
In the constantly evolving world of programming, Java remains a steadfast player, adapting to meet the dynamic needs of the software development landscape. Java is a popular and flexible object-oriented programming language used for creating software. Simplicity and reliability makes it an ideal choice for everything from web applications and mobile apps to large-scale enterprise systems.
With the release of Java 21, a new chapter unfolds in Java's journey. Java 21 introduces a host of exciting features and enhancements, promising to reshape the way developers approach their craft. In this blog, we will explore some of the key updates to keep an eye on and effective ways to incorporate them into your daily development practices.
An Overview of the Features
Here are some of the features Java 21 has in store. We'll focus on the big ones, but if you're feeling adventurous and want to dig into the tiny details, check out the official release notes at OpenJDK.

Virtual Threads
Before exploring Virtual threads, let's examine the factors that led to the concept of virtuality in threads.
Java has supported threads from Day 0, distinguishing it from other programming languages by integrating cross-platform concurrency and memory models. Threads enable us to perform multiple tasks simultaneously with sequential code, resulting in an understandable control flow. They provide excellent debugging and error handling serviceability, with comprehensible stack traces. Furthermore, they are the natural unit of scheduling for operating systems.
However, threads can be heavyweight and expensive to create. Given that their stacks are on the scale of megabytes, we can only create a few thousand of them, leading to scalability issues. One solution to this problem is to introduce reactive async frameworks. While these frameworks promise better scaling, they come at a significant cost. They are challenging to debug and yield incomprehensible stack traces, leading to a convoluted programming model.
The best way to handle the issue is by introducing virtual threads. They are lightweight and do not drag around large megabyte-scale data structures. Virtual threads store their stack as delimited continuations in the garbage-collected heap. The stacks are pay-as-you-go, starting with approximately 200-300 bytes and scaling to a million concurrent connections on a decent machine.
Virtual Threads are indeed real threads! They implement java.lang.Thread and support ThreadLocal. They also provide clean stack traces, thread dumps, single-step debugging, and profiling. This means all your threaded code functions as expected. The OpenJDK folks like to call this feature "Threads without the baggage.”
The point of the virtual thread is not to make the applications run faster but rather will make them scale better. In most server applications, most requests spend their time waiting for I/O operations, like I/O on a socket, file or database. If we program using a comfortable thread per task model, as most of the tasks are waiting on I/O eventually we run out of threads before we run out of CPU, this effectively raises the cost of the application as we would need more free memory.
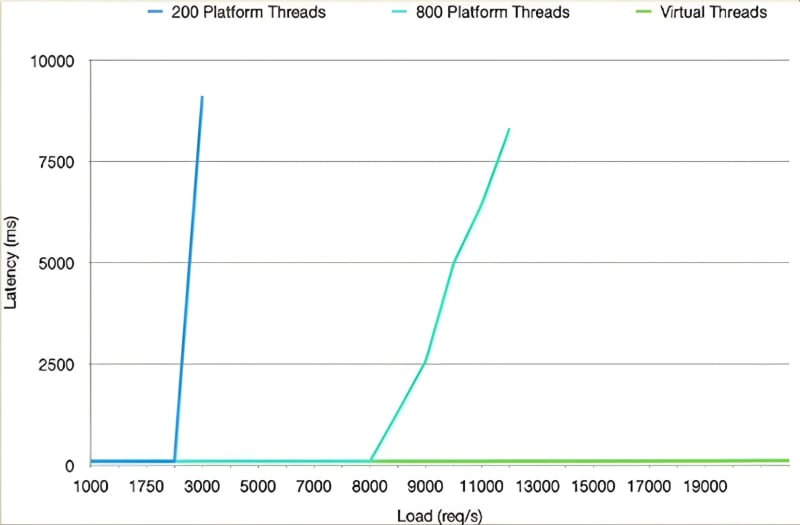
The above graph illustrates the advantages of using virtual threads in Java 21. Say we have some I/O bound task in the thread pool, the blue line represents the thread pool with 200 threads. Initially, as the application's load increases, the latency remains manageable. However, when all the threads are engaged, the latency begins to fall apart. Attempting to address this by increasing the number of threads in the pool, as indicated by the greenish-blue line, eventually will end up in the same scenario as before, you hit the bottle-neck of how many threads you can have before you run out of the CPU, and latency falls again.
In contrast, virtual threads are depicted by the green line. They exhibit a distinctive behavior, running seamlessly along the x-axis without hitting the same bottleneck as traditional threads. Virtual threads continue to execute efficiently until they encounter CPU resource limitations, at which point latency starts to increase. This innovation in Java 21 offers a more robust and scalable solution for managing concurrency.
Virtual threads differ from conventional concurrency as they are designed to model a single task, not a mechanism for running tasks. So, trying to pool them isn't the right way to go. Instead, it's quite affordable to create a separate thread for each user request or an asynchronous task. This approach follows the "one thread per request" model and still scales well.
Virtual threads are a way to make the most of your resources and handle multiple tasks effectively in Java 21.
New Paradigm: Structured Concurrency
Java 21 has simplified concurrent programming by introducing an API for structured concurrency.
Structured concurrency has been a well-explored concept in the Python and C++ communities for some time. In contrast, Java has recently acknowledged its significance, introducing it as a preview feature in Java 21. We'll look into the steps for utilizing these preview features in a later discussion.
Structured concurrency is a concept that simplifies concurrent programming by treating groups of related tasks running in different threads as a single unit of work. This approach streamlines error handling and cancellation processes, leading to improved reliability and enhanced observability. Promoting this style of concurrent programming, eliminates common risks arising from cancellation and shutdown, such as thread leaks and cancellation delays making Java 21 more automated than the previous versions.
The fundamental idea behind structured concurrency is straightforward: it ensures that when a control flow divides into multiple concurrent tasks, they must rejoin within the same lexical scope. In other words, the parent task needs to wait for its children to complete their work. The success of this concurrency model is largely attributed to the implementation of virtual threads, which makes managing threads more cost-effective.
Let’s have a look at how to effectively use the structured concurrency API with the help of an example, consider a method, handle(), that represents a task in a server application. It handles an incoming request by executing two subtasks. One subtask executes the method findUser() and the other subtask executes the method fetchOrder(). The handle()method awaits the subtasks' results via blocking calls to their future get() methods, so the task is said to join its subtasks.
Let's first examine how to implement this method using unstructured concurrency with the ExecutorService API provided in java.util.concurrent.ExecutorService.
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = esvc.submit(() -> findUser());
Future<Integer> order = esvc.submit(() -> fetchOrder());
String theUser = user.get(); // Join findUser
int theOrder = order.get(); // Join fetchOrder
return new Response(theUser, theOrder);
}
Because the subtasks execute concurrently, each subtask can succeed or fail independently. Often, a task such as handle() should fail if any of its subtasks fail.
The lifetimes of the threads is complicated whenever a failure occurs:
- If
findUser()throws an exception thenhandle()will throw an exception when callinguser.get()butfetchOrder()will continue to run in its own thread. This is a thread leak that, at best, wastes resources; at worst, thefetchOrder()thread will interfere with other tasks. - If the thread executing
handle()is interrupted, the interruption will not propagate to the subtasks. Both thefindUser()andfetchOrder()threads will leak, continuing to run even afterhandle()has failed. - If
findUser()takes a long time to execute, butfetchOrder()fails in the meantime, thenhandle()will wait unnecessarily forfindUser()by blocking onuser.get()rather than cancelling it. Only afterfindUser()completes anduser.get()returns willorder.get()throw an exception, causinghandle()to fail.
In each case, the problem is that our program is logically structured with task-subtask relationships, but these relationships exist only in the developer's mind.
This not only creates more room for error, but it makes diagnosing and troubleshooting such errors more difficult.
In the above handle() method, the failure of fetchOrder() cannot automatically cause the cancellation of findUser(). The future for fetchOrder() is unrelated to the future for findUser(), and neither is related to the thread that will ultimately join it via its get() method. Rather than developers managing such cancellations manually, structured concurrency reliably automates it.
Now let’s look at how the same method can be implemented using structured concurrency.
The principal class of the structured concurrency API is StructuredTaskScope in the java.util.concurrent package.
Here is the handle() example from earlier, written to use StructuredTaskScope with one of its subclass ShutdownOnFailure
Response handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<String> user = scope.fork(() -> findUser());
Supplier<Integer> order = scope.fork(() -> fetchOrder());
scope.join() // Join both subtasks
.throwIfFailed(); // ... and propagate errors
// Here, both subtasks have succeeded, so compose their results
return new Response(user.get(), order.get());
}
}
In contrast to the original example, understanding the lifetimes of the threads involved here is easy: Under all conditions their lifetimes are confined to a lexical scope, namely the body of the try-with-resources statement.
The use of StructuredTaskScope ensures a number of valuable properties:
-
Error handling with short-circuiting - If either the
findUser()orfetchOrder()subtasks fail, the other is canceled if it has not yet completed, which is managed by the shutdown policy throughShutdownOnFailure. -
Cancellation propagation - If the thread running
handle()is interrupted before or during the call tojoin(), both subtasks are canceled automatically when the thread exits the scope. - Clarity - The above code has a clear structure: Set up the subtasks, wait for them to either complete or be canceled, and then decide whether to succeed (and process the results of the child tasks, which are already finished) or fail (and the subtasks are already finished, so there is nothing more to clean up).
-
Observability - A thread dump, clearly displays the task hierarchy, with the threads running
findUser()andfetchOrder()shown as children of the scope.
Generational ZGC (Z Garbage Collector)
Java 21 improves application performance by extending the Z Garbage Collector to maintain separate generations for young and old objects. This will allow ZGC to collect young objects — which tend to die young — more frequently.
The Z garbage collector is designed for low latency and high scalability and was introduced in JDK 15 by providing a Terabytes-scale sized heap with sub-millisecond pauses, where the pauses do not scale with heap size or live-set. It had almost all the features one could expect in a modern garbage collector such as Concurrent, Parallel, Auto-tuning, Compacting, Region-based, and Numa-Aware with an upshot being not to worry about the GC pauses. However, it's essential to note that these benefits come at a cost, resulting in approximately a 2% reduction in throughput and increased memory utilization.
ZGC was a single-generation garbage collector until Java 21 introduced the generational capability. The new Generational ZGC maintains the same level of throughput while requiring significantly less memory. In practical terms, when conducting an Apache Cassandra benchmark, Generational ZGC only needs a quarter of the heap size. Yet, it attains four times the throughput compared to the non-generational ZGC. Importantly, it manages to achieve this while maintaining pause times under one millisecond.
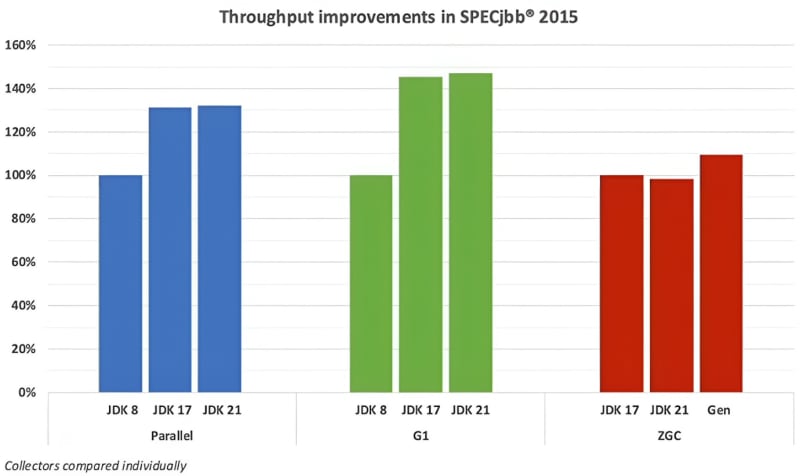
The improvements aren't limited to just the ZGC algorithm, there have also been noticeable enhancements in the Parallel and G1 collectors. These improvements are evident when comparing them with their performance in JDK 17 and 8.
Unnamed Classes and Instance Main Methods
I remember the first time I attempted to write the "Hello World" program in Java. It took me nearly 5 minutes just to transcribe it from the book, as I initially struggled to grasp the concept. I'm confident that anyone, from those learning Java for the first time to seasoned experts, may have had a similar experience. However, with the introduction of Java 21, that learning curve is set to undergo a transformation. Beginners can now write streamlined declarations for single-class programs and then seamlessly expand their programs to use more advanced features as their skills grow.
This was the classic Hello World program that I wrote for the first time in Java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
And this would be the Hello World program that someone just starting to learn Java would be writing in Java 21
void main() {
System.out.println("Hello, World!");
}
Firstly, Java 21 comes with an enhanced protocol by which Java programs are launched to allow instance main methods. Such methods are not static, need not be public, and need not have a String[] parameter.
Secondly, it introduces unnamed classes to make the class declaration implicit.
When launching a Java class, the launch protocol follows a specific order to determine which method to invoke:
- It first looks for a
static void main(String[] args)method in the launched class with non-private access (public, protected, or package-private). - If the above method is not found, it checks for a
static void main()method with non-private access in the launched class. - If neither of the static methods exists, it searches for a
void main(String[] args)instance method with non-private access declared in the launched class or inherited from a superclass. - Finally, if none of the above methods is present, it looks for a
void main()instance method with non-private access declared in the launched class or inherited from a superclass.
Note that this is a change of behavior: If the launched class declares an instance main, that method will be invoked rather than an inherited "traditional" public static void main(String[] args) declared in a superclass. Therefore, if the launched class inherits a "traditional" main method but another method (i.e. an instance main) is selected, the JVM will issue a warning to the standard error at runtime.
If the selected main is an instance method and is a member of an inner class, the program will fail to launch.
An unnamed class is situated within the unnamed package, which, in turn, resides in the unnamed module. Although there is only one unnamed package (unless multiple class loaders are involved) and only one unnamed module, the unnamed module can contain multiple unnamed classes. Each unnamed class includes a main method, essentially making it a program. Therefore, the presence of multiple such unnamed classes within the unnamed package equates to multiple distinct programs.
In many ways, an unnamed class is quite similar to an explicitly declared class. It can have members with the same modifiers, like private and static, and these modifiers have the same default behaviors, such as package access and instance membership. However, a significant distinction lies in the fact that while an unnamed class automatically possesses a default zero-parameter constructor, it cannot have any other constructors.
Since this is a feature in preview mode, it is disabled by default. To enable preview features in JDK 21, let's consider the example with the same "Hello World" program we discussed earlier.
If you have a file named HelloWorld.java with the following code:
void main() {
System.out.println("Hello, World!");
}
When you try to compile it in the usual way using javac HelloWorld.java, you'll encounter the following error:
error: unnamed classes are a preview feature and are disabled by default
To enable preview features, you need to compile the program with the following command:
javac --release 21 --enable-preview HelloWorld.java
And when running the program, you should use: java --enable-preview HelloWorld This enables the use of the preview feature in your Java program.
Conclusion
When we consider the updates that Java 21 has brought to the community, we can confidently say that migrating to Java 21 does not pose a significant risk of breaking things. Unlike the upgrade from Java 8 to Java 11, where issues arose immediately, these latest versions have undergone extensive testing and updates through a series of intermediate releases.
Having said that, the Java 21 environment is still in development, but it's expected to be ready in the near future.
These are just a few of the noteworthy features introduced in Java 21. With each new release, Java continues to evolve and provide developers with powerful tools to write cleaner, more efficient, and more expressive code. Whether it's pattern matching, virtual threads, sealed classes, structured concurrency, or the generational ZGC, these features significantly benefit developers and make Java an even more compelling choice for building robust and scalable applications.
I would also suggest exploring more in-depth blogs authored by experts on each of these features at Inside Java.
So, what are you waiting for? Upgrade to Java 21 and start exploring these exciting features today!


















