Getting the code right is just the start of building software. Once you’ve got something running on your dev machine, you also need to consider:
- How you’ll deploy the software
- What your release schedule for new features and fixes will look like
- How to handle security
- How you’ll scale when the time comes.
Architecture is one of the biggest choices that we make when building software. And this past decade has seen some pretty big changes in the architecture patterns that we consider “normal”.
Specifically, we’ve gone from building ever larger web apps as a single codebase, operating as monolithic applications, to a world where decoupled components come together to form a coherent whole. That’s not to say that component architectures are new or even that they’re the best choice for every project. But the story of how we got here is an interesting one.
Kafka, in particular, has been something of a hero in that story. So, how did we get where we are today and what role did Kafka have to play?
The monolith
Even the name “monolith” sounds imposing and impenetrable. It literally means “single rock”.

Think of a typical Rails app. The components that make up the application are interconnected and interdependent. With this pattern, the software is self-contained, built, and deployed as a single solution.
This approach comes with some drawbacks. One of them is that monoliths suffer from the butterfly effect. Seemingly small changes in one part of the codebase can have unintended consequences elsewhere. Adding features and fixing bugs can take longer as a result. Even if the development phase is straightforward, testing and deployment carry with them the complexities of testing and deploying the entire application rather than just the part you updated.
Monolithic architectures work well in a lot of scenarios but three changes have meant that other patterns have come to the fore:
- the scalability and uptime demands of an always-on user culture
- agile development practices
- the increasing complexity of software consumed via the web and mobile devices.
Enter modular architectures.
Moving to a modular architecture
Modular architectures are not new. In the 80s and 90s, CORBA (Common Object Request Broker Architecture) and Remote Procedure Calls (RPC) introduced a modular pattern that enabled developers to invoke methods without having to consider where they were running. And, of course, RPC is still very much a part of current web development.
What separates modular architecture from monoliths is the idea that an application should be broken into complementary yet distinct “chunks” of functionality. So, for example, the authentication part of an application would exist as a discrete service with its own API. In theory, the auth system’s code could be entirely swapped out without affecting the running of the application, so long as the API remained the same.

Modular architectures reduce the risk that a change made in one component will create unanticipated changes in other components. That loose coupling has a second benefit. Simpler, self-contained services suit agile and team development practices much more easily than working with a large monolith. Modular design patterns such as service-oriented architecture and microservices architecture have enjoyed increased uptake partly because of how well they suit agile development.
While services are loosely-coupled and operate independently, they still need to communicate with each other. This is where RPC and REST come in. Let’s look at an ecommerce site as an example. We’ll imagine it has several autonomous services that communicate together to form a whole system.
- Call the card processing service to charge the card.
- Call the orders service to mark the order as paid.
- The order service calls the email service to send a confirmation email before returning a response to the payment service.
- Then call the shipping service to prepare and ship the order.
Developing and running those services independently means that we now need to ensure that they work well together.
In our ecommerce example, we want to make sure that when the buyer clicks Pay they get a confirmation as soon as their payment is processed and their order confirmed.
In this case, the application has to synchronously wait for all the service calls to complete before responding to the buyer. So, the system still has some level of interdependency whereby a failure with the orders or shipping service might cause the payment service to respond to the user that the payment failed, even if it was able to charge the credit card.
It’s less useful to have a loosely coupled system that has to wait for supposedly independent components to complete their tasks synchronously. The solution came in the form of messaging services. They decouple service-to-service communication to such an extent that the service sending the message has no visibility of which services will see the data or when.
Asynchronous communication with message queues
Most messaging comes in the form of the message queue.

Message queuing is a form of asynchronous service-to-service communication used in service-oriented and microservices architectures. With this pattern, a system produces messages, which are stored in a message queue until they are processed by a consumer. Each message is processed only once, by a single consumer.
Applying this to our ecommerce example, we would use several message queues. One to handle payments, one to handle picking, and another to handle shipping. In reality, there might be several other queues, such as one to send email or SMS status updates to customers. Our simplified version would look something like this:
- The order processing service sends a message to the payments queue requesting a charge to the customer’s card.
- Once the card payment service has successfully charged the card, it will send a success message to the picking/packing queue.
- The picking and packing service picks up the message and, once a human picker marks the package as ready, the service sends a message to the shipping queue.
- The shipping service receives the message and books a shipping company to dispatch the physical item to the customer.
With this approach, the services still run synchronously but the services themselves are freed from having to know all that much about what happens next. That means they can evolve without worrying that they’ll break other parts of the system, so long as the message format stays the same.
This decoupled solution works well but it’s not suited to every scenario. Message queues support high rates of consumption by adding multiple consumers, but only one consumer will receive each message on the topic/channel, and once it’s read, it’s removed from the queue. Thus, the message is processed exactly once but not necessarily processed in order.
In the case of network or consumer failures, the message queue will try resending the message at a later time (not necessarily to the same consumer) and as a result, that message may be processed out of order.
Enter The Publish-Subscribe model
In our ecommerce example, once payment and stock availability are confirmed then subsequent processes can happen in parallel. Sending a confirmation email could happen at the same time as allocating a stock picker and arranging the shipping service. If they can run in parallel then the process overall should complete faster. This is a job for the publish-subscribe messaging pattern, or pub-sub.
Pub-sub is ideally suited to scenarios where multiple consumers receive each message and/or the order that consumers receive messages is unimportant because each message published is received immediately by all subscribers.
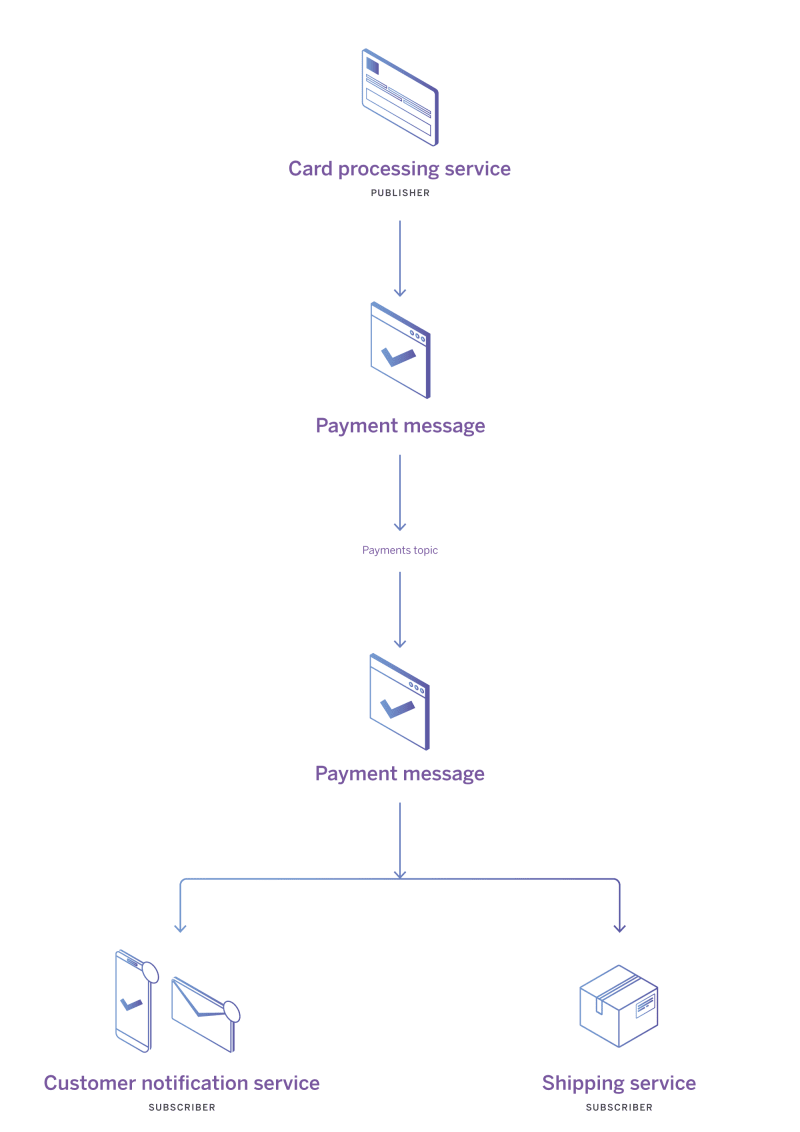
In the pub-sub world, there are publishers, topics, messages, and subscribers. Subscribers are consumers that subscribe to receive every message on a given topic or topics. Publishers, as you might expect, send messages to a topic.
When a publisher sends a message to a topic there’s usually very little latency between publication and all subscribers receiving that message. That makes pub-sub ideal for real-time data processing.
In our ecommerce example, the card processing service is a publisher and the services that depend on it would subscribe to a payments topic. Let’s say a payment is successful. The payment service publishes a message confirming payment, along with the order details. The email, picking, shipping, and other services would receive that message as subscribers, enabling them to get to work immediately and simultaneously.
Now our application consists of decoupled event-driven services, making it more performant, more reliable, more scalable, and easier to change. What more could we want?
Delivery isn’t always a zero sum game
A reliable way to quickly send messages between decoupled components has helped teams to build robust systems at scale. But traditional message queue systems have their issues.
One such issue is the conflict between “deliver at least once” and “deliver exactly once”.
In our ecommerce example, we need to make sure that each of the processes happens just once. Payment should be taken once, the item should be picked and packed once, shipping should be handled once. Some pub-sub systems guarantee that each message will be delivered at least once to each subscriber but not exactly once. In some situations, messages might also arrive out of order.
“Deliver at least once” message queues complicate the logic of each component in the system. To prevent things happening more than once, our ecommerce system would need to maintain state for each process so it could check whether it had already performed a particular action for an order. That way, a second copy of a “payment processed successfully for order #1234” message could safely be ignored but only because that process would first check in its database to see whether it had already handled the next steps. That’s just the type of problem that Apache Kafka was designed to solve.
Enter Apache Kafka
At LinkedIn, they needed a horizontally scalable, fault tolerant messaging system. Existing pub-sub message queues could not scale out to a cluster of cooperating nodes. They also suffered from the “deliver at least once” problem.
The team at LinkedIn looked to distributed databases and found the idea of a distributed commit log. A commit log is simply that: a log that records all of the messages committed to the system.
With an immutable commit log at its heart, the LinkedIn team could build Kafka as a “deliver exactly once” system and a “deliver in the right order” system. As the data is delivered in the right order and the right number of times, Kafka works as a data streaming platform rather than only a message queue.
Kafka is a key component of the technology stack at LinkedIn, and it has helped them achieve scalability and reliability, processing up to 7 trillion messages a day. Uber’s passenger-driver matching system runs on Kafka, as does British Gas’s IoT smart-thermostat network.
So, what has Kafka delivered that message queues did not? Unlike message queues, where messages are essentially ephemeral, Kafka’s commit log means that applications can rely on it as a massively scalable source of truth. Kafka can be stateful, leaving developers to create simpler stateless components. Perhaps more importantly, Kafka can connect to external services to transform data in transit, thereby taking even more burden away from custom code.
So, looking back at our ecommerce example, Kafka could pass payment details to an external fraud detection service before handing it to the payment processing service.
Kafka changed the world by making it so that just about any team could build componentized applications around a massively scalable and reliable heart pumping data around the system. For developers that means more time focusing on building the unique value their end users care about.
Running distributed systems isn’t always easy
It’s hard to argue with something that hands productive time back to developers but, let’s be honest, Kafka is a complex beast to run in production.
As so often happens, Kafka makes us consider this trade-off: is it better to stick with simpler tooling that has less of an ops burden or should some members of a team spend their productive time looking after the ops of a system that makes their teammates more productive?
But that’s not the only way to think about this. Ever since the first assembler language made it just that bit easier to write machine code, we’ve been standing on the work of others so that we can get our own unique value into production faster. Seen that way, then why take the productivity hit of running your own Kafka instances? Instead, let Kafka ops experts, such as Heroku, run it on your behalf. That way, you and your teammates can focus on delivering your product rather than running infrastructure.
And that’s the key to understanding how Kafka has changed the world. It’s not about the nuts of bolts of highly scalable, fault tolerant message streaming. It’s about the value that it has delivered. Whether you run your own cluster or choose a cloud-instance, Kafka has made it easier than ever to build huge, robust systems of independent services.
Monolith photo by Jose Magana
Coloured bricks photo by Phil Seldon ABIPP
Neon message icon photo by Jason Leung


















