👋 Hello!
In this article, following up on the previous one ("Video summary as a service"), you'll see the following:
- how to track objects present in a video,
- with an automated processing pipeline,
- in less than 300 lines of Python code.
Here is an example of an auto-generated object summary for the video :

🛠️ Tools
A few tools will do:
- Storage space for videos and results
- A serverless solution to run the code
- A machine learning model to analyze videos
- A library to extract frames from videos
- A library to render the objects
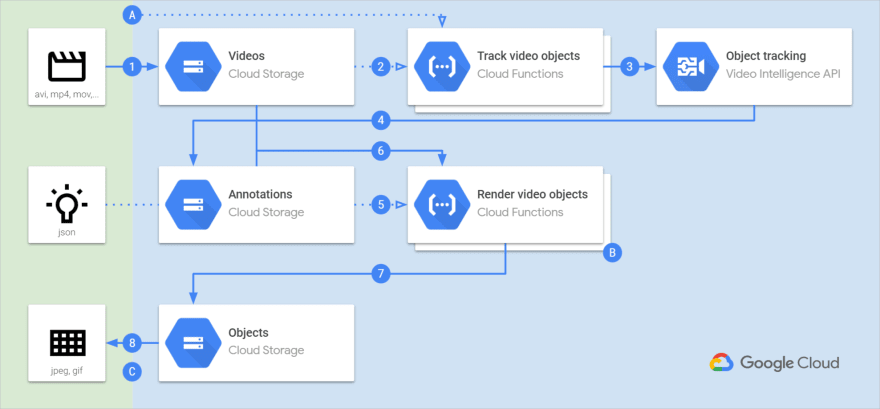
🧱 Architecture
Here is a possible architecture using 3 Google Cloud services (Cloud Storage, Cloud Functions, and the Video Intelligence API):

The processing pipeline follows these steps:
- You upload a video
- The upload event automatically triggers the tracking function
- The function sends a request to the Video Intelligence API
- The Video Intelligence API analyzes the video and uploads the results (annotations)
- The upload event triggers the rendering function
- The function downloads both annotation and video files
- The function renders and uploads the objects
- You know which objects are present in your video!
🐍 Python libraries
Video Intelligence API
- To analyze videos
- https://pypi.org/project/google-cloud-videointelligence
Cloud Storage
- To manage downloads and uploads
- https://pypi.org/project/google-cloud-storage
OpenCV
- To extract video frames
-
OpenCVoffers a headless version (without GUI features, ideal for a service) - https://pypi.org/project/opencv-python-headless
Pillow
- To render and annotate object images
-
Pillowis a very popular imaging library, both extensive and easy to use - https://pypi.org/project/Pillow
🧠 Video analysis
Video Intelligence API
The Video Intelligence API is a pre-trained machine learning model that can analyze videos. One of its multiple features is detecting and tracking objects. For the 1st Cloud Function, here is a possible core function calling annotate_video() with the OBJECT_TRACKING feature:
from google.cloud import storage, videointelligence
def launch_object_tracking(video_uri: str, annot_bucket: str):
""" Detect and track video objects (asynchronously)
Results will be stored in <annot_uri> with this naming convention:
- video_uri: gs://video_bucket/path/to/video.ext
- annot_uri: gs://annot_bucket/video_bucket/path/to/video.ext.json
"""
print(f"Launching object tracking for <{video_uri}>...")
features = [videointelligence.Feature.OBJECT_TRACKING]
video_blob = storage.Blob.from_string(video_uri)
video_bucket = video_blob.bucket.name
path_to_video = video_blob.name
annot_uri = f"gs://{annot_bucket}/{video_bucket}/{path_to_video}.json"
request = dict(features=features, input_uri=video_uri, output_uri=annot_uri)
video_client = videointelligence.VideoIntelligenceServiceClient()
video_client.annotate_video(request)
Cloud Function entry point
import os
ANNOTATION_BUCKET = os.getenv("ANNOTATION_BUCKET", "")
assert ANNOTATION_BUCKET, "Undefined ANNOTATION_BUCKET environment variable"
def gcf_track_objects(data, context):
"""Cloud Function triggered by a new Cloud Storage object"""
video_bucket = data["bucket"]
path_to_video = data["name"]
video_uri = f"gs://{video_bucket}/{path_to_video}"
launch_object_tracking(video_uri, ANNOTATION_BUCKET)
Notes:
- This function will be called when a video is uploaded to the bucket defined as a trigger.
- Using an environment variable makes the code more portable and lets you deploy the exact same code with different trigger and output buckets.
🎨 Object rendering
Code structure
It's interesting to split the code into 2 main classes:
-
StorageHelperfor managing local files and cloud storage objects -
VideoProcessorfor all graphical processings
Here is a possible core function for the 2nd Cloud Function:
class VideoProcessor:
@staticmethod
def render_objects(annot_uri: str, output_bucket: str):
"""Render objects from video annotations"""
with StorageHelper(annot_uri, output_bucket) as storage:
with VideoProcessor(storage) as video_proc:
print(f"Objects to render: {video_proc.object_count}")
video_proc.render_object_summary()
Cloud Function entry point
def gcf_render_objects(data, context):
"""Cloud Function triggered by a new Cloud Storage object"""
annotation_bucket = data["bucket"]
path_to_annotation = data["name"]
annot_uri = f"gs://{annotation_bucket}/{path_to_annotation}"
VideoProcessor.render_objects(annot_uri, OBJECT_BUCKET)
Note: This function will be called when an annotation file is uploaded to the bucket defined as a trigger.
Frame rendering
OpenCV and Pillow easily let you extract video frames and compose over them:
class VideoProcessor:
def get_frame_with_overlay(
self, obj: vi.ObjectTrackingAnnotation, frame: vi.ObjectTrackingFrame
) -> PilImage:
def get_video_frame() -> PilImage:
pos_ms = frame.time_offset.total_seconds() * 1000
self.video.set(cv.CAP_PROP_POS_MSEC, pos_ms)
_, cv_frame = self.video.read()
image = Image.fromarray(cv.cvtColor(cv_frame, cv.COLOR_BGR2RGB))
image.thumbnail(self.cell_size) # Makes it smaller if needed
return image
def add_caption(image: PilImage) -> PilImage:
...
def add_bounding_box(image: PilImage) -> PilImage:
...
draw.rectangle(r, outline=BBOX_COLOR, width=BBOX_WIDTH_PX)
return image
return add_bounding_box(add_caption(get_video_frame()))
Note: It would probably be possible to only use
OpenCVbut I found it more productive developing withPillow(code is more readable and intuitive).
🔎 Results
Here are the main objects found in the video :

Notes:
- The machine learning model has correctly identified different wildlife species: those are "true positives". It has also incorrectly identified our planet as "packaged goods": this is a "false positive". Machine learning models keep learning by being trained with new samples so, with time, their precision keeps increasing (resulting in less false positives).
- The current code filters out objects detected with a confidence below 70% or with less than 10 frames. Lower the thresholds to get more results.
🍒 Cherry on Py 🐍
Now, the icing on the cake (or the "cherry on the pie" as we say in French), you can enrich the architecture to add new possibilities:
- Trigger the processing for videos from any bucket (including external public buckets)
- Generate individual object animations (in parallel to object summaries)
Architecture (v2)
- A - Video object tracking can also be triggered manually with an HTTP GET request
- B - The same rendering code is deployed in 2 sibling functions, differentiated with an environment variable
- C - Object summaries and animations are generated in parallel
Cloud Function HTTP entry point
def gcf_track_objects_http(request):
"""Cloud Function triggered by an HTTP GET request"""
if request.method != "GET":
return ("Please use a GET request", 403)
if not request.args or "video_uri" not in request.args:
return ('Please specify a "video_uri" parameter', 400)
video_uri = request.args["video_uri"]
launch_object_tracking(video_uri, ANNOTATION_BUCKET)
return f"Launched object tracking for <{video_uri}>"
Note: This is the same code as
gcf_track_objects()with the video URI parameter specified by the caller through a GET request.
🎉 Results
Here are some auto-generated trackings for the video :
- The left elephant (a big object ;) is detected:

- The right elephant is perfectly isolated too:

- The veterinarian is correctly identified:

- The animal he's feeding too:

Moving objects or static objects in moving shots are tracked too, as in :
- A building in a moving shot:

- Neighbor buildings are tracked too:

- Persons in a moving shot:

- A surfer crossing the shot:

Here are some others for the video :
- A butterfly (easy?):

- An insect, in larval stage, climbing a moving twig:

- An ape in a tree far away (hard?):

- A monkey jumping from the top of a tree (harder?):

- Now, a trap! If we can be fooled, current machine learning state of the art can too:

🚀 Source code and deployment
- The Python source code is less than 300 lines.
- You can deploy this architecture in less than 8 minutes.
- See "Deploying from scratch".
🖖 See you
Do you want more, do you have questions? I'd love to read your feedback. You can also follow me on Twitter.
⏳ Updates
- 2021-10-08: Updated with latest library versions + Python 3.7 → 3.9


















