
Gemma just opened ;)
Gemma is a family of open, lightweight, and easy-to-use models developed by Google Deepmind. The Gemma models are built from the same research and technology used to create Gemini.
This means that we (ML developers & practitioners) now have additional versatile large language models (LLMs) in our toolbox!
If you’d rather read code, you can jump straight to this Python notebook:
→ Finetune Gemma using KerasNLP and deploy to Vertex AI
Availability
Gemma is available today in Google Cloud and the machine learning (ML) ecosystem. You’ll probably find an ML platform you’re already familiar with:
- Gemma joins 130+ models in Vertex AI Model Garden
- Gemma joins the Kaggle Models
- Gemma joins the Hugging Face Models
- Gemma joins Google AI for Developers
Here are the Gemma Terms of Use.
Gemma models
The Gemma family launches in two sizes, Gemma 2B and 7B , targeting two typical platform types:
| Model | Parameters | Platforms |
|---|---|---|
| Gemma 2B | 2.5 billion | Mobile devices and laptops |
| Gemma 7B | 8.5 billion | Desktop computers and small servers |
These models are text-to-text English LLMs:
- Input: a text string, such as a question, a prompt, or a document.
- Output: generated English text, such as an answer or a summary.
They were trained on a diverse and massive dataset of 8 trillion tokens, including web documents, source code, and mathematical text.
Each size is available in untuned and tuned versions:
- Pretrained (untuned): Models were trained on core training data, not using any specific tasks or instructions.
- Instruction-tuned: Models were additionally trained on human language interactions.
That gives us four variants. As an example, here are the corresponding model IDs when using Keras:
gemma_2b_engemma_instruct_2b_engemma_7b_engemma_instruct_7b_en
Use cases
Google now offers two families of LLMs: Gemini and Gemma. Gemma is a complement to Gemini, is based on technologies developed for Gemini, and addresses different use cases.
Examples of Gemini benefits:
- Enterprise applications
- Multilingual tasks
- Optimal qualitative results and complex tasks
- State-of-the-art multimodality (text, image, video)
- Groundbreaking features (e.g. Gemini 1.5 Pro 1M token context window)
Examples of Gemma benefits:
- Learning, research, or prototyping based on lightweight models
- Focused tasks such as text generation, summarization, and Q&A
- Framework or cross-device interoperability
- Offline or real-time text-only processings
The Gemma model variants are useful in the following use cases:
- Pretrained (untuned): Consider these models as a lightweight foundation and perform a custom finetuning to optimize them to your own needs.
- Instruction-tuned: You can use these models for conversational applications, such as a chatbot, or to customize them even further.
Interoperability
As Gemma models are open, they are virtually interoperable with all ML platforms and frameworks.
For the launch, Gemma is supported by the following ML ecosystem players:
- Google Cloud
- Kaggle
- Keras, which means that Gemma runs on JAX, PyTorch, and TensorFlow
- Hugging Face
- Nvidia
And, of course, Gemma can run on GPUs and TPUs.
Requirements
Gemma models are lightweight but, in the LLM world, this still means gigabytes.
In my tests, when running inferences in half precision (bfloat16), here are the minimum storage and GPU memory that were required:
| Model | Total parameters | Assets size | Min. GPU RAM to run |
|---|---|---|---|
| Gemma 2B | 2,506,172,416 | 4.67 GB | 8.3 GB |
| Gemma 7B | 8,537,680,896 | 15.90 GB | 20.7 GB |
To experiment with Gemma and Vertex AI, I used Colab Enterprise with a g2-standard-8 runtime, which comes with an NVIDIA L4 GPU and 24 GB of GPU RAM. This is a cost-effective configuration to save time and avoid running out-of-memory when prototyping in a notebook.
Finetuning Gemma
Depending on your preferred frameworks, you’ll find different ways to customize Gemma. Keras is one of them and provides everything you need.
KerasNLP lets you load a Gemma model in a single line:
import keras
import keras_nlp
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_instruct_2b_en")
Then, you can directly generate text:
inputs = [
"What's the most famous painting by Monet?",
"Who engineered the Statue of Liberty?",
'Who were "The Lumières"?',
]
for input in inputs:
response = gemma_lm.generate(input, max_length=25)
output = response[len(input) :]
print(f"{input!r}\n{output!r}\n")
With the instruction-tuned version, Gemma gives you expected answers, as would a good LLM-based chatbot:
# With "gemma_instruct_2b_en"
"What's the most famous painting by Monet?"
'\n\nThe most famous painting by Monet is "Water Lilies," which'
'Who engineered the Statue of Liberty?'
'\n\nThe Statue of Liberty was built by French sculptor Frédéric Auguste Bartholdi between 1'
'Who were "The Lumières"?'
'\n\nThe Lumières were a group of French scientists and engineers who played a significant role'
Now, try the untuned version:
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
You’ll get different results, which is expected as this version was not trained on any specific task and is designed to be finetuned to your own needs:
# With "gemma_2b_en"
"What's the most famous painting by Monet?"
"\n\nWhat's the most famous painting by Van Gogh?\n\nWhat"
'Who engineered the Statue of Liberty?'
'\n\nA. George Washington\nB. Napoleon Bonaparte\nC. Robert Fulton\nD'
'Who were "The Lumières"?'
' What did they invent?\n\nIn the following sentence, underline the correct modifier from the'
If you’d like, for example, to build a Q&A application, prompt engineering may fix some of these issues but, to be grounded on facts and return consistent results, untuned models need to be finetuned with training data.
The Gemma models have billions of trainable parameters. The next step consists of using the Low Rank Adaptation (LoRA) to greatly reduce the number of trainable parameters:
# Number of trainable parameters before enabling LoRA: 2.5B
# Enable LoRA for the model and set the LoRA rank to 4
gemma_lm.backbone.enable_lora(rank=4)
# Number of trainable parameters after enabling LoRA: 1.4M (1,800x less)
A training can now be performed with reasonable time and GPU memory requirements.
For prototyping on a small training dataset, you can launch a local finetuning:
training_data: list[str] = [...]
# Reduce the input sequence length to limit memory usage
gemma_lm.preprocessor.sequence_length = 128
# Use AdamW (a common optimizer for transformer models)
optimizer = keras.optimizers.AdamW(
learning_rate=5e-5,
weight_decay=0.01,
)
# Exclude layernorm and bias terms from decay
optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])
gemma_lm.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
gemma_lm.fit(training_data, epochs=1, batch_size=1)
After a couple of minutes of training (on 1,000 examples) and using a structured prompt, the finetuned model can now answer questions based on your training data:
# With "gemma_2b_en" before finetuning
'Who were "The Lumières"?'
' What did they invent?\n\nIn the following sentence, underline the correct modifier from the'
# With "gemma_2b_en" after finetuning
"""
Instruction:
Who were "The Lumières"?
Response:
"""
"The Lumières were the inventors of the first motion picture camera. They were"
The prototyping stage is over. Before you proceed to finetuning models in production with large datasets, check out new specific tools to build a responsible Generative AI application.
Responsible AI
With great power comes great responsibility, right?
The Responsible Generative AI Toolkit will help you build safer AI applications with Gemma. You’ll find expert guidance on safety strategies for the different aspects of your solution.
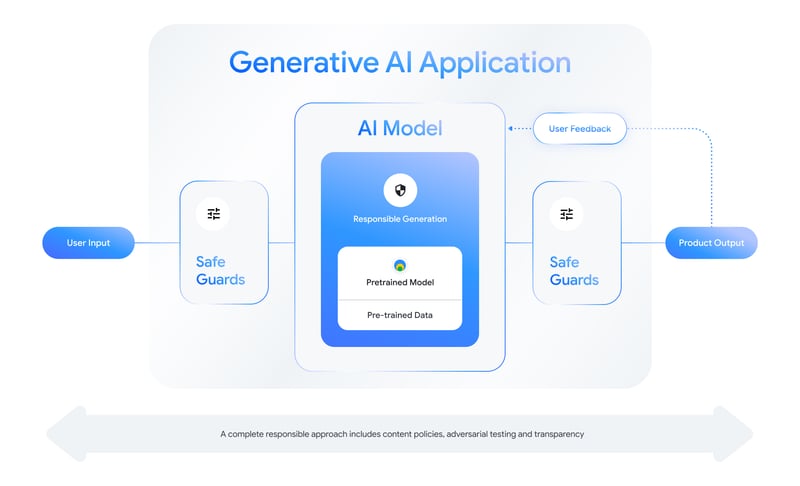
Also, do not miss the Learning Interpretability Tool (LIT) for visualizing and understanding the behavior of your Gemma models. Here’s a video tour showing the tool in action:
Deploying Gemma
We’re in MLOps territory here and you’ll find different LLM-optimized serving frameworks running on GPUs or TPUs.
Here are popular serving frameworks:
- vLLM (GPU)
- TGI: Text Generation Interface (GPU)
- Saxml (TPU or GPU)
- TensorRT-LLM (NVIDIA Triton GPU)
These frameworks come with prebuilt container images that you can easily deploy to Vertex AI.
Here is a simple notebook to get you started:
For production finetuning, you can use Vertex AI custom training jobs. Here are detailed notebooks:
- Gemma Finetuning (served by vLLM or HexLLM)
- Gemma Finetuning (served by TGI)
Those notebooks focus on deployment and serving:
- Gemma Deployment (served by vLLM or HexLLM)
- Gemma Deployment to GKE using TGI on GPU
For more details and updates, check out the documentation:
All the best to Gemini and Gemma!
After years of consolidation in machine learning hardware and software, it’s exciting to see the pace at which the overall ML landscape now evolves and in particular with LLMs. LLMs are technologies still in their infancy, so we can expect to see more breakthroughs in the near future.
I very much look forward to seeing what the ML community is going to build with Gemma!
All the best to the Gemini and Gemma families!
Follow me on Twitter or LinkedIn for more cloud explorations…


















