
This article will employ a simple example to demonstrate how we can integrate PySpark with Taipy to couple your big data processing needs with smart job execution.
Let's get started!

Using PySpark with Taipy
Taipy is a powerful workflow orchestration tool with an easy-to-use framework to apply to your existing data applications with little effort.
Taipy is built on a solid foundation of concepts - Scenarios, Tasks and Data Nodes - which are robust in allowing developers to easily model their pipelines, even when using 3rd party packages without explicit support.

We appreciate any kind of help to help us grow our community 🌱
If you're already familiar with PySpark and Taipy, you can skip ahead to "2.
The Taipy configuration (*config.py)".
That section dives right into the nitty-gritty of defining a function for a Taipy task to run a PySpark application. Otherwise, read on!
A Simple Example: palmerpenguins
Let's use the palmerpenguins dataset as an example:
>>> penguin_df
┌───────┬─────────┬───────────┬────────────────┬───────────────┬───────────────────┬─────────────┬────────┬──────┐
│ index │ species │ island │ bill_length_mm │ bill_depth_mm │ flipper_length_mm │ body_mass_g │ sex │ year │
├───────┼─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼──────┤
│ 0 │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181.0 │ 3750.0 │ male │ 2007 │
│ 1 │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186.0 │ 3800.0 │ female │ 2007 │
│ 2 │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195.0 │ 3250.0 │ female │ 2007 │
│ 3 │ Adelie │ Torgersen │ NaN │ NaN │ NaN │ NaN │ NaN │ 2007 │
│ 4 │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193.0 │ 3450.0 │ female │ 2007 │
│ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │
└───────┴─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴──────┘
This dataset only contains 344 records - hardly a dataset which requires Spark for processing.
However, this dataset is accessible, and its size is not relevant for demonstrating the integration of Spark with Taipy.
You may duplicate the data as many times as you need if you must test this with a larger dataset.
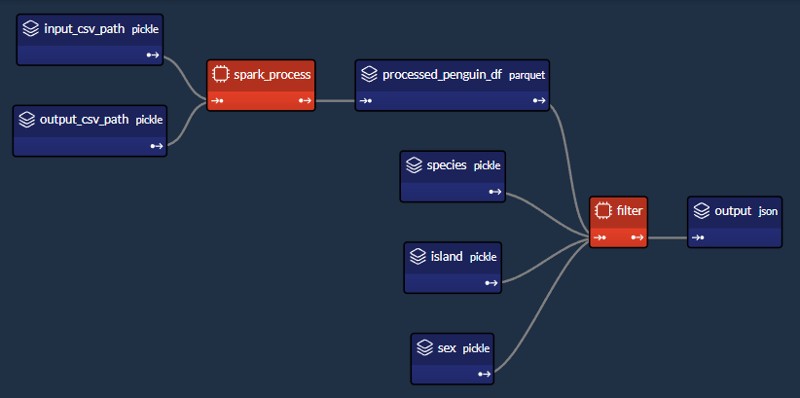
The DAG of our simple penguin application
We'll design a workflow which performs two main tasks:
1- Spark task (spark_process):
- Load the data;
- Group the data by "species", "island" and "sex";
- Find the mean of the other columns ("bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g");
- Save the data.
2- Python task (filter):
- Load the output data saved previously by the Spark task;
- Given a "species", "island" and "sex", return the aggregated values.
Our little project will comprise of 4 files:
app/
├─ penguin_spark_app.py # the spark application
├─ config.py # the configuration for our taipy workflow
├─ main.py # the main script (including our application gui)
├─ penguins.csv # the data as downloaded from the palmerpenguins git repo
You can find the contents of each file (other than penguins.csv which you can get from palmerpenguins repository) in code blocks within this article.
1. The Spark Application (penguin_spark_app.py)
Normally, we run PySpark tasks with the spark-submit command line utility.
You can read more about the what and the why of submitting Spark jobs in this way in their own documentation here.
When using Taipy for our workflow orchestration, we can continue doing the same thing.
The only difference is that instead of running a command in the command line, we have our workflow pipeline spawn a subprocess which runs the Spark application using spark-submit.
Before getting into that, let's first take a look at our Spark application.
Simply glance through the code, then continue reading on for a brief explanation on what this script does:
### app/penguin_spark_app.py
import argparse
import os
import sys
parser = argparse.ArgumentParser()
parser.add_argument("--input-csv-path", required=True, help="Path to the input penguin CSV file.")
parser.add_argument("--output-csv-path", required=True, help="Path to save the output CSV file.")
args = parser.parse_args()
import pyspark.pandas as ps
from pyspark.sql import SparkSession
def read_penguin_df(csv_path: str):
penguin_df = ps.read_csv(csv_path)
return penguin_df
def clean(df: ps.DataFrame) -> ps.DataFrame:
return df[df.sex.isin(["male", "female"])].dropna()
def process(df: ps.DataFrame) -> ps.DataFrame:
"""The mean of measured penguin values, grouped by island and sex."""
mean_df = df.groupby(by=["species", "island", "sex"]).agg("mean").drop(columns="year").reset_index()
return mean_df
if __name__ == "__main__":
spark = SparkSession.builder.appName("Mean Penguin").getOrCreate()
penguin_df = read_penguin_df(args.input_csv_path)
cleaned_penguin_df = clean(penguin_df)
processed_penguin_df = process(cleaned_penguin_df)
processed_penguin_df.to_pandas().to_csv(args.output_csv_path, index=False)
sys.exit(os.EX_OK)
We can submit this Spark application for execution by entering a command into the terminal like:
spark-submit --master local[8] app/penguin_spark_app.py \
--input-csv-path app/penguins.csv \
--output-csv-path app/output.csv
Which would do the following:
- Submits the penguin_spark_app.py application for local execution on 8 CPU cores;
- Loads data from the app/penguins.csv CSV file;
- Groups by "species", "island" and "sex", then aggregates the remaining columns by mean;
- Saves the resultant DataFrame to app/output.csv.
Thereafter, the contents of app/output.csv should be exactly as follows:
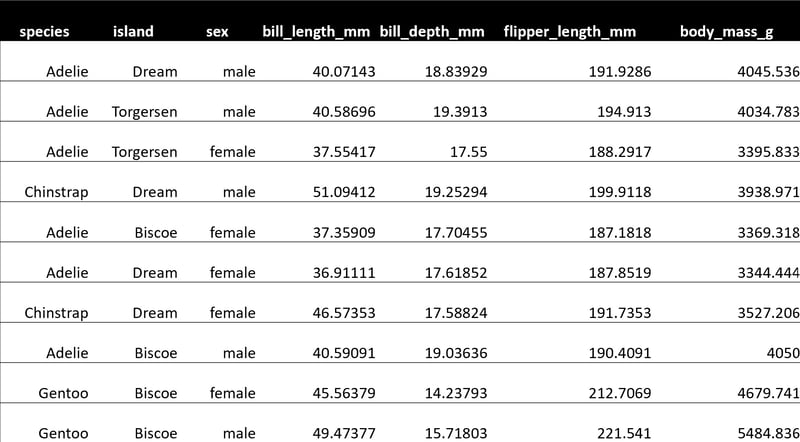
Also, note that we have coded the Spark application to receive 2 command line parameters:
- - input-csv-path : Path to the input penguin CSV file; and
- - output-csv-path : Path to save the output CSV file after processing by the Spark app.
2. The Taipy configuration (config.py)
At this point, we have our penguin_spark_app.py PySpark application and need to create a Taipy task to run this PySpark application.
Again, take a quick glance through the app/config.py script and then continue reading on:
### app/config.py
import datetime as dt
import os
import subprocess
import sys
from pathlib import Path
import pandas as pd
import taipy as tp
from taipy import Config
SCRIPT_DIR = Path(__file__).parent
SPARK_APP_PATH = SCRIPT_DIR / "penguin_spark_app.py"
input_csv_path = str(SCRIPT_DIR / "penguins.csv")
# -------------------- Data Nodes --------------------
input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path)
# Path to save the csv output of the spark app
output_csv_path_cfg = Config.configure_data_node(id="output_csv_path")
processed_penguin_df_cfg = Config.configure_parquet_data_node(
id="processed_penguin_df", validity_period=dt.timedelta(days=1)
)
species_cfg = Config.configure_data_node(id="species") # "Adelie", "Chinstrap", "Gentoo"
island_cfg = Config.configure_data_node(id="island") # "Biscoe", "Dream", "Torgersen"
sex_cfg = Config.configure_data_node(id="sex") # "male", "female"
output_cfg = Config.configure_json_data_node(
id="output",
)
# -------------------- Tasks --------------------
def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame:
proc = subprocess.Popen(
[
str(Path(sys.executable).with_name("spark-submit")),
str(SPARK_APP_PATH),
"--input-csv-path",
input_csv_path,
"--output-csv-path",
output_csv_path,
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
try:
outs, errs = proc.communicate(timeout=15)
except subprocess.TimeoutExpired:
proc.kill()
outs, errs = proc.communicate()
if proc.returncode != os.EX_OK:
raise Exception("Spark training failed")
df = pd.read_csv(output_csv_path)
return df
def filter(penguin_df: pd.DataFrame, species: str, island: str, sex: str) -> dict:
df = penguin_df[(penguin_df.species == species) & (penguin_df.island == island) & (penguin_df.sex == sex)]
output = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]].to_dict(orient="records")
return output[0] if output else dict()
spark_process_task_cfg = Config.configure_task(
id="spark_process",
function=spark_process,
skippable=True,
input=[input_csv_path_cfg, output_csv_path_cfg],
output=processed_penguin_df_cfg,
)
filter_task_cfg = Config.configure_task(
id="filter",
function=filter,
skippable=True,
input=[processed_penguin_df_cfg, species_cfg, island_cfg, sex_cfg],
output=output_cfg,
)
scenario_cfg = Config.configure_scenario(
id="scenario", task_configs=[spark_process_task_cfg, filter_task_cfg]
)
You can also build the Taipy configuration using Taipy Studio, a Visual Studio Code extension which provides a graphical editor for building a Taipy .toml configuration file.
The PySpark task in Taipy
We are particularly interested in the code section which produces this part of the DAG:
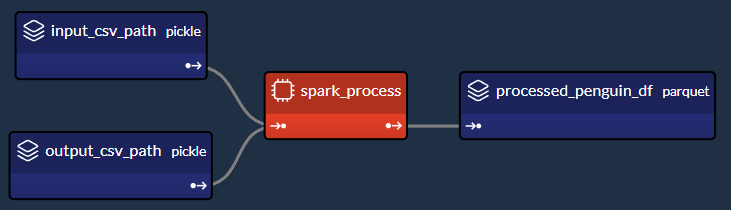
Let's extract and examine the relevant section of the config.py script which creates the "spark_process" Spark task (and its 3 associated data nodes) in Taipy as shown in the image above:
### Code snippet: Spark task in Taipy
# -------------------- Data Nodes --------------------
input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path)
# Path to save the csv output of the spark app
output_csv_path_cfg = Config.configure_data_node(id="output_csv_path")
processed_penguin_df_cfg = Config.configure_parquet_data_node(
id="processed_penguin_df", validity_period=dt.timedelta(days=1)
)
# -------------------- Tasks --------------------
def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame:
proc = subprocess.Popen(
[
str(Path(sys.executable).with_name("spark-submit")),
str(SPARK_APP_PATH),
"--input-csv-path",
input_csv_path,
"--output-csv-path",
output_csv_path,
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
try:
outs, errs = proc.communicate(timeout=15)
except subprocess.TimeoutExpired:
proc.kill()
outs, errs = proc.communicate()
if proc.returncode != os.EX_OK:
raise Exception("Spark training failed")
df = pd.read_csv(output_csv_path)
return df
spark_process_task_cfg = Config.configure_task(
id="spark_process",
function=spark_process,
skippable=True,
input=[input_csv_path_cfg, output_csv_path_cfg],
output=processed_penguin_df_cfg,
)
Since we designed the penguin_spark_app.py Spark application to receive 2 parameters (input_csv_path and output_csv_path), we chose to represent these 2 parameters as Taipy data nodes.
Note that your use case may differ, and you can (and should!) modify the task, function and associated data nodes according to your needs.
For example, you may:
- Have a Spark task which performs some routine ETL and returns nothing;
- Prefer to hard code the input and output paths instead of persisting them as data nodes; or
- Save additional application parameters as data nodes and pass them to the Spark application.
Then, we run spark-submit as a Python subprocess like so:
subprocess.Popen(
[
str(Path(sys.executable).with_name("spark-submit")),
str(SPARK_APP_PATH),
"--input-csv-path",
input_csv_path,
"--output-csv-path",
output_csv_path,
],
)
Recall that the order of the list elements should retain the following format, as if they were executed on the command line:
$ spark-submit [spark-arguments] <pyspark-app-path> [application-arguments]
Again, depending on our use case, we could specify a different spark-submit script path, Spark arguments (we supplied none in our example) or different application arguments based on our needs.
Reading and returning output_csv_path
Notice that the spark_process function ended like so:
def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame:
...
df = pd.read_csv(output_csv_path)
return df
In our case, we want our Taipy task to output the data after it is processed by Spark - so that it can be written to the processed_penguin_df_cfg Parquet data node.
One way we can do this is by manually reading from the output target (in this case, output_csv_path) and then returning it as a Pandas DataFrame.
However, if you don't need the return data of the Spark application, you can simply have your Taipy task (via the spark_process function) return None.
Caching the Spark Task
Since we configured spark_process_task_cfg with the skippable property set to True, when re-executing the scenario, Taipy will skip the re-execution of the spark_process task and reuse the persisted task output: the processed_penguin_df_cfg Pandas DataFrame.
However, we also defined a validity_period of 1 day for the processed_penguin_df_cfg data node, so Taipy will still re-run the task if the DataFrame was last cached more than a day ago.
3. Building a GUI (main.py)
We'll complete our application by building the GUI which we saw at the beginning of this article:
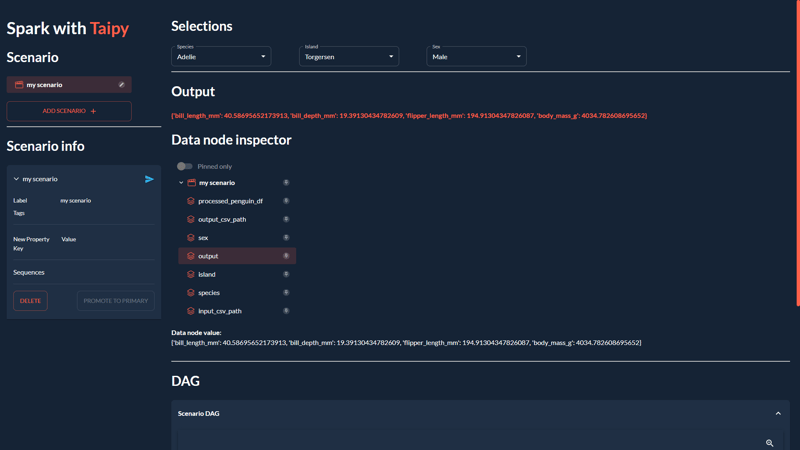
If you're unfamiliar with Taipy's GUI capabilities, you can find a quickstart here.
In any case, you can just copy and paste the following code for app/main.py since it isn't our focus:
### app/main.py
from pathlib import Path
from typing import Optional
import taipy as tp
from config import scenario_cfg
from taipy.gui import Gui, notify
valid_features: dict[str, list[str]] = {
"species": ["Adelie", "Chinstrap", "Gentoo"],
"island": ["Torgersen", "Biscoe", "Dream"],
"sex": ["Male", "Female"],
}
selected_species = valid_features["species"][0]
selected_island = valid_features["island"][0]
selected_sex = valid_features["sex"][0]
selected_scenario: Optional[tp.Scenario] = None
data_dir = Path(__file__).with_name("data")
data_dir.mkdir(exist_ok=True)
def scenario_on_creation(state, id, payload):
_ = payload["config"]
date = payload["date"]
label = payload["label"]
properties = payload["properties"]
# Create scenario with selected configuration
scenario = tp.create_scenario(scenario_cfg, creation_date=date, name=label)
scenario.properties.update(properties)
# Write the selected GUI values to the scenario
scenario.species.write(state.selected_species)
scenario.island.write(state.selected_island)
scenario.sex.write(state.selected_sex.lower())
output_csv_file = data_dir / f"{scenario.id}.csv"
scenario.output_csv_path.write(str(output_csv_file))
notify(state, "S", f"Created {scenario.id}")
return scenario
def scenario_on_submission_change(state, submittable, details):
"""When the selected_scenario's submission status changes, reassign selected_scenario to force a GUI refresh."""
state.selected_scenario = submittable
selected_data_node = None
main_md = """
<|layout|columns=1 4|gap=1.5rem|
<lhs|part|
# Spark with **Taipy**{: .color-primary}
## Scenario
<|{selected_scenario}|scenario_selector|on_creation=scenario_on_creation|>
----------
## Scenario info
<|{selected_scenario}|scenario|on_submission_change=scenario_on_submission_change|>
|lhs>
<rhs|part|render={selected_scenario}|
## Selections
<selections|layout|columns=1 1 1 2|gap=1.5rem|
<|{selected_species}|selector|lov={valid_features["species"]}|dropdown|label=Species|>
<|{selected_island}|selector|lov={valid_features["island"]}|dropdown|label=Island|>
<|{selected_sex}|selector|lov={valid_features["sex"]}|dropdown|label=Sex|>
|selections>
----------
## Output
**<|{str(selected_scenario.output.read()) if selected_scenario and selected_scenario.output.is_ready_for_reading else 'Submit the scenario using the left panel.'}|text|raw|class_name=color-primary|>**
## Data node inspector
<|{selected_data_node}|data_node_selector|display_cycles=False|>
**Data node value:**
<|{str(selected_data_node.read()) if selected_data_node and selected_data_node.is_ready_for_reading else None}|>
<br/>
----------
## DAG
<|Scenario DAG|expandable|
<|{selected_scenario}|scenario_dag|>
|>
|rhs>
|>
"""
def on_change(state, var_name: str, var_value):
if var_name == "selected_species":
state.selected_scenario.species.write(var_value)
elif var_name == "selected_island":
state.selected_scenario.island.write(var_value)
elif var_name == "selected_sex":
state.selected_scenario.sex.write(var_value.lower())
if __name__ == "__main__":
tp.Core().run()
gui = Gui(main_md)
gui.run(title="Spark with Taipy")
Then, from the project folder, you can run the main script like so:
$ taipy run app/main.py
Conclusion
Now that you've seen an example of how to use PySpark with Taipy, go on and try using these two tools to enhance your own data applications!
If you've struggled with other workflow orchestration tools slowing down your work and getting in your way, don't let it deter you from trying Taipy.
Taipy is easy to use and strives to not limit itself in which 3rd party packages you can use it with - its robust and flexible framework makes it easy to adapt it to any data application.

Hope you enjoyed the article!
You can find all the code and data on this repository.


















