
Have you ever wondered how to make your web design stand out? Have you encountered any challenges when incorporating unique symbols into your projects? Unicode in HTML is a helpful tool for such situations. It provides various symbols and characters to give your website a fancy look.
The assortment of unique characters allows web designers to create incredible digital artwork. You can make your website look extra special by including these fun characters in your HTML code. It will add personality to your content and make it more engaging for your audience.
This article will discuss how to incorporate Unicode in HTML into your website. It will cover everything from benefits to the best practices for how to use Unicode in HTML.
What is Unicode in HTML?
HTML Unicode is often called "Unicode character encoding" or simply "Unicode." It helps in representing special characters and symbols in your HTML documents. These characters could be symbols, emojis, mathematical operators, or currency signs. HTML Unicode characters are particularly useful when representing characters not available on standard keyboards.
Also, they represent characters not available in the limited ASCII character set. It helps eliminate issues where specific devices might not render non-standard characters correctly. Below are some examples of HTML Unicode:

Unicode in HTML relies on the Unicode standard established by the Unicode Consortium. The Unicode Consortium provides a comprehensive and universally accepted character encoding system. It covers many characters from all the main writing scripts, like Latin, Chinese, and many more. It is the foundation for HTML Unicode, giving each character its unique code.
Thus, it ensures consistent character encoding and displays across different devices. In general, it guarantees accessibility, multilingual support, and interoperability in digital communication.
Overview of Popular Character Encoding Systems
Unicodes are universally supported standardized character encoding systems. It supports over 100,000 characters from all the main writing systems around the globe. These characters include Latin, Greek, Cyrillic, Chinese, Japanese, Arabic, and many more. Thus, it enables the creation of texts in any language and their accurate display on any device.
Unicode represents characters by assigning a unique numeric code point to each character. HTML documents typically represent these code points using hexadecimal formats. It makes it possible to specify the code point value with a predetermined number of digits. For instance, the Unicode code point for the Arabic numeral "5" is "U+0035". The hexadecimal notation value for this is "5". Similarly, the code point for the Greek letter "Δ" (Delta) is "U+0394".
A code point is a number that identifies a character regardless of its encoding scheme. These encoding schemes let you use various Unicode characters, scripts, and emojis. The following are the primary encoding systems for Unicode characters:
UTF-8
UTF-8 stands for Unicode Transformation Format - 8-bit. It is a variable-length encoding scheme used to represent Unicode characters. UTF-8 is the most widely used encoding scheme online and in most modern operating systems. It uses a variable number of bytes (8 bits each) to define characters based on their Unicode code points. Thus, it can display the whole Unicode character set, like emoji, scripts, and math symbols.
UTF-16
UTF-16 stands for Unicode Transformation Format - 16-bit. It is a fixed-length encoding scheme that uses the same number of bytes for each character. Windows systems and programming languages like JavaScript often use UTF-16. A 16-bit code unit in UTF-16 represents characters in the Basic Multilingual Plane (BMP). The BMP forms the basis of the Unicode character set used in various languages. UTF-16 uses two 16-bit units (surrogate pairs) for characters outside the BMP, e.g., most emojis. It allows UTF-16 to support multiple characters, including those outside the BMP.
UTF-32
UTF-32 stands for Unicode Transformation Format - 32-bit. UTF-32 is a fixed-length encoding scheme that uses 32-bit to represent Unicode characters. A single 32-bit code unit represents every character, even outside the BMP. UTF-32 is not the most popular for encoding characters, but Unix and Linux systems often use it. UTF-32 provides a direct one-to-one mapping between code points and encoded values. It simplifies text processing and indexing but consumes more memory than other encodings.
The <meta> tag in the <head> section specifies the character encoding details in HTML. It helps different browsers correctly interpret character references, improving compatibility and consistency. Also, it can improve your SEO as it allows search engines to index and understand your content better.
In the <head> section, you specify the character encoding as follows:
<head>
<meta charset="UTF-8">
</head>
Note: It should be <meta charset="UTF-8"> with "UTF-8" in uppercase, not lowercase. Also, the choice of encoding scheme depends on what the application requires. UTF-8, for example, is ideal if the application needs to run on a wide variety of software platforms. For Windows-based applications, UTF-16 is the better option, and so on. Learn more about encoding schemes.
How HTML Unicodes represent characters and symbols
There are two standard methods for representing Unicode in HTML documents:
- Numeric character references (NCRs).
- Named character references.
Numeric Character References (NCRs)
HTML documents commonly use numeric character references (NCRs) to represent Unicode characters. Numeric character references represent Unicode characters by the code points associated with them. Character references typically express these code points in hexadecimal or decimal notation.
With NCRs, you can include various characters and symbols in your HTML documents. It's versatile and lets you use symbols like emojis, which you can't find on regular keyboards.
Two types of numeric character references are available in HTML. One is for hexadecimal numbers, and the other is for decimal numbers, each with a different syntax:
&#xnnnn; // Hexadecimal Numeric Character References
&#nnnn; // Decimal Numeric Character References
Here's a breakdown of the syntax:
- "&": The "&" symbol is an ampersand. It represents the start of an HTML entity or numeric character reference in HTML.
- "#": The hash "#" symbol indicates the start of a numeric character reference.
- "x": There may or may not be an "x" (in lowercase) after the hash symbol, depending on the notation. The "x" symbol shows that the subsequent digits are in hexadecimal (base-16) notation. The numbers 0 to 9 in hexadecimal are the same as 0 to 9 in decimal notations, while A-F stands for 10 to 15. However, the 'x' symbol is specific to hexadecimal and not decimal (base-10) notations.
- "nnnn": A four-digit hexadecimal or decimal number, "nnnn", represents a Unicode code point. These code points enable you to include your desired character in your HTML document.
Here are some examples of Unicode character codepoints:
- U+00A9 represents the copyright symbol "©"
- U+2764 represents the heart emoji “❤️”
- U+2191 represents the up arrow symbol “↑”
- U+2193 represents the down arrow symbol “↓”
- U+1F44D represents the thumbs-up emoji “👍”
- U+0394 represents the Greek letter "Δ" which means Delta
- U+0394 represents the Chinese symbol "福," which means "luck" or "blessings"
- U+0414 represents the Cyrillic symbol "Д," which means the Cyrillic capital letter "De"
Let's assume, for example, you want to include the copyright symbol "©" with a code point of "U+00A9" in your HTML document. You would represent it using the hexadecimal NCR like this:
<!-- Using NCR with hexadecimal notation -->
<p>Copyright symbol: © indicates content protection</p>
<!-- or -->
<p>Copyright symbol: © indicates content protection</p>
Note that numeric character references can omit zeros at the beginning of the code point. Thus, the copyright hexadecimal can look like © with the zeros or © without the zeros. The leading zeros guarantee that the code point has a fixed four-digit number.
However, they are unnecessary as the hexadecimal format specifies the code point already. Also, the omission of leading zeros is specific to NCRs in HTML. Other encoding systems may need it for proper representation.
Also, you can write the numeric character reference using decimal notation like this:
<!-- Using NCR with decimal notation -->
<p>Copyright symbol: © indicates content protection</p>
Both will render as:
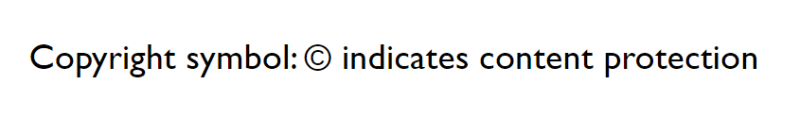
In the above example, the hexadecimal and decimal NCRs used the formulas &#xnnnn; and &#nnnn;. The hexadecimal NCR begins with "&#," followed by "x," the character's code point (00A9), and then "; ". Also, the decimal NCR starts with "&#" and then the decimal code point of the character (169) and the ";".
To add the up arrow “↑” symbol to your web page, use the following NCR:
<!-- Using NCR with hexadecimal notation -->
<p>You can access the higher floor using the elevator panel's up arrow symbol ↑.<p>
<!-- Using NCR with decimal notation -->
<p>You can access the higher floor using the elevator panel's up arrow symbol ↑.<p>
Both will render as:

To add the love “❤️” emoji to your web page, use the following NCR:
<!-- Using NCR with hexadecimal notation -->
<p>I love ❤ writing HTML codes<p>
<!-- Using NCR with decimal notation -->
<p>I love ❤ writing HTML codes<p>
Both will render as:

To add the down arrow “↓” symbol to your web page, use the following NCR:
<!-- Using NCR with hexadecimal notation -->
<p>Scroll down the webpage by clicking the down arrow symbol ↓ on your keyboard.<p>
<!-- Using NCR with decimal notation -->
<p>Scroll down the webpage by clicking the down arrow symbol ↓ on your keyboard.<p>
Both will render as:

To add the Chinese "福" symbol to your web page, use the following NCR:
<!-- Using NCR with hexadecimal notation -->
<p>During Chinese New Year, people often hang the symbol 福 on their doors for good luck.</p>
<!-- Using NCR with decimal notation -->
<p>During Chinese New Year, people often hang the symbol 福 on their doors for good luck.</p>
Both will render as:

Note: You can represent the code point in hexadecimal or decimal form, whatever you prefer. The most typical format for Unicode code points, though, is hexadecimal. Also, you can use character references in any part of your HTML, like the <body>, <head>, or in element attributes. Access a comprehensive table of numeric character references and their Unicode code points.
Named Character References
Named character references are sequences of characters that represent a single Unicode character. They are a more readable substitute for Numeric character references (NCRs). It uses significant character names, making it easy to understand the intended symbols. Instead of numeric code points, you can use specific names to refer to characters and symbols. Examples of these character names include ampersand (&), less than (<), greater than (>), and more.
Named character references are well-documented and adhered to as part of web standards. Major web browsers like Chrome, Firefox, and others extensively support named character references. They give character entities a consistent representation, ensuring accurate display across all platforms. Named character references are thus a stable and supported feature for web developers.
Using named character references in HTML requires the following syntax:
&entity_name;
- "&": The "&" symbol is an ampersand. In HTML, it represents the beginning of a character reference.
- "entity_name": An "entity_name" is a predefined name for a character HTML recognizes.
- ";": The semicolon (;) signifies the end of the character reference. It ensures proper code syntax, character rendering, and code consistency. Not including the semicolon can cause parsing and rendering problems.
Here are some more examples of named character references:
- "©" represents the copyright symbol (©)
- "↑" or "↑" represents the up arrow symbol (↑)
- "↓" or "↓" represents the down arrow symbol (↓)
- "&" represents the ampersand character (&)
- "™" represents the trademark symbol (™)
- "<" represents the less than symbol (<)
- ">" represents the greater than symbol (>)
- "£" represents the British pound symbol (£)
- "€" represents the Euro symbol (€)
Note: Emojis do not have widely recognized named character references in HTML. It is vital to use their numeric Unicode code points for consistent rendering. Using your on-screen or emoji keyboards, you can also insert emojis in your HTML document.
Here are some examples of including named character references in your HTML document:
To add the copyright “©” symbol to your web page, use the following named character reference:
<p>Copyright symbol: © indicates content protection</p>
It will render as:
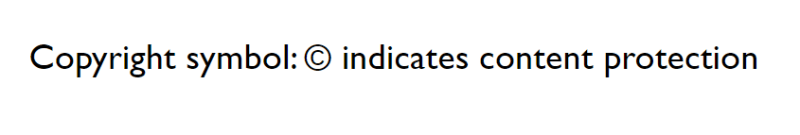
To add the British pound symbol “£” to your web page, use the following named character reference:
<p>The British pound symbol £ denotes currency in the United Kingdom</p>
It will render as:

To add the greater than symbol ">" to your web page, use the following named character reference:
<p>The greater than symbol > denotes anything greater or more than another.<p>
It will render as:

It is important to note that named character references are case-sensitive. For example, © and &Copy; will render differently. One will appear correctly, while the other will only appear as plain text. Thus, you must ensure you use the correct letter case, whether upper or lower. Unicode's versatility also makes it easy to use in JavaScript and CSS. So, you can style Unicode characters like any other element on your website.
You can use named and numeric character references anywhere in your HTML document. This decision mostly depends on personal preference and code readability. However, it is better to use named character references as they are easier to read and maintain. For a comprehensive table of named and numeric character references, click here.
Benefits of Using HTML Unicodes in Web Development
Unicode in HTML offers several benefits that enhance a web content's functionality. The following are the main benefits of using HTML Unicode:
- Improved SEO: Using HTML Unicode can help your web pages rank higher in search engines. For search engine optimization (SEO), search engines consider the language of a website. You can use Foreign language characters in HTML Unicodes to create multilingual websites. In this way, your web pages will rank higher in search results for users who speak those languages. For example, adding Chinese characters to your website can help attract Chinese-speaking customers. It will give you a boost in search results for Chinese keywords and help you reach more people.
- Multilingual Support: Unicode provides a universal way of representing characters from different languages. It supports over 135 languages, making it possible to display text in any language on the web. Thus, it is vital for websites that cater to a diverse international audience.
- Compatibility: Unicode HTML is compatible with modern web browsers and web technologies. As a result, your web content will be accessible to all users regardless of their browser of choice.
- Visual appeal: Using Unicode in HTML, you can add symbols to your web pages to make them look even better. For example, you can use arrows to create menus for navigation, star ratings to check reviews, and more. It offers a ton of symbols, icons, and characters to make your web stuff look more visually engaging.
- Enhanced Accessibility: HTML Unicode enhances website accessibility, benefiting users with disabilities. The use of accents and unique HTML Unicode symbols to represent characters improves web accessibility. As a result, web pages will be more accessible and readable for people with disabilities. By correctly encoding characters, assistive technology users can interpret web content more easily. A screen reader, for example, can provide access to web pages for people who are blind or have low vision.
Best Practices for Using HTML Unicode Characters
Some of the best practices for using Unicode characters in HTML are as follows:
- Use Appropriate Encoding: The correct character encoding scheme is crucial for HTML documents. One of the most widely used character encodings for web content is UTF-8. It can depict characters from almost all scripts and languages used today. Many web technologies and programming languages use it as their default encoding scheme. It promotes compatibility, multilingual support, and accurate character rendering.
- Use named character references: Use named character references for Unicode characters whenever possible. Named character references are more readable, maintainable, and easy to understand.
-
End with Semicolons: Adding a semicolon at the end of character references is vital. It separates it from regular text and denotes the end of the character reference. Character references without semicolons can lead to rendering issues on your web page. For example,
©is a valid character reference, but©without the semicolon is not. Correctly formatting character references is essential for ensuring consistency in your web content. - Ensure Browser Support: Consider browser compatibility when using Unicode characters on your website. The handling of Unicode characters may differ across web browsers. Thus, it is vital to consider browser compatibility when using Unicode characters in HTML. For instance, older browsers may not support or display newer Unicode characters correctly. Modern browsers support Unicode, but testing your content to ensure consistency is essential.
Conclusion
HTML Unicodes are a versatile tool that goes beyond mere symbols. They can help overcome language barriers and communicate powerful messages through visuals. With Unicode in HTML, you can display text and characters in various languages. Thus, it makes it possible to build web pages that are informative and accessible to everyone.
If you enjoyed this article, the following resources will be helpful to you:


















