFVzZXIifQ.ZRq6TnZiBlkY1CDkkQP2RnTOMV58OxgC30W0u7AjTCg” localhost:8081/example/1
A lot of the above command is to manage the authentication. If you haven’t changed the authentication.jwt.secret from the application.properties file the above value should work for you too.
This gave me the following result:

Checking the logs of the node I queried we see it did not have the answer:
![]()
Checking the logs of the other node we see that it had it locally.
![]()
So it does indeed work. We can change the port number and query the one that has it locally and we see that it responds exactly the same. Looking at how long it takes to respond you can see some differences when it has to jump nodes and that will always have some effect but could be mitigated somewhat by keeping an open connection between nodes if that was desired.
As I have said above, there is a lot more to this application and some interesting concepts I think. Using Avro schemas without a schema registry, serializing/deserializing Avro for HTTP requests and response, simple authentication, etc. So do go ahead and jump in the code and see what there is to learn.
Conclusion
So where does this put us? With our new found ability to query across nodes are interactive queries ready to roll? Not so much. There are still other issues with interactive queries that must be accounted for, a major one being that during rebalances and hydration of state they are unusable. The above solution is also far from an end solution, it is merely the beginning of a much more feature-rich RPC framework that would be required if this was rolled out into a production environment. It does however show what is possible with a few good abstractions. This is also not the only way to solve this issue either, others have chosen to merely respond with basically a redirect when a client requests data that the current node does not have. All implementations have their tradeoffs and we need to know what we are optimizing for as we dive into these implementations. Even with its current limitations, interactive queries may be perfect for an application you are building, you just need to accept the failure modes that it has. If those failure modes are acceptable then interactive queries could be a great solution for interacting with the state within Kafka Streams in your application.


















