
We need to have some real talk around what we are calling Developer Experience (DX) at developer-focused companies.
It's not well defined, although Chris Coyier has done a good survey of what people think of when they hear the term, and others try to define Developer Enablement. It's a differentiator among devtools, so of course it is professionalizing, and creeping into job titles (my last job title was "Developer Experience Engineer", whatever that actually means). I fully expect this to develop into a fullblown sub-industry, with conferences and thoughtleaders and gatekeepers and the like (right down to "Dev Advocate Cofounder").
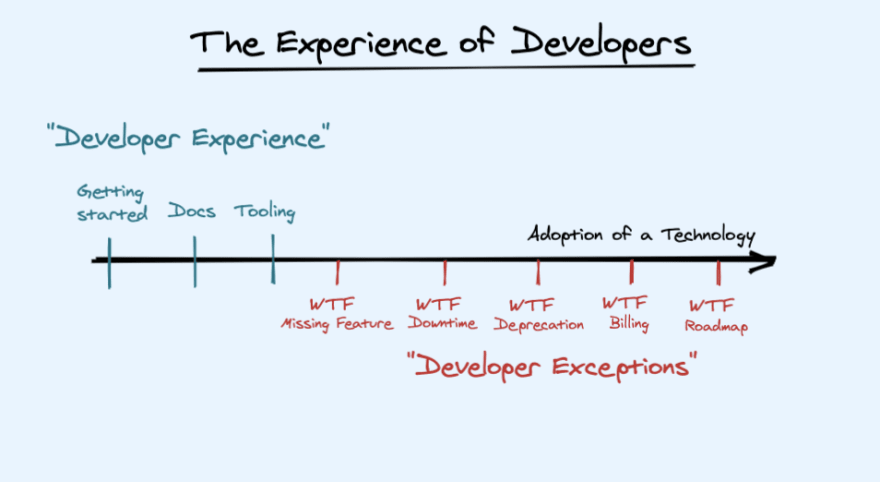
"Developer Experience"
Here are some things that companies traditionally work on when they "work on DX":
- Replacing many with few: Replacing many lines of code with few lines of code. Replacing many logos with one logo. Replacing many steps with one click (signup, deploy). Generating code so you don't have to handwrite it. Providing great value and plenty of functionality as a first-party, out of the box, or with zero config.
- Extensive Documentation: Getting Started. Example Demos. Interactive Examples. Full API Docs. Guides and Recipes. Good Search. Versioning. (appropriate to project maturity)
- More tooling: CLIs, Editor Extensions, Code Snippets, Playgrounds, Language Servers.
I'm not at all saying these things aren't important. They're even hard to do well, and fully deserve specialists in their own right. These foundational pieces of developer experience should also be fast and intuitive to the point of guessable.
"Developer Exceptions"
But I'm also saying that developers, when they use our products, experience many other things which aren't traditionally the domain of "DX people", because they have to do with core engineering and product promises:
- Downtime: When your service goes down, does your status page lie? Do you refrain from tweeting about it for fear of scaring off customers you don't yet have, rather than reassuring those you do? Do you post prompt, no-bullshit post-mortems? Do you provide good fallback options for when your service is down? Do you practice disaster recovery?
- Response times: Are you not just meeting your SLAs, but actually clearly answering customer questions? What are you doing for users not yet covered by SLAs? For your open source footprint, do users have confidence that their issues will be addressed and appropriate PRs reviewed, or are you asking people to do free work for you that you then ignore?
- Missing/Incomplete Features: No product launches feature complete. Nobody expects you to. The true test is whether you address it up front or hide it like a dirty secret. As developers explore your offering, they will find things they want, that you don't have, and will tell you about it. How long do you make developers dig to find known holes in your product? Do developers have confidence you will ship or reject these features promptly, or are they for a "v2" that will never come?
- Uncertainty over roadmap: Do your most avid users know what's coming so they can plan around your plan? If that's too high a bar, do your own employees know what's coming so they can coordinate nicely? Do you have "perma-beta" products? How do you communicate when users ask if they should use "orphan" products? (don't be ashamed, everyone has them)
- Uncertainty over costs: Is your pricing predictable or do your users need a spreadsheet to figure out what you are going to charge them? If charges are unexpectedly high, can developers use your software to figure out why or do they have to beg for help? Are good defaults in place to get advance warning? Have your employees ever paid for your own product (or had to justify doing so to their own employers)?
- Deprecation/Lock-in/Portability: Do you constantly deprecate APIs and products, causing additional work for no gain? Some amount of lock-in is unavoidable, but are you conscious of how much proprietary API you are foisting on your user? Should your user want to leave someday for whatever reason, have you documented that and made that easy, or are they on their own?
- Debugging: Are your errors informative or scary? Have you designed them to be searchable or do they only make sense to maintainers? When things go wrong, how quickly does your service surface common issues and offer resolution steps? What about enabling users to answer questions they don't yet know they have? If developers are constantly making mistakes and "holding the phone wrong", is it their fault or yours?
- Audit Logs & Access Control: Many products start life in single-player mode, and then execute a very clumsy transition to multi-player when they start serving teams and enterprise. When something that shouldn't have been done has been done, do you offer trustworthy sources of truth, and ways to prevent repeats (or, of course, make them impossible in the first place)?
- Error Messages: Are your errors helpful or cryptic? Don't make me think!
Causes
Of course, none of these are new problems, and well known to product management. The problem is mostly organizational - as "developer advocacy" as a discipline evolved from "developer evangelism" (going from a "1 way street" to a "2 way street"), it is now evolving to "developer experience". I see a troubling organizational limitation of DX folks, defining DX to the stuff that focuses on increasing "top of funnel" growth (reducing friction, growing awareness, an endless parade of copycat short term growth hacks) - and having comparatively a lot less impact on the "bottom of funnel" stuff (logo churn, satisfaction scores, account expansion/customer success). There's little sense making more rain when faced with a leaky bucket.
Conway's Law is an eponymous law that states that "organizations design systems that mirror their own communication structure". Steven Sinofsky's snappier definition is "don't ship your org chart". We need to be careful about the consequences of letting Conway's Law apply to Developer Experience.
Engineering for Developer Exceptions
To be clear, I don't really know how to do this yet. I am just thinking out loud. But my intuition is that in order to design exceptional developer experiences, we should pay more attention to developer exceptions. As DX people, we've focused a lot on try, perhaps we should take a good look at catch.
The first thing to fix is organizational incentives. DX work must not just feel welcome, it must be demanded and good results rewarded. Nobody wants to feel like they are adding weight onto an already overloaded backlog. Most orgs are set up in a way that lack of feedback isn't noticed when it isn't given, and feedback when given feels like additional burden. This is, unsurprisingly, not conducive to feedback.
The second thing is to establish invariants around your core developer experience and automate monitoring and reporting of these to the fullest extent possible. Tools that hold the line are incredibly powerful. To progress, you need to first stop regressing.
My last thought is around helping PMs and EMs create DX, rather than taking primary responsibility. If you're sending in PRs and design docs yourself, you are probably doing too much of someone else's job and will be ineffective and/or resented. Better to provide them the information they need to make decisions and be available for opinions and instant feedback since you represent the end user. It is common for there to be an infinite list of small things to do - and that is very hard to sell internally - so how can you bundle these up into thematic projects, motivate engineers, and carefully communicate progress to the wider world?
It's time we look beyond the easy questions in developer experience, and start addressing the uncomfortable ones.
Note: This is my own thinking sparked by a third party conversation, and I am not speaking on behalf of my current employer.
- https://www.swyx.io/write-errors-that-don-t-make-me-think-24hg/
- https://lethain.com/platform-product-fit/
The diverging results of these approaches are perhaps most easily seen in the evolution of their respective Identity and Access Management offering. Google’s IAM historically offered an elegant interface but limited support for common usecases like sub-bucket object permissioning. Amazon’s IAM skewed towards extreme flexibility, gleefully sacrificing comprehensibility for completeness. In my opinion. Google’s platform has become much easier to start on and equipped with better defaults for new projects, but remains difficult-to-impossible to operate on as a scaled enterprise user. (Results are also measurable in quarterly earnings.)


















