
There are events in our life that seem to be just routine, but then unexpectedly they have a profound impact on our journey. For me, one event was attending the 2008 Gartner conference in Orlando, Florida.
That event not only introduced me to the Salesforce ecosystem for the very first time but also to concepts like:
- Service-Oriented Architecture (via an impressive session by Roy Schulte)
- Web 2.0 and Mashups
- RESTful API Design
While I had modest expectations for the event, those few days in central Florida became a key aspect of focus for the next 13 years of my career, far exceeding any expectations I could have ever imagined.
Along the way, I learned many lessons from projects and initiatives focused on these very concepts. In this article, I will dive into several lessons learned from projects that placed RESTful APIs at the core of an application’s design.
The RESTful API Pitfalls
The RESTful API software style provides an easy manner for client applications to gain access to the resources (data) they need to meet business needs. In fact, it did not take long for Javascript-based frameworks like Angular, React, and Vue to rely on RESTful APIs and lead the market for web-based applications.
This pattern of RESTful service APIs and frontend Javascript frameworks sparked a desire for many organizations to fund projects migrating away from monolithic or outdated applications. The RESTful API pattern also provided a much-needed boost in the technology economy which was still recovering from the impact of the Great Recession.
Fast-forward several agile iterations into this new development paradigm, and two pitfalls have been repeatedly encountered more than they have been avoided:
- An outdated application design was ultimately replaced with a very large RESTful API and an equally large Javascript framework. This created challenges with coordinating future features and enhancements; basically, one monolith was replaced by another.
- A legacy application design employed multiple RESTful APIs and componentized clients utilizing Javascript frameworks, but a single database was utilized. The result of this design led to data ownership conflicts, a higher-than-expected number of database connections, and higher costs to support/maintain a large database.
Below is an example of how pitfall #2 played out, with several services competing for resources from a single database:

Unfortunately, I have also seen these same scenarios with greenfield development opportunities, where there is a preference to use a single database for an entire collection of microservices.
Microservices Should Begin With the Database
In most programming languages, it is possible to create a fully functional application using a single file. In Java, everything could be in the same class file and stemmed from simply calling the main() method:
public class SingleClassApplication {
public static void main(String[] args) {
// Start doing something really cool here
}
}
However, this approach is not very supportable, nor does it facilitate easy contribution from multiple developers.
There is also the concept of “ownership” (or system of record) when it comes to aspects of an application. In cases where more than one service or function claims to be the owner of something (like a customer), challenges arise when business rules differ. The same scenario can occur when multiple RESTful APIs claim ownership of a given object.
These same concepts translate to the database layer when employing a RESTful API design. Consider the following guideline:
A single RESTful API should be considered the system of record for a given aspect of the application. As such, the corresponding data tier should leverage a data store focused solely on that aspect of the application.
The illustration below provides a microservices design that adheres to this guideline:

A successful microservice design begins with the database. Once in place, scaling to meet customer demand for the given service does not have an impact on any other service.
Counterpoint: What About Database Constraints?
My recommended approach is to isolate a given microservice with a dedicated database. This allows the count and size of the related components to match user demand while avoiding additional costs for elements that do not have the same levels of demand.
Database administrators are quick to defend the single-database design by noting the benefits that constraints and relationships can provide when all of the elements of the application reside in a single database. As an example, a single database design can prevent a request to remove a customer if there are orders associated with the customer queued for deletion.
While that is definitely a benefit to having a single database, consider the following points before opting to utilize a single database for all microservices:
- Compare the long-term value gained by using a single database with the associated costs for scaling a single, large database. What is the expected cost to scale and support a single database design in the future?
- What is the risk and value of having these constraints enforced at the API layer instead? Keep in mind that a single microservice would be considered the owner of a given database, so the business logic would not allow things like deleting a customer with active orders.
- Consider the benefits of using an event-driven (or message-based) design to handle the situations where how one microservice handles a request depends on the response from another microservice. While this is similar to a single application/single database design, the ability to scale and allocate dedicated processing power when needed can be isolated and controlled.
Certainly, constraints and relationships should be implemented and enforced, even when the database supports only a dedicated service instance.
Common Elements Should Be Abstracted
Adopting a true microservices design can lead to side effects if not planned appropriately. The biggest challenge I continue to see is the duplication of common components and the service-tier layer.
The list below provides examples of elements that are often duplicated inside each microservice:
- authentication
- caching
- logging
- monitoring
- security
In fact, consider this illustration, which I introduced in my “How I Stopped Coding Repetitive Service Components with Kong” article earlier this year.
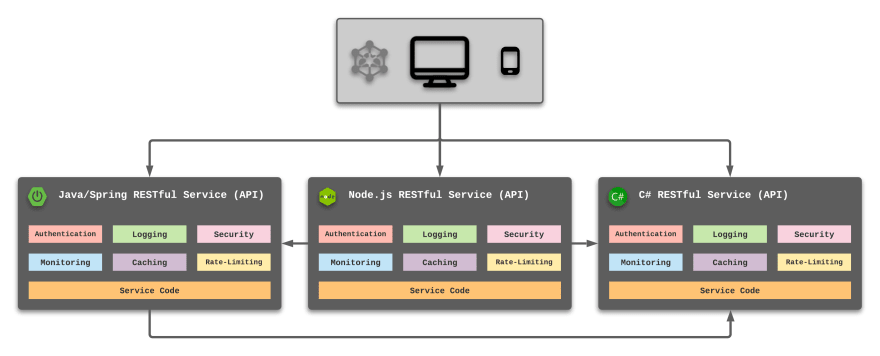
Like all aspects of the development lifecycle, we should always focus on keeping things as DRY (don’t repeat yourself) as possible. This includes elements that can be abstracted and processed at a common level or a different level of the application stack.
One approach I often recommend is a distributed microservices abstraction layer approach provided by Kong.
Placing Kong at the Center of the Ideal Design
Kong Gateway allows the complexity of service-tier APIs to be reduced to a collection of endpoints (or URIs) focused on meeting a collection of business needs and functionality. Often-duplicated components (like authentication, logging, and security) are handled by the gateway and can be removed from the service-tier design.
With each RESTful microservice maintaining a dedicated database instance and the duplicate components abstracted, a collection of purpose-driven microservices would appear as illustrated below:
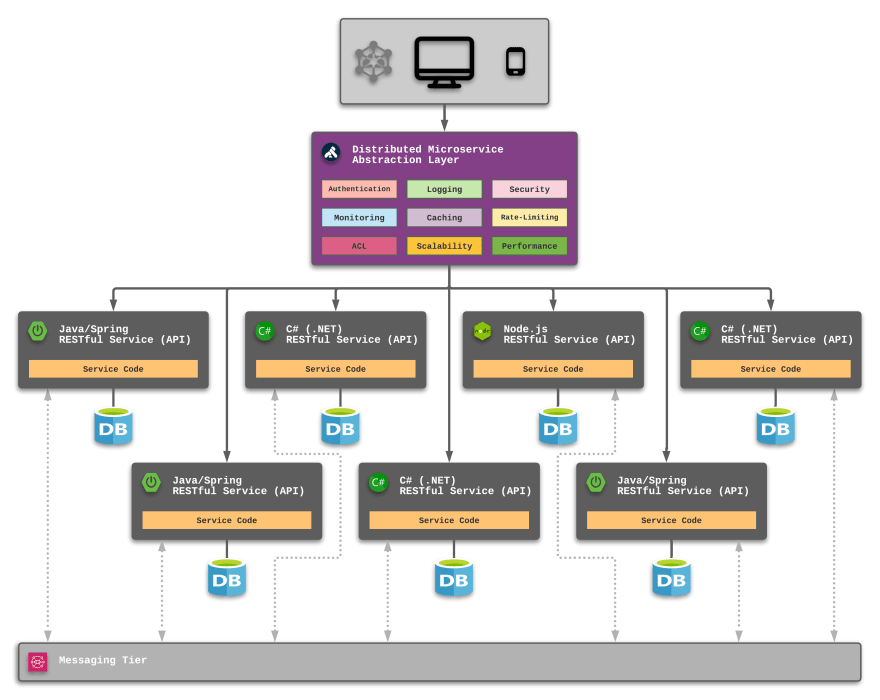
Inter-service communication is handled via a messaging tier utilizing common enterprise integration patterns, such as:
- Command Message - invoke another service to perform a background action
- Document Message - request information from another service
- Event Message - broadcast information to anyone listening on a given topic
- Request-Reply - make a request to another service and listen for a response
With this design in place, consider some real-life benefits:
- If the Node.js service experiences higher-than-expected usage, the cost to scale up to meet demands is isolated to the service and dedicated database.
- If any single service realizes that a data store change is preferred (such as SQL to NoSQL), the new design can be deployed with little (if any) impact on any of the other services—provided the RESTful API URIs are not changed.
- A change in any of the abstracted layer components (for example, using a new logging approach) can be made at the Kong Gateway layer and have no impact on the underlying services.
Conclusion
Starting in 2021, I have been trying to live by the following mission statement, which I feel can apply to any IT professional:
“Focus your time on delivering features/functionality which extends the value of your intellectual property. Leverage frameworks, products, and services for everything else.”
- J. Vester
While the primary objective of this article is to move toward a true microservice design that includes a dedicated database, Kong provides core aspects for a true microservice design that are scalable and easy to adopt. In fact, Kong Gateway allows developers to keep things DRY, introducing common components to reside in the distributed microservices abstraction layer.
Remember, “microservices” includes the word “micro,” which is often defined as “extremely small.” It is important to keep this basic premise in mind during any microservice implementation.
Feature developers utilize packages and classes to group their program code for supportability and maintainability. Within those classes, methods and functions are defined—often employing a rule that each block of code is small and easy to digest. To me, an ideal function or method is one that I can review without ever having to touch my mouse.
Microservices should be an extension of the same rules programmers have been following for decades: keep things small, purpose-driven, and efficient … keep things “micro.”
To reach that goal, the design must include the database.
Have a really great day!


















