
Recently we had a significant performance improvement in our linter rule. In some benchmarks, the increase was up to 100x! While one would expect such a dramatic change to result from implementing a sophisticated algorithm, the reality is that this resulted from minor tweaks.
Like the butterfly effect - changing a few lines of code created a ripple effect that tremendously improved the overall performance.
Discovery of the problem
We always knew we could improve the performance of the linter rule. Like in other parts of Nx, we keep finding ways to shave off another 100ms here and there. Improving performance has been an ongoing process.
While implementing a new feature, we realized this new feature was adding 20% on top of the rule's duration. That performance impact could not be justified, even for critical features, let alone a nice-to-have one. So we revisited the code of the implementation.
Not all loops are born equal
At a first glimpse, nothing seemed off. The code was logical, didn't have unnecessary nested loops, and used modern Array higher-order functions - filter, map, reduce, which helped the code be shorter and easier to read. We also used the popular trick with Set to extract the unique values from the array.
The code looked like this (we replaced some functions with pseudo-code for simplicity):
const allReachableProjects = Object.keys(graph.nodes)
.filter(pathExistsBetweenSourceAndNode && graph.dependencies[project]);
const externalDependencies = allReachableProjects
.map((project) =>
graph.dependencies[project].filter(
isDependencyExternal
)
)
.filter((deps) => deps.length)
.flat(1);
return Array.from(new Set(externalDependencies));
We filtered all the nodes reachable from our source node that had dependencies. We then further mapped each of those projects to arrays of their external dependencies, filtered out those that didn't have any external dependencies, and finally flattened the two-dimensional array to a plain array.
The last line - Array.from(new Set(…)) uses the above-mentioned trick to filter out duplicates.
The higher-order functions are a very nice way to encapsulate otherwise boilerplate code, but they come with a hidden cost. Each iteration of map, filter, and reduce creates a new array by combining items from the previous iteration and adding a new element.
This led to a hidden inner loop. What initially looked like a single loop, in reality, were two loops:
- iterating over elements of the source array
- iterating over elements of the temporary array in every step
To avoid this, we used for loops with Array.push. We start with an empty reachableProjects array, and every time project satisfies the condition, we push it to our array. We applied the same logic to externalDependencies. Instead of a map, filter, and flat, we use loops and if conditions. We introduce a hash table to ensure no duplicates in our resulting collection. Once we add the project to the array, we mark it in our hash table with true, so we can quickly check if we have added it already.
This is what the resulting code looked like:
if (!graph.externalNodes) {
return [];
}
const reachableProjects = [];
const projects = Object.keys(graph.nodes);
for (let i = 0; i < projects.length; i++) {
if (pathExistsBetweenSourceAndNode) {
reachableProjects.push(projects[i]);
}
}
const externalDependencies = [];
const externalDependenciesMap = {};
for (let i = 0; i < reachableProjects.length; i++) {
const dependencies = graph.dependencies[reachableProjects[i]];
if (dependencies) {
for (let d = 0; d < dependencies.length; d++) {
const dependency = dependencies[d];
if (graph.externalNodes[dependency.target] && !externalDependenciesMap[dependency.target]) {
externalDependencies.push(dependency);
externalDependenciesMap[dependency.target] = true;
}
}
}
}
return externalDependencies;
The benchmark showed a 2–3% slowdown, significantly better than the initial 20%. Combined with an optional toggle, this was now acceptable. The success with improving performance motivated us to check the remaining rule code and see if we can apply a similar approach elsewhere.
Single shelf principle
Unfortunately, there weren't too many filter or map functions to replace, and those there didn't make much difference. Most of the slowdown was coming from two functions:
- finding the source project based on the file
- finding the target project based on the import
Both were iterating the graph, looking for a project that contained a given file (import target was either mapped to file if it was a relative import or mapped to barrel entry file in case of cross-project imports).
The graph was already improved earlier for linting and used a slightly more ingenious structure than the default graph.
Before:
{
"nodes": {
"project-a": {
// ... other fields
"data": {
// ... other fields
"files": [
{
"file": "packages/project-a/a.ts",
"hash": "...",
"ext": "ts"
},
// ...
]
}
},
// ... other projects
},
"externalNodes": { ... },
"dependencies": [...]
}
After (notice the files section):
{
"nodes": {
"project-a": {
// ... other fields
"data": {
// ... other fields
"files": {
"packages/project-a/a": {
"file": "packages/project-a/a.ts",
"hash": "...",
"ext": "ts"
},
// ...
}
}
},
// ... other projects
},
"externalNodes": { ... },
"dependencies": [...]
}
Unfortunately, while this gave great results if your monorepo consisted of a large monolith app and several small additional libraries, importing from the last project in the graph in a monorepo with hundreds of projects was still very slow. We would iterate through all the projects repeatedly and check which project contained that file.
The solution was simple. Instead of modifying the files section of each project from array to lookup table, we added a new field to the graph that contained a table with all the files' paths, each pointing to its parent project:
{
"nodes": {
"project-a": {
// ... other fields
"data": {
// ... other fields
"files": [
{
"file": "packages/project-a/a.ts",
"hash": "...",
"ext": "ts"
},
// ...
]
}
},
// ... other projects
},
"externalNodes": { ... },
"dependencies": [...],
"allFiles": {
"packages/project-a/a": "project-a",
// ...
}
}
Forgotten O(n²) spread
There were reports from some users that the linter is too slow for them. One of our clients reported incredible values where the enforce-module-boundaries rule would run for a minute per project and consumed up to 96% of all the linting work.
We were excited to test this new improvement on their solution. To our surprise, the improvement was "only" 6x. Linting the project still took almost 10sec.
We started digging and time-tracking each code block using the console.time until we realized that almost all that time was spent checking for the circular dependencies. The code that checked for circular dependencies was straightforward - we have an adjacency matrix:
- Given each pair of the projects (A, B), if project B is reachable from project A, we mark that field in the matrix with
true - To check if there is a circular dependency, we check if A is reachable from B, where B is a direct dependency of A
So that couldn't have been it. Also, the matrix was only generated once and used from memory until the graph changed. It turned out that single matrix generation was extremely slow in large monorepos with thousands of projects.
The code looked like this:
function buildMatrix(graph) {
const dependencies = graph.dependencies;
const nodes = Object.keys(graph.nodes);
const adjList = {};
const matrix = {};
const initMatrixValues = nodes.reduce((acc, value) => {
return { ...acc, [value]: false };
}, {});
for (let i = 0; i < nodes.length; i++) {
const v = nodes[i];
adjList[v] = [];
matrix[v] = { ...initMatrixValues };
});
for (let proj in dependencies) {
for (let dep of dependencies[proj]) {
if (graph.nodes[dep.target]) {
adjList[proj].push(dep.target);
}
}
}
const traverse = (s: string, v: string) => {
matrix[s][v] = true;
for (let adj of adjList[v]) {
if (matrix[s][adj] === false) {
traverse(s, adj);
}
}
};
nodes.forEach((v) => {
traverse(v, v);
});
return {
matrix,
adjList,
};
}
As you might have learned in this article, using reduce isn't the smartest thing to do when you care about performance, so our first step was to replace reduce with for loop and Array.push. We then focused on the usual suspect - the recursion in the traverse function. But all potential improvements failed to make a difference. So we again added console.time to establish what was going on. It turned out, that the problematic line was:
matrix[v] = { ...initMatrixValues };
So what was going on there?
We first create an initMatrixValues object, a default hash map where the project name points to false. We then loop through the nodes and set the values in the matrix where each project points to a copy of the initMatrixValues. This seemed like a good idea.
Unfortunately, we forgot that spreading the object iterates through all its members, effectively making another inner loop in the forEach. It also creates a temporary object each step and copies all the members to the new object every step of the way. You guessed right - this adds another loop, effectively giving O(n³) complexity.
The first step in the optimization was to generate matrix values for every node in an inner loop instead of spreading the prebuilt one.
for (let i = 0; i < nodes.length; i++) {
const node = nodes[i];
adjList[node] = [];
const initMatrixValues = {};
for (let j = 0; j < nodes.length; j++) {
initMatrixValues[nodes[j]] = false;
});
matrix[node] = { ...initMatrixValues };
});
And then Stefan, who helped with the performance investigation, had a brilliant revelation - we explicitly use false to mark that there is no connection between two nodes. Still, we could also assume that no value means there is no connection. Instead of generating an object with pre-filled nodes with an explicit false value, we could start with an empty object. This finally brought us to ideal O(n) and gave us 100x improvement in the original run (the function itself is exponentially faster, as seen in this benchmark).
The code now looked like this:
for (let i = 0; i < nodes.length; i++) {
const node = nodes[i];
adjList[node] = [];
matrix[node] = {};
});
The original tweet showed the performance improvement numbers on the client's project:
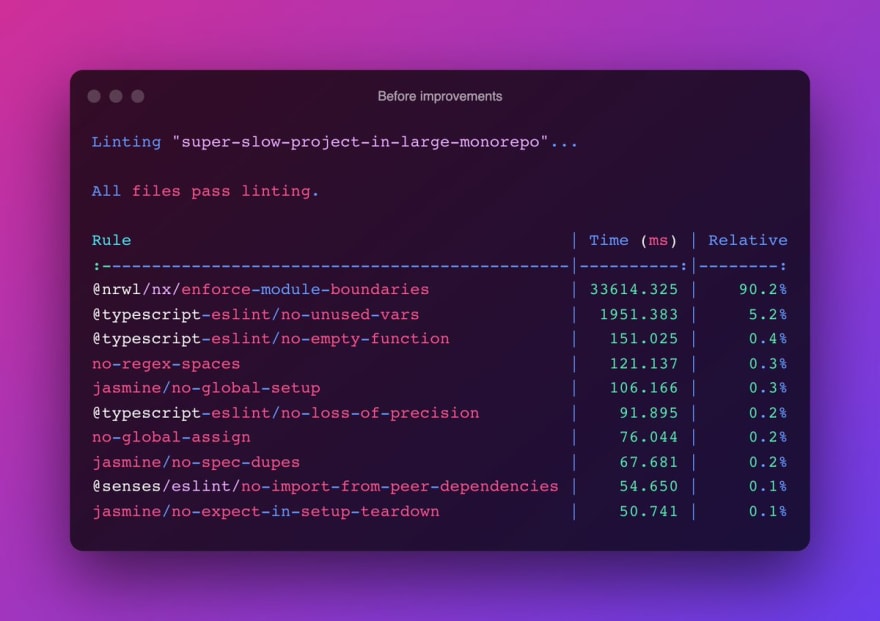





Conclusion
In this article, we showed how small changes could make an enormous impact on your code performance. Even a simple change like slice instead of replace + regex can reduce time. Modern higher-order functions make your code look slicker, but this often comes with a price tag.
If you are looping over a small collection, you will most likely never notice any difference from introducing such micro-optimizations.
However, suppose your code iterates over an extensive collection and does that repeatedly, as our rule does. In that case, you might want to investigate whether you can optimize the code by using loops and lookup tables.
You don't need to know the performance of different native implementations by heart. Just think of all the possible ways you can achieve a specific task and run it through a benchmark to see which one performs best. It's a fun experiment, and your users will be grateful for it.
Credits
Thanks to Stefan Van de Vooren, who helped benchmark the improvements on his company's repository and provided valuable inputs, and whose company brought to our attention the severity of the performance issue on the linter. Thank you goes also to Juri Strumpflohner for the valuable feedback while reviewing this article.


















