
Abstract
This post introduce you Horizontal Pod Autoscaler (HPA) which is the best combination with cluster autoscaler to provide HA for your applications.
Table Of Contents
- What is Horizontal Pod Autoscaler
- Install metric-server
- Create HPA yaml
- Test HPA with cluster autoscaler
- Troubleshoot
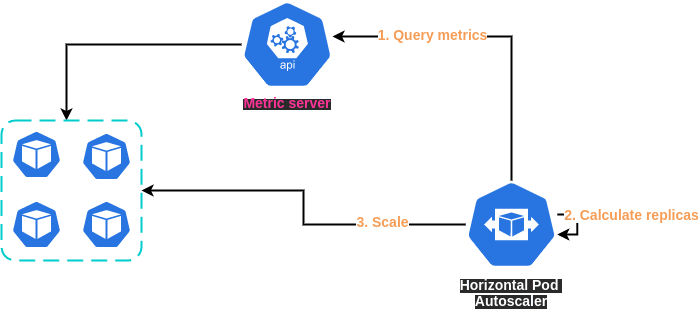
🚀 What is Horizontal Pod Autoscaler (HPA)
The Kubernetes Horizontal Pod Autoscaler automatically scales the number of pods in a deployment, replication controller, or replica set based on that resource's CPU utilization
🚀 Install metric-server
- Metrics Server is a scalable, efficient source of container resource metrics for Kubernetes built-in autoscaling pipelines. These metrics will drive the scaling behavior of the deployments.
- Without metric server you will get
<unknown>metric when trying to add HPA
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app Deployment/app <unknown>/85% 1 2 0 6s
- Describe the HPA and see it is not able to collect metrics
$ kubectl describe hpa app
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedComputeMetricsReplicas 4m5s (x12 over 6m54s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource
cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
Warning FailedGetResourceMetric 111s (x21 over 6m54s) horizontal-pod-autoscaler unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the
requested resource (get pods.metrics.k8s.io)
- There's no metric installed yet
$ kubectl get apiservice|grep metric
- Now we deploy the Metrics Server
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
- Check metric-server and apiService
$ kubectl get deployment metrics-server -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 1/1 1 0 6s
$ kubectl get apiservice|grep metric
v1beta1.metrics.k8s.io kube-system/metrics-server True 92s
- After install metric-server we can apply HPA and use following commands
$ kubectl top nodes
$ kubectl top pods
🚀 Create HPA yaml
Use CDK8S to create k8s yaml files as code. Read more
An exmaple of HPA
from constructs import Construct
from cdk8s import Chart
from imports import k8s
from cdk8s import Chart, App
class AppHpa(Chart):
def __init__(self, scope: Construct, id: str, name_space):
super().__init__(scope, id, namespace=name_space)
app_name = 'app'
app_label = {'dev': app_name}
k8s.KubeHorizontalPodAutoscalerV2Beta2(
self, 'AppHpa',
metadata=k8s.ObjectMeta(labels=app_label, name=app_name),
spec=k8s.HorizontalPodAutoscalerSpec(
max_replicas=2,
min_replicas=1,
scale_target_ref=k8s.CrossVersionObjectReference(
kind="Deployment",
name=app_name,
api_version='apps/v1'
),
metrics=[
k8s.MetricSpec(
type='Resource',
resource=k8s.ResourceMetricSource(
name='cpu',
target=k8s.MetricTarget(type='Utilization', average_utilization=85)
)
)
]
)
)
app = App()
AppHpa(app, "app-hpa")
app.synth()
- Output after running
cdk8s sync
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
dev: app
name: app
namespace: dev8
spec:
maxReplicas: 2
metrics:
- resource:
name: cpu
target:
averageUtilization: 85
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app
🚀 Test HPA with cluster autoscaler
Assume we set the
targetCPUUtilizationPercentageto 10% and use the service then we see it auto scaling a new node (due to resource request MEM of app is high 1000Mi) to serve the new pod
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app Deployment/app 334%/10% 1 2 2 4m32s
$ kubectl get pod |grep app
app-656ff5fcc8-8x875 1/1 Running 0 19h
app-656ff5fcc8-n5htl 0/1 Pending 0 49s
$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-3-162-16.ap-northeast-2.compute.internal Ready <none> 33h v1.19.6-eks-49a6c0
ip-10-3-245-152.ap-northeast-2.compute.internal Ready <none> 2d7h v1.19.6-eks-49a6c0
ip-10-3-249-203.ap-northeast-2.compute.internal Ready <none> 68s v1.19.6-eks-49a6c0
$ kubectl get pod |grep app
app-656ff5fcc8-8x875 1/1 Running 0 19h
app-656ff5fcc8-svkjl 1/1 Running 0 2m9s
- Now we change the
targetCPUUtilizationPercentageto 85% and see if the HPA scaledown the number ofapp
$ kubectl get hpa app
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app Deployment/app 4%/85% 1 2 2 11m
$ kubectl get pod |grep app
app-656ff5fcc8-8x875 1/1 Running 0 19h
$ kubectl get hpa app
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app Deployment/app 5%/85% 1 2 1 12m
🚀 Troubleshoot
- When applying HPA I got the error
failed to get cpu utilization: missing request for cpu
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedComputeMetricsReplicas 10m (x12 over 12m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: missing request for cpu
Warning FailedGetResourceMetric 2m52s (x41 over 12m) horizontal-pod-autoscaler missing request for cpu
$ kubectl get hpa css
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
css Deployment/css <unknown>/85% 1 2 1 13m
- Failing with the metrics is because the POD is not 100% ready... We need to check its
readinessProband either resource request (in my case, I just need to add the resource request to it)
resources:
requests:
cpu: 50m
memory: 100Mi
- The first update, it recreate the pod and got high request
$ kubectl get hpa css
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
css Deployment/css 1467%/85% 1 2 2 4m46s
- It scaleout one more pod and ater the target reduce
$ kubectl get hpa css
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
css Deployment/css 43%/85% 1 2 2 6m22s
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
- Later it removes the pod to meet the expected
$ kubectl get pod -l app=css
NAME READY STATUS RESTARTS AGE
css-5645cb85fd-mtxd6 1/1 Running 0 10m



















