Last week, Google announced the public beta of the Ruby runtime for Cloud Functions, Google’s functions-as-a-service (FaaS) hosting platform. Ruby support has lagged a bit behind other languages over the past year or so, but now that we’ve caught up, I thought I’d share some of the design process behind the product.
This article is not a traditional design document. I won’t go through the design itself step-by-step. Instead, I want to discuss some of the design issues we faced, the decisions we made, and why we made them, because it was an interesting exercise in figuring out how to fuse Ruby conventions with those of the public cloud. Some of the trade-offs we made are, I think, emblematic of the challenges the Ruby community as a whole is facing as the industry evolves.
A Ruby way of doing serverless
Bringing Ruby support to a serverless product is a lot more involved than you might expect. At the most basic level, a language runtime is just a Ruby installation, and sure, it’s not hard to configure a Ruby image and install it on a VM. But things become more complex when you bring “serverless” into the mix. Severless is much more than just automatic maintenance and scaling. It’s an entirely different way of thinking about compute resources, one that goes contrary to much of we’ve been taught about deploying Ruby apps for the past fifteen years. When the Ruby team at Google Cloud took on the task of designing the Ruby runtime for Cloud Functions, we were also taking on the daunting task of proposing a Ruby way of doing serverless. While remaining true to the Ruby idioms, practices, and tools familiar to our community, we also had to rethink how we approach web application development at almost every level, from code, to dependencies, persistence, testing, everything.
This article will examine our approach to five different aspects of the design: function syntax, concurrency and lifecycle, testing, dependencies, and standards. In each case, we’ll see a balance between the importance of remaining true to our Ruby roots, and the desire to embrace the new serverless paradigms. We tried very hard to maintain continuity with the traditional Ruby way of doing things, and we also took cues from other Google Cloud Functions language runtimes, as well as precedents set by serverless products from other cloud providers. However, in a few cases, we chose to blaze a different trail. We did so when we felt that current approaches either abused a language feature, or were misleading and encouraged the wrong ideas about serverless app development.
It’s possible, even likely, that some of these decisions will eventually prove to have been wrong. That’s why I’m offering this article now, to discuss what we’ve done and to start the conversation about how we as the Ruby community practice serverless app development. The good news is that Ruby is a very flexible language, and we will have plenty of opportunity to adapt as we learn and as our needs evolve.
So let’s take a look at some of the initial design decisions and trade-offs we made and why we made them.
Functional Ruby
“Functions-as-a-Service” (FaaS) is currently one of the more popular serverless paradigms. Google’s Cloud Functions is just one implementation. Many other major cloud providers have their own FaaS product, and there are open source implementations as well.
The idea, of course, is to use a programming model centered not around web servers, but around functions: stateless pieces of code that take input arguments and return results. It seems like a simple, almost obvious, change in terminology, but it actually has profound implications.

The first challenge for Ruby is that, unlike many other programming languages, Ruby actually doesn’t have first-class functions. Ruby is first and foremost an object-oriented language. When we write code and wrap it in a def, we are writing a method, code that runs in response to a message sent to an object. This is an important distinction, because the objects and classes that form the context of a method call are not part of the serverless abstraction. So their presence can complicate a serverless application, and even mislead us when we’re writing it.
For example, some FaaS frameworks let you write a function with a def at the top level of a Ruby file:
def handler(event:, context:)
"Hello, world!"
end
While this code appears straightforward, it’s important to remember what it actually does. It adds this “function” as a private method on the Object class, the base class of the Ruby class hierarchy. In other words, the “function” has been added to nearly every object in the Ruby virtual machine. (Unless, of course, the application changes the main object and class context when loading the file, a technique that carries other risks.) At best, this breaks encapsulation and single responsibility. At worst, it risks interfering with the functionality of your application, its dependencies, or even the Ruby standard library. This is why such “top level” methods, while common in simple single-file Ruby scripts and Rakefiles, are not recommended in larger Ruby applications.
The Google Ruby team decided this issue was serious enough that we chose a different syntax, writing functions as blocks:
require "functions_framework"
FunctionsFramework.http("handler") do |request|
"Hello, world!"
end
This provides a Ruby-like way to define functions without modifying the Object base class. It also has a few side benefits:
- The name (“handler” in this case) is just a string argument. It doesn’t need to be a legal Ruby method name, nor is there any concern of it colliding with a Ruby keyword.
- Blocks exhibit more traditional lexical scoping than do methods, so this will behave more similarly to functions in other languages.
- The block syntax makes it easier to manage function definitions. For example, it’s possible to “undefine” functions cleanly, which is important for testing.
Of course, there are trade-offs. Among them:
- The syntax is slightly more verbose.
- It requires a library to provide the interface for defining functions as blocks. (Here, Ruby follows other language runtimes for Cloud Functions by utilizing a Functions Framework library.)
We decided it was worth these trade-offs for the goal of properly distinguishing functions.
To share or not to share
Concurrency is hard. This is one of the key observations underlying the design of serverless in general, and functions-as-a-service in particular: that we live in a concurrent world and we need ways to cope. The functional paradigm addresses concurrency by insisting that functions not share state (except through an external persistence system such as a queue or database).
This is in fact another reason we chose to use block syntax rather than method syntax. Methods imply objects, which carry state in the form of instance variables, state that might not work as expected in a stateless FaaS environment. Eschewing methods is a subtle but effective syntactic way to discourage practices we know to be problematic.
That said, what if you need to share resources, such as database connection pools? When would you initialize such resources, and how would you access them?
For this purpose, the Ruby runtime supports startup functions that can initialize resources and passes them into function calls. Importantly, while the startup function can create resources, normal functions can only read them.
require "functions_framework"
# Use an on_startup block to initialize a shared client and store it in
# the global shared data.
FunctionsFramework.on_startup do
require "google/cloud/storage"
set_global :storage_client, Google::Cloud::Storage.new
end
# The shared storage_client can be accessed by all function invocations
# via the global shared data.
FunctionsFramework.http "storage_example" do |request|
bucket = global(:storage_client).bucket "my-bucket"
file = bucket.file "path/to/my-file.txt"
file.download.to_s
end
Notice that we chose to define special methods global and set_global to interact with global resources. (By the way, these are not methods on Object, but methods on a specific class we use as the function context.) Again, we could have used more traditional idioms such as Ruby global variables, or even a constructor and instance variables, to pass information from startup code to function calls. However, those idioms would have communicated the wrong things. We’re not writing ordinary Ruby classes and methods where sharing data is normal, but serverless functions where sharing data is hazardous if even possible, and we felt it was important for the syntax to emphasize the distinction. The special methods were a deliberate design decision, to discourage practices could be dangerous in the presence of concurrency.
Test first
A strong testing culture is central to the Ruby community. Popular frameworks, such as Rails, acknowledge this and encourage active testing by providing testing tools and scaffolding as part of the framework, and the Ruby runtime for Google Cloud Functions follows suit by providing testing tools for serverless functions.
The FaaS paradigm actually fits very well with tests. Functions are by nature easily testable; simply pass in arguments and assert against results. In particular, you don’t need to spin up a web server to run tests, because web servers are not part of the abstraction. The Ruby runtime provides a module of helper methods for creating HTTP request and Cloud Event objects to use as inputs, and otherwise most tests are very straightforward to write.
One of the main testing challenges we encountered, though, had to do with testing initialization code. Indeed, this is an issue that some of Google’s Ruby team members have had with other frameworks, including Rails: it is difficult to test an app’s initialization process, because framework initialization typically happens outside the tests, before they run. We therefore designed a way for tests to isolate the entire lifecycle of a function, including initialization. This allows us to run initialization within a test, and even repeat it multiple times allowing tests of different aspects:
require "minitest/autorun"
require "functions_framework/testing"
class MyTest < Minitest::Test
# Include testing helper methods
include FunctionsFramework::Testing
def test_startup_tasks
# Run the lifecycle, and test the startup tasks in isolation.
load_temporary "app.rb" do
globals = run_startup_tasks "storage_example"
assert_kind_of Google::Cloud::Storage, globals[:storage_client]
end
end
def test_storage_request
# Rerun the entire lifecycle, including the startup tasks, and
# test a function call.
load_temporary "app.rb" do
request = make_get_request "https://example.com/foo"
response = call_http "storage_example", request
assert_equal 200, response.status
end
end
end
The load_temporary method loads function definitions in a sandbox, isolating them and their initialization from other test runs. That and other helper methods are defined in the FunctionsFramework::Testing module, which can be included in minitest or rspec tests.
So far we’ve really provided only basic testing tools for the Ruby runtime, and I expect we’ll add significantly to the toolset as our users develop more apps and we identify more of the common testing patterns. But I strongly believe testing tools are an important part of any library, especially one that purports to be a framework or runtime, and so it was a core part of our design from the start.
The dependable runtime
Most nontrivial Ruby apps require third-party gems. For Ruby apps that use Google Cloud Functions, we require at least one gem, the functions_framework that provides the Ruby interfaces for writing functions. You may also need other gems for handling data, authenticating and integrating with other services, and so forth. Dependency management is a crucial part of any runtime framework.
We made several design decisions around dependency management. And the first and most important was to embrace Bundler.
I know that sounds a bit frivolous. Most Ruby apps these days use Bundler anyway, and there are very few alternatives, hardly any in widespread use. But we actually took it a step further and built Bundler deep into our infrastructure, requiring that apps use it in order to work with Cloud Functions. We did this because, knowing exactly how an app will manage its dependencies would allow us to implement some important optimizations.
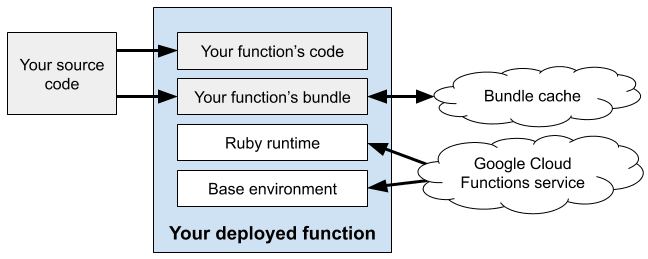
Vital to a good FaaS system is the speed of deployments and cold starts. In a serverless world, your code might be updated, deployed, and torn down many times in rapid succession, so it’s crucial to eliminate bottlenecks such as resolving and installing dependencies. Because we standardize on one system for dependency management, we are able to cache dependencies aggressively. We judged that the performance gains of implementing such caching, as well as the reduced load on the Rubygems.org infrastructure, far outweighed the reduced flexibility of not being able to use an alternative to Bundler.
Another feature, or maybe quirk, of the Ruby runtime for Google Cloud Functions, is that it will fail deployments if the gem lockfile is missing or inconsistent. We require that Gemfile.lock is present when you deploy. This was another decision made to enforce a best practice. If the lockfile gets reresolved during deployment, your builds may not be repeatable, and you may not be running against the same dependencies you tested with. We avoid this by requiring an up-to-date Gemfile.lock file, and again, we are able to enforce this because we require the use of Bundler.
Standards old and new
Finally, good designs lean on standards and prior art. We had to innovate a bit to define robust functions in Ruby, but when it comes to representing the function arguments, there were already existing libraries or emerging standards to follow.
For example, in the near term, many functions will respond to web hooks, and will need information about the incoming HTTP request. It would not be difficult to design a class that represents an HTTP request, but the Ruby community already has a standard API for this sort of thing: Rack. We adopted the Rack request class for our event parameters, and we support standard Rack responses for return values.
require "functions_framework"
FunctionsFramework.http "http_example" do |request|
# request is a Rack::Request object.
logger.info "I received #{request.request_method} from #{request.url}!"
# You can return a standard Rack response array, or use one of
# several convenience formats.
[200, {}, "ok"]
end
Not only does this provide a familiar API, but it also makes it easy to integrate with other Rack-based libraries. For example, it is easy to layer a Sinatra app atop Cloud Functions because they both speak Rack.
In the longer term, we increasingly expect functions-as-a-service to fit as a component in evented systems. Event-based architectures are rapidly growing in popularity, often surrounding event queues such as Apache Kafka. And a crucial element of an event architecture is a standard way to describe the events themselves, a standard understood by event senders, brokers, transport, and consumers.
Google Cloud Functions has thrown its support behind CNCF CloudEvents, an emerging standard for describing and delivering events. In addition to HTTP requests, Cloud Functions can also receive data in the form of a CloudEvent, and the runtime will even convert some legacy event types to CloudEvents when calling your function.
require "functions_framework"
FunctionsFramework.cloud_event "my_handler" do |event|
# event is a CloudEvent object defined by the cloud_events gem
logger.info "I received a CloudEvent of type #{event.type}!"
end
To support CloudEvents in Ruby, the Google Ruby team worked closely with the CNCF Serverless Working Group, and even volunteered to take over development of the Ruby SDK for CloudEvents. This turned out to be a lot of work, but we considered it crucial to be able to use the official, standard Ruby interfaces, even if we had to implement it ourselves.
The serverless future
“Serverless” and “functions-as-a-service” hosting has garnered a lot of interest over the past few years. I think the jury is still out on how useful it will be for most workloads, but the possibilities are intriguing. “Zero”-devops, automatic maintenance and scaling, no servers to maintain, and pay only for the compute resources you actually use. I recently moved this very blog from a personal Kubernetes cluster to Google’s managed Cloud Run service, and slashed my monthly bill from dozens of dollars down to pennies.
That said, serverless is a fundamentally different way of thinking about compute resources, and as an industry we are still very early in our understanding of the implications. As my team designed the Ruby runtime for Google Cloud Functions, we were mindful about the ways the serverless paradigm interacts with our normal Ruby practices. In some cases, as with testing, it encourages us to double down on the good parts of Ruby culture. In others, as with how to express and notate a function in a language that strictly speaking doesn’t have them, it challenges our ideas of how to present code and communicate its intent.
But in all cases, the experience of designing the runtime reminded me that we’re in a industry of constant change. Serverless is just the latest in a string of disruptions that have included the public cloud in general, and even Rails, and Ruby itself. It’s not yet clear how much serverless will stick, but it is here today, and it’s up to us to respond with curiosity, creativity, and a willingness not to take what we know for granted.


















