AWS NOW SUPPORTS DELTA LAKE ON GLUE NATIVELY.
CHECK IT OUT HERE:

The purpose of this blog post is to demonstrate how you can use Spark SQL Engine to do UPSERTS, DELETES, and INSERTS. Basically, updates.
Earlier this month, I made a blog post about doing this via PySpark. Check it out below:


But, what if we want it to make it more simple and familiar?
This month, AWS released Glue version 3.0! AWS Glue 3.0 introduces a performance-optimized Apache Spark 3.1 runtime for batch and stream processing. The new engine speeds up data ingestion, processing and integration allowing you to hydrate your data lake and extract insights from data quicker.
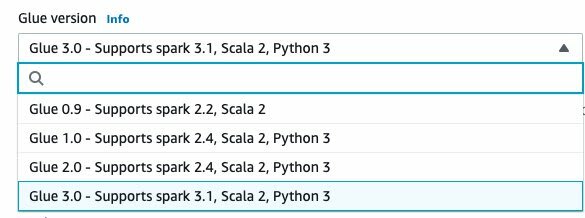

But, what's the big deal with this?
Well, aside from a lot of general performance improvements of the Spark Engine, it can now also support the latest versions of Delta Lake. The most notable one is the Support for SQL Insert, Delete, Update and Merge.
If you don't know what Delta Lake is, you can check out my blog post that I referenced above to have a general idea of what it is.
Let's proceed with the demo!

Table of Contents
✅ Architecture Diagram
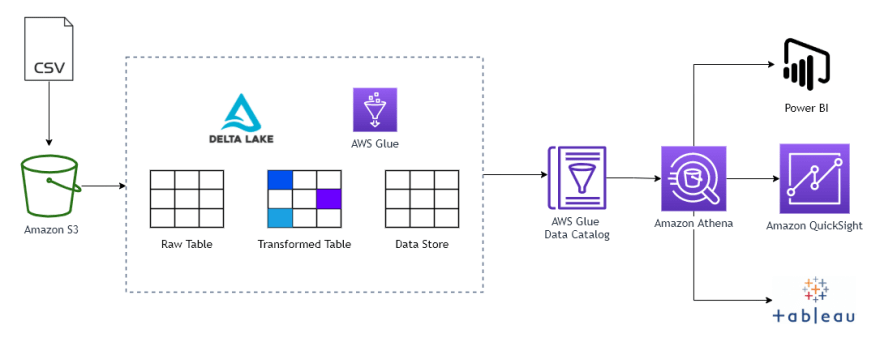
This is basically a simple process flow of what we'll be doing. We take a sample csv file, load it into an S3 Bucket then process it using Glue. (OPTIONAL) Then you can connect it into your favorite BI tool (I'll leave it up to you) and start visualizing your updated data.
❗ Pre-requisites
But, before we get to that, we need to do some pre-work.
- Download the Delta Lake package here - a bit hard to spot, but look for the
Filesin the table and click on thejar - An AWS Account - ❗ Glue ETL is not included in the free tier
- Download the sample data here - you can use your own though, but I'll be using this one
- Codes can be found in my GitHub Repository
✅ Format to Delta Table
First things first, we need to convert each of our dataset into Delta Format. Below is the code for doing this.
# Import the packages
from delta import *
from pyspark.sql.session import SparkSession
# Initialize Spark Session along with configs for Delta Lake
spark = SparkSession \
.builder \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# Read Source
inputDF = spark.read.format("csv").option("header", "true").load('s3://delta-lake-aws-glue-demo/raw/')
# Write data as a DELTA TABLE
inputDF.write.format("delta").mode("overwrite").save("s3a://delta-lake-aws-glue-demo/current/")
# Read Source
updatesDF = spark.read.format("csv").option("header", "true").load('s3://delta-lake-aws-glue-demo/updates/')
# Write data as a DELTA TABLE
updatesDF.write.format("delta").mode("overwrite").save("s3a://delta-lake-aws-glue-demo/updates_delta/")
# Generate MANIFEST file for Athena/Catalog
deltaTable = DeltaTable.forPath(spark, "s3a://delta-lake-aws-glue-demo/current/")
deltaTable.generate("symlink_format_manifest")
### OPTIONAL, UNCOMMENT IF YOU WANT TO VIEW ALSO THE DATA FOR UPDATES IN ATHENA
###
# Generate MANIFEST file for Updates
# updatesDeltaTable = DeltaTable.forPath(spark, "s3a://delta-lake-aws-glue-demo/updates_delta/")
# updatesDeltaTable.generate("symlink_format_manifest")
This code converts our dataset into delta format. This is done on both our source data and as well as for the updates.
After generating the SYMLINK MANIFEST file, we can view it via Athena. SQL code is also included in the repository
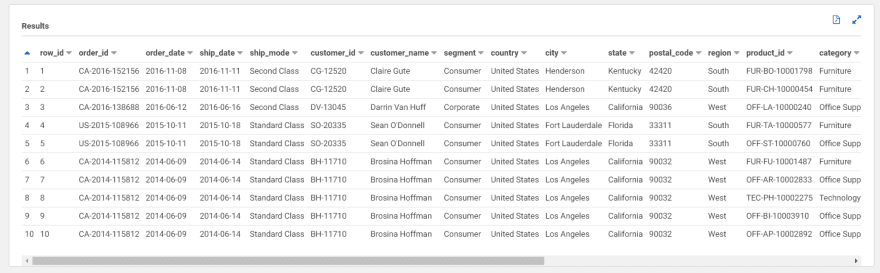
🔀 Upserts
Upsert is defined as an operation that inserts rows into a database table if they do not already exist, or updates them if they do.
In this example, we'll be updating the value for a couple of rows on ship_mode, customer_name, sales, and profit. I just did a random character spam and I didn't think it through 😅.
# Import as always
from delta import *
from pyspark.sql.session import SparkSession
# Initialize Spark Session along with configs for Delta Lake
spark = SparkSession \
.builder \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
updateDF = spark.sql("""
MERGE INTO delta.`s3a://delta-lake-aws-glue-demo/current/` as superstore
USING delta.`s3a://delta-lake-aws-glue-demo/updates_delta/` as updates
ON superstore.row_id = updates.row_id
WHEN MATCHED THEN
UPDATE SET *
WHEN NOT MATCHED
THEN INSERT *
""")
# Generate MANIFEST file for Athena/Catalog
deltaTable = DeltaTable.forPath(spark, "s3a://delta-lake-aws-glue-demo/current/")
deltaTable.generate("symlink_format_manifest")
### OPTIONAL
## SQL-BASED GENERATION OF SYMLINK
# spark.sql("""
# GENERATE symlink_format_manifest
# FOR TABLE delta.`s3a://delta-lake-aws-glue-demo/current/`
# """)
The SQL Code above updates the current table that is found on the updates table based on the row_id. It then proceeds to evaluate the condition that,
If
row_idis matched, thenUPDATE ALLthe data. If not, then do anINSERT ALL.
If you want to check out the full operation semantics of MERGE you can read through this
After which, we update the MANIFEST file again. Note that this generation of MANIFEST file can be set to automatically update by running the query below.
ALTER TABLE delta.`<path-to-delta-table>`
SET TBLPROPERTIES(delta.compatibility.symlinkFormatManifest.enabled=true)
More information can be found here
You should now see your updated table in Athena.
❌ Deletes
Deletes via Delta Lakes are very straightforward.
from delta import *
from pyspark.sql.session import SparkSession
spark = SparkSession \
.builder \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
deleteDF = spark.sql("""
DELETE
FROM delta.`s3a://delta-lake-aws-glue-demo/current/` as superstore
WHERE CAST(superstore.row_id as integer) <= 20
""")
# Generate MANIFEST file for Athena/Catalog
deltaTable = DeltaTable.forPath(
spark, "s3a://delta-lake-aws-glue-demo/current/")
deltaTable.generate("symlink_format_manifest")
### OPTIONAL
## SQL-BASED GENERATION OF SYMLINK MANIFEST
# spark.sql("""
# GENERATE symlink_format_manifest
# FOR TABLE delta.`s3a://delta-lake-aws-glue-demo/current/`
# """)
This operation does a simple delete based on the row_id.
SELECT *
FROM "default"."superstore"
-- Need to CAST hehe bec it is currently a STRING
ORDER BY CAST(row_id as integer);

⤴ Inserts
Like Deletes, Inserts are also very straightforward.
from delta import *
from pyspark.sql.session import SparkSession
spark = SparkSession \
.builder \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
insertDF = spark.sql("""
INSERT INTO delta.`s3a://delta-lake-aws-glue-demo/current/`
SELECT *
FROM delta.`s3a://delta-lake-aws-glue-demo/updates_delta/`
WHERE CAST(row_id as integer) <= 20
""")
# Generate MANIFEST file for Athena/Catalog
deltaTable = DeltaTable.forPath(
spark, "s3a://delta-lake-aws-glue-demo/current/")
deltaTable.generate("symlink_format_manifest")
### OPTIONAL
## SQL-BASED GENERATION OF SYMLINK MANIFEST
# spark.sql("""
# GENERATE symlink_format_manifest
# FOR TABLE delta.`s3a://delta-lake-aws-glue-demo/current/`
# """)
❗ Partitioned Data
We've done Upsert, Delete, and Insert operations for a simple dataset. But, that rarely happens irl. So what if we spice things up and do it to a partitioned data?
I went ahead and did some partitioning via Spark and did a partitioned version of this using the order_date as the partition key. The S3 structure looks like this:
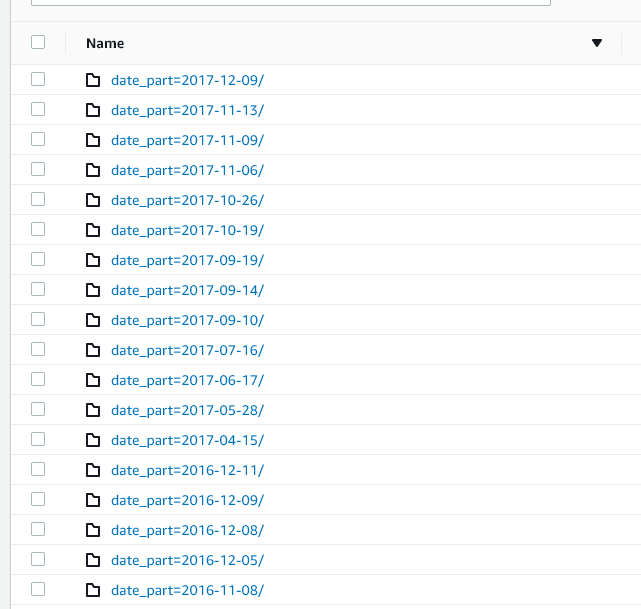
❗ What do you think?
Answer is: YES! You can also do this on a partitioned data.
The concept of Delta Lake is based on log history.
Delta Lake will generate delta logs for each committed transactions.
Delta logs will have delta files stored as JSON which has information about the operations occurred and details about the latest snapshot of the file and also it contains the information about the statistics of the data.
Delta files are sequentially increasing named JSON files and together make up the log of all changes that have occurred to a table.
-from Data Floq
We can see this on the example below
raw date_part=2014-08-27/

current date_part=2014-08-27/ - DELETED ROWS
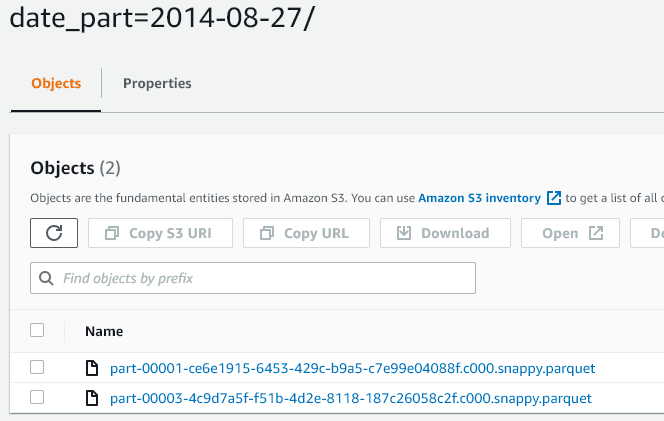
If we open the parquet file:
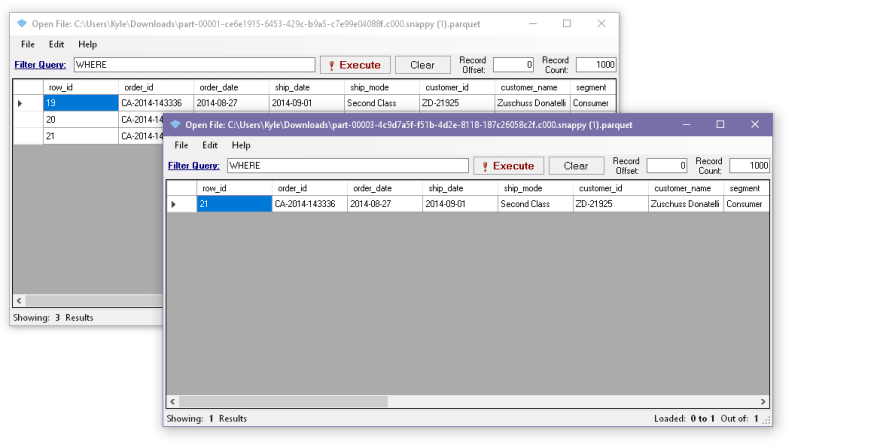
From the examples above, we can see that our code wrote a new parquet file during the delete excluding the ones that are filtered from our delete operation. After which, the JSON file maps it to the newly generated parquet.
Additionally, in Athena, if your table is partitioned, you need to specify it in your query during the creation of schema
CREATE EXTERNAL TABLE IF NOT EXISTS superstore (
row_id STRING,
order_id STRING,
order_date STRING,
ship_date STRING,
ship_mode STRING,
customer_id STRING,
customer_name STRING,
segment STRING,
country STRING,
city STRING,
state STRING,
postal_code STRING,
region STRING,
product_id STRING,
category STRING,
sub_category STRING,
product_name STRING,
sales STRING,
quantity STRING,
discount STRING,
profit STRING,
date_part STRING
)
-- Add PARTITIONED BY option
PARTITIONED BY (date_part STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://delta-lake-aws-glue-demo/current/_symlink_format_manifest/'
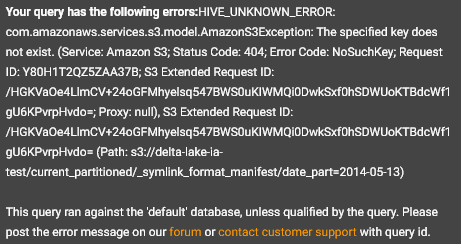
Then run an MSCK REPAIR <table> to add the partitions.
If you don't do these steps, you'll get an error.
✅ Conclusion

That's it! It's a great time to be a SQL Developer! Thank you for reading through! Hope you learned something new on this post.
Have you tried Delta Lake? What tips, tricks and best practices can you share with the community? Would love to hear your thoughts on the comments below!
Happy coding!


















