
Software engineers occupy an exciting place in this world. Regardless of the tech stack or industry, we are tasked with solving problems that directly contribute to the goals and objectives of our employers. As a bonus, we get to use technology to mitigate any challenges that come into our crosshairs.
For this example, I wanted to focus on how pgvector – an open-source vector similarity search for Postgres – can be used to identify data similarities that exist in enterprise data.
A Simple Use Case
As a simple example, let’s assume the marketing department requires assistance for a campaign they plan to launch. The goal is to reach out to all the Salesforce accounts that are in industries that closely align with the software industry.
In the end, they would like to focus on accounts in the top three most similar industries, with the ability to use this tool in the future to find similarities for other industries. If possible, they would like the option to provide the desired number of matching industries, rather than always returning the top three.
High-Level Design
This use case centers around performing a similarity search. While it is possible to complete this exercise manually, the Wikipedia2Vec tool comes to mind because of the pre-trained embeddings that have already been created for multiple languages. Word embeddings—also known as vectors—are numeric representations of words that contain both their syntactic and semantic information. By representing words as vectors, we can mathematically determine which words are semantically “closer” to others.
In our example, we could also have written a simple Python program to create word vectors for each industry configured in Salesforce.
The pgvector extension requires a Postgres database. However, the enterprise data for our example currently resides in Salesforce. Fortunately, Heroku Connect provides an easy way to sync the Salesforce accounts with Heroku Postgres, storing it in a table called salesforce.account. Then, we’ll have another table called salesforce.industries that contains each industry in Salesforce (as a VARCHAR key), along with its associated word vector.
With the Salesforce data and word vectors in Postgres, we’ll create a RESTful API using Java and Spring Boot. This service will perform the necessary query, returning the results in JSON format.
We can illustrate the high-level view of the solution like this:
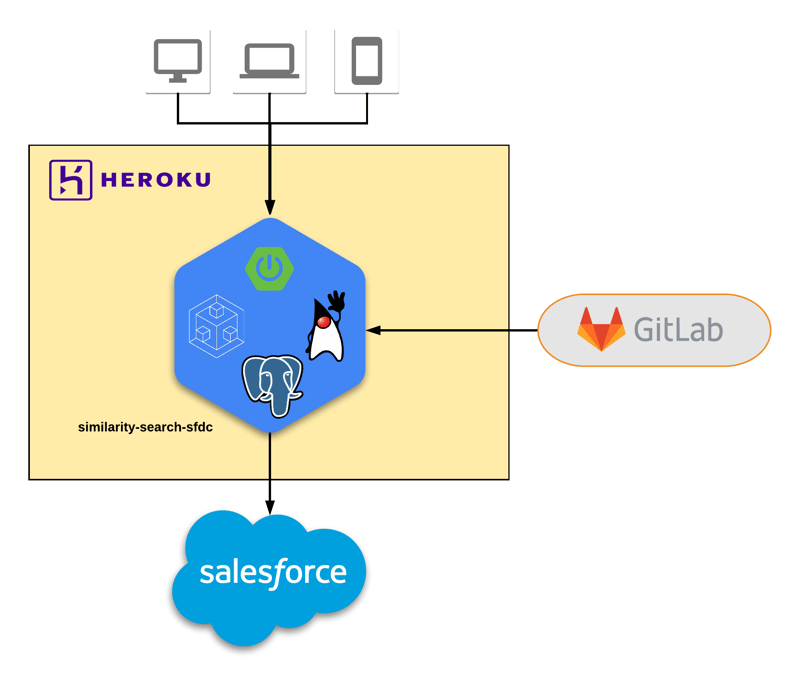
The source code will reside in GitLab. Issuing a git push heroku command will trigger a deployment in Heroku, introducing a RESTful API that the marketing team can easily consume.
Building the Solution
With the high-level design in place, we can start building a solution. Using my Salesforce login, I was able to navigate to the Accounts screen to view the data for this exercise. Here is an example of the first page of enterprise data:
Create a Heroku App
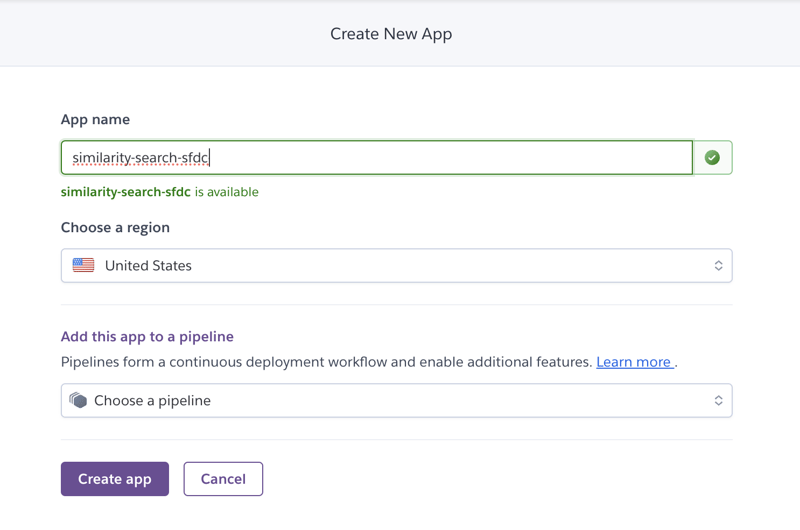
For this effort, I planned to use Heroku to solve the marketing team’s request. I logged into my Heroku account and used the Create New App button to establish a new application called similarity-search-sfdc:
After creating the app, I navigated to the Resources tab to find the Heroku Postgres add-on. I typed “Postgres” into the add-ons search field.
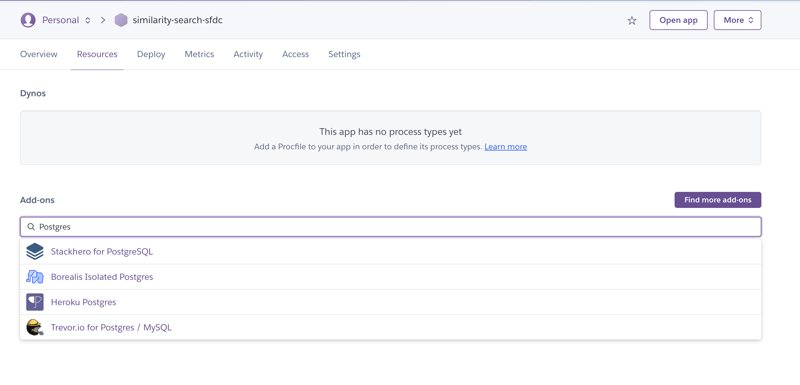
After selecting Heroku Postgres from the list, I chose the Standard 0 plan, but pgvector is available on Standard-tier (or higher) database offerings running PostgreSQL 15 or the beta Essential-tier database.

When I confirmed the add-on, Heroku generated and provided a DATABASE_URL connection string. I found this in the Config Vars section of the Settings tab of my app. I used this information to connect to my database and enable the pgvector extension like this:
CREATE EXTENSION vector;
Next, I searched for and found the Heroku Connect add-on. I knew this would give me an easy way to connect to the enterprise data in Salesforce.
For this exercise, the free Demo Edition plan works just fine.
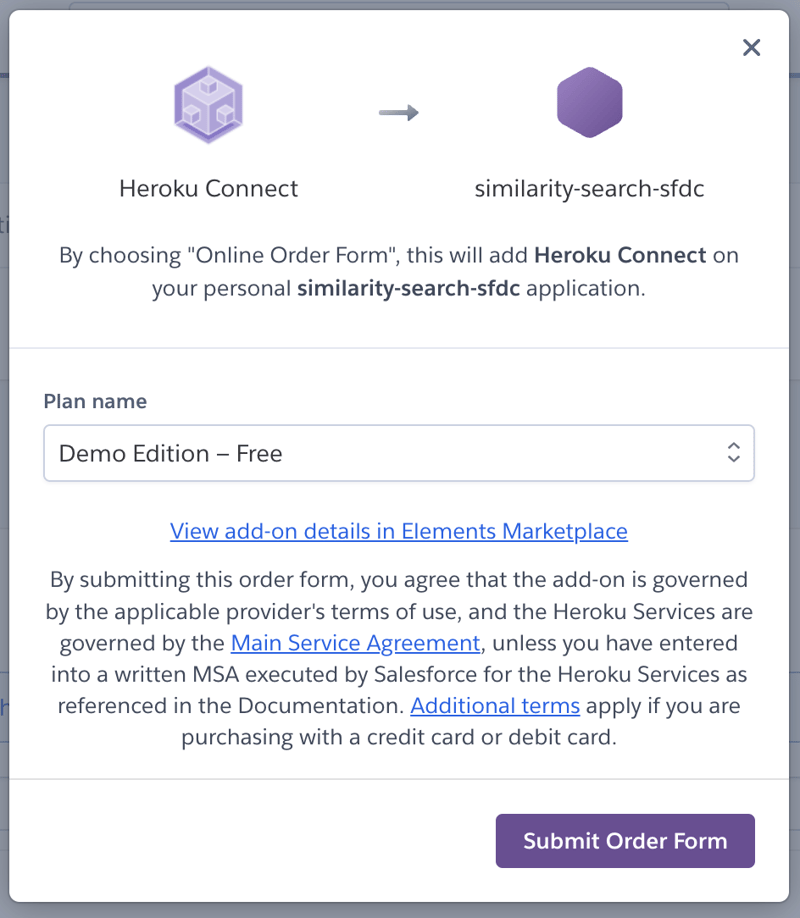
At this point, the Resources tab for the similarity-search-sfdc app looked like this:
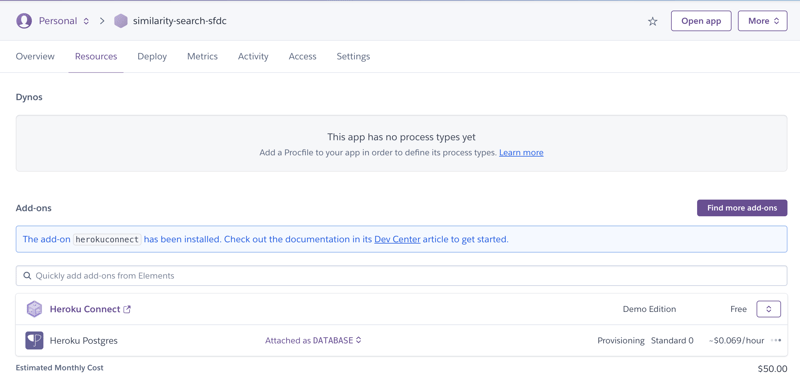
I followed the “Setting Up Heroku Connect” instructions to link my Salesforce account to Heroku Connect. Then, I selected the Account object for synchronization. Once completed, I was able to see the same Salesforce account data in Heroku Connect and in the underlying Postgres database.
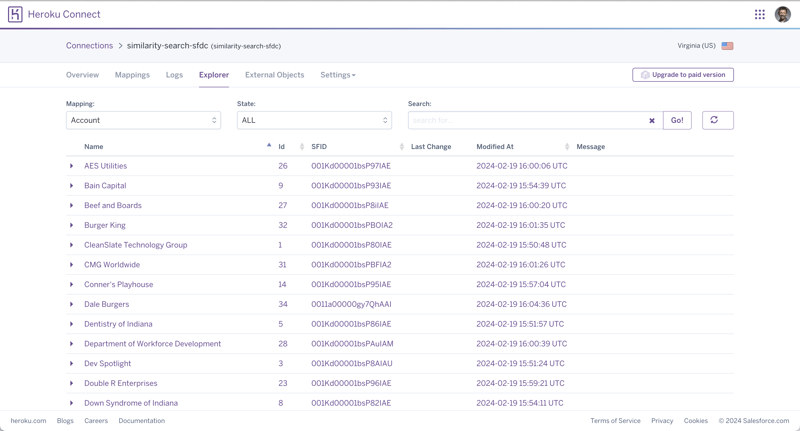
From a SQL perspective, what I did resulted in the creation of a salesforce.account table with the following design:
create table salesforce.account
(
createddate timestamp,
isdeleted boolean,
name varchar(255),
systemmodstamp timestamp,
accountnumber varchar(40),
industry varchar(255),
sfid varchar(18),
id serial
primary key,
_hc_lastop varchar(32),
_hc_err text
);
Generate Vectors
In order for the similarity search to function as expected, I needed to generate word vectors for each Salesforce account industry:
Apparel
Banking
Biotechnology
Construction
Education
Electronics
Engineering
Entertainment
Food & Beverage
Finance
Government
Healthcare
Hospitality
Insurance
Media
Not For Profit
Other
Recreation
Retail
Shipping
Technology
Telecommunications
Transportation
Utilities
Since the primary use case indicated the need to find similarities for the software industry, we would need to generate a word vector for that industry too.
To keep things simple for this exercise, I manually executed this task using Python 3.9 and a file called embed.py, which looks like this:
from wikipedia2vec import Wikipedia2Vec
wiki2vec = Wikipedia2Vec.load('enwiki_20180420_100d.pkl')
print(wiki2vec.get_word_vector('software').tolist())
Please note – the get_word_vector() method expects a lowercase representation of the industry.
Running python embed.py generated the following word vector for the software word:
[-0.40402618050575256, 0.5711150765419006, -0.7885153293609619, -0.15960034728050232, -0.5692323446273804,
0.005377458408474922, -0.1315757781267166, -0.16840921342372894, 0.6626015305519104, -0.26056772470474243,
0.3681095242500305, -0.453583300113678, 0.004738557618111372, -0.4111144244670868, -0.1817493587732315,
-0.9268549680709839, 0.07973367720842361, -0.17835664749145508, -0.2949991524219513, -0.5533796548843384,
0.04348105192184448, -0.028855713084340096, -0.13867013156414032, -0.6649054884910583, 0.03129105269908905,
-0.24817068874835968, 0.05968991294503212, -0.24743635952472687, 0.20582349598407745, 0.6240783929824829,
0.3214546740055084, -0.14210252463817596, 0.3178422152996063, 0.7693028450012207, 0.2426985204219818,
-0.6515568494796753, -0.2868216037750244, 0.3189859390258789, 0.5168254971504211, 0.11008890718221664,
0.3537853956222534, -0.713259220123291, -0.4132286608219147, -0.026366405189037323, 0.003034653142094612,
-0.5275223851203918, -0.018167126923799515, 0.23878540098667145, -0.6077089905738831, 0.5368344187736511,
-0.1210874393582344, 0.26415619254112244, -0.3066694438457489, 0.1471938043832779, 0.04954215884208679,
0.2045321762561798, 0.1391817331314087, 0.5286830067634583, 0.5764685273170471, 0.1882934868335724,
-0.30167853832244873, -0.2122340053319931, -0.45651525259017944, -0.016777794808149338, 0.45624101161956787,
-0.0438646525144577, -0.992512047290802, -0.3771328926086426, 0.04916151612997055, -0.5830298066139221,
-0.01255014631897211, 0.21600870788097382, -0.18419665098190308, 0.1754663586616516, -0.1499166339635849,
-0.1916201263666153, -0.22884036600589752, 0.17280352115631104, 0.25274306535720825, 0.3511175513267517,
-0.20270302891731262, -0.6383468508720398, 0.43260180950164795, -0.21136239171028137, -0.05920517444610596,
0.7145522832870483, 0.7626600861549377, -0.5473887920379639, 0.4523043632507324, -0.1723199188709259,
-0.10209759324789047, -0.5577948093414307, -0.10156919807195663, 0.31126976013183594, 0.3604489266872406,
-0.13295558094978333, 0.2473849356174469, 0.278846800327301, -0.28618067502975464, 0.00527254119515419]
Create Table for Industries
In order to store the word vectors, we needed to add an industries table to the Postgres database using the following SQL command:
create table salesforce.industries
(
name varchar not null constraint industries_pk primary key,
embeddings vector(100) not null
);
With the industries table created, we’ll insert each of the generated word vectors. We do this with SQL statements similar to the following:
INSERT INTO salesforce.industries
(name, embeddings)
VALUES
('Software','[-0.40402618050575256, 0.5711150765419006, -0.7885153293609619, -0.15960034728050232, -0.5692323446273804, 0.005377458408474922, -0.1315757781267166, -0.16840921342372894, 0.6626015305519104, -0.26056772470474243, 0.3681095242500305, -0.453583300113678, 0.004738557618111372, -0.4111144244670868, -0.1817493587732315, -0.9268549680709839, 0.07973367720842361, -0.17835664749145508, -0.2949991524219513, -0.5533796548843384, 0.04348105192184448, -0.028855713084340096, -0.13867013156414032, -0.6649054884910583, 0.03129105269908905, -0.24817068874835968, 0.05968991294503212, -0.24743635952472687, 0.20582349598407745, 0.6240783929824829, 0.3214546740055084, -0.14210252463817596, 0.3178422152996063, 0.7693028450012207, 0.2426985204219818, -0.6515568494796753, -0.2868216037750244, 0.3189859390258789, 0.5168254971504211, 0.11008890718221664, 0.3537853956222534, -0.713259220123291, -0.4132286608219147, -0.026366405189037323, 0.003034653142094612, -0.5275223851203918, -0.018167126923799515, 0.23878540098667145, -0.6077089905738831, 0.5368344187736511, -0.1210874393582344, 0.26415619254112244, -0.3066694438457489, 0.1471938043832779, 0.04954215884208679, 0.2045321762561798, 0.1391817331314087, 0.5286830067634583, 0.5764685273170471, 0.1882934868335724, -0.30167853832244873, -0.2122340053319931, -0.45651525259017944, -0.016777794808149338, 0.45624101161956787, -0.0438646525144577, -0.992512047290802, -0.3771328926086426, 0.04916151612997055, -0.5830298066139221, -0.01255014631897211, 0.21600870788097382, -0.18419665098190308, 0.1754663586616516, -0.1499166339635849, -0.1916201263666153, -0.22884036600589752, 0.17280352115631104, 0.25274306535720825, 0.3511175513267517, -0.20270302891731262, -0.6383468508720398, 0.43260180950164795, -0.21136239171028137, -0.05920517444610596, 0.7145522832870483, 0.7626600861549377, -0.5473887920379639, 0.4523043632507324, -0.1723199188709259, -0.10209759324789047, -0.5577948093414307, -0.10156919807195663, 0.31126976013183594, 0.3604489266872406, -0.13295558094978333, 0.2473849356174469, 0.278846800327301, -0.28618067502975464, 0.00527254119515419]
');
Please note – while we created a word vector with the lowercase representation of the Software Industry (software), the industries.name column needs to match the capitalized industry name (Software).
Once all of the generated word vectors have been added to the industries table, we can change our focus to introducing a RESTful API.
Introduce a Spring Boot Service
This was the point where my passion as a software engineer jumped into high gear, because I had everything in place to solve the challenge at hand.
Next, using Spring Boot 3.2.2 and Java (temurin) 17, I created the similarity-search-sfdc project in IntelliJ IDEA with the following Maven dependencies:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.pgvector</groupId>
<artifactId>pgvector</artifactId>
<version>0.1.4</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
I created simplified entities for both the Account object and Industry (embedding) object, which lined up with the Postgres database tables created earlier.
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "account", schema = "salesforce")
public class Account {
@Id
@Column(name = "sfid")
private String id;
private String name;
private String industry;
}
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "industries", schema = "salesforce")
public class Industry {
@Id
private String name;
}
Using the JpaRepository interface, I added the following extensions to allow easy access to the Postgres tables:
public interface AccountsRepository extends JpaRepository<Account, String> {
@Query(nativeQuery = true, value = "SELECT sfid, name, industry " +
"FROM salesforce.account " +
"WHERE industry IN (SELECT name " +
" FROM salesforce.industries " +
" WHERE name != :industry " +
" ORDER BY embeddings <-> (SELECT embeddings
FROM salesforce.industries
WHERE name = :industry) " +
" LIMIT :limit)" +
"ORDER BY name")
Set<Account> findSimilaritiesForIndustry(String industry, int limit);
}
public interface IndustriesRepository extends JpaRepository<Industry, String> { }
Notice the findSimilaritiesForIndustry() method is where all the heavy lifting will take place for solving this use case. The method will accept the following parameters:
industry: the industry to find similarities forlimit: the maximum number of industry similarities to search against when querying for accounts
Note the Euclidean distance operator (<->) in our query above. This is the extension’s built-in operator for performing the similarity search.
With the original “Software” industry use case and a limit set to the three closest industries, the query being executed would look like this:
SELECT sfid, name, industry
FROM salesforce.account
WHERE industry
IN (SELECT name
FROM salesforce.industries
WHERE name != 'Software'
ORDER BY embeddings
<-> (SELECT embeddings
FROM salesforce.industries
WHERE name = 'Software')
LIMIT 3)
ORDER BY name;
From there, I built the AccountsService class to interact with the JPA repositories:
@RequiredArgsConstructor
@Service
public class AccountsService {
private final AccountsRepository accountsRepository;
private final IndustriesRepository industriesRepository;
public Set<Account> getAccountsBySimilarIndustry(String industry,
int limit)
throws Exception {
List<Industry> industries = industriesRepository.findAll();
if (industries
.stream()
.map(Industry::getName)
.anyMatch(industry::equals)) {
return accountsRepository
.findSimilaritiesForIndustry(industry, limit);
} else {
throw new Exception(
"Could not locate '" + industry + "' industry");
}
}
}
Lastly, I had the AccountsController class provide a RESTful entry point and connect to the AccountsService:
@RequiredArgsConstructor
@RestController
@RequestMapping(value = "/accounts")
public class AccountsController {
private final AccountsService accountsService;
@GetMapping(value = "/similarities")
public ResponseEntity<Set<Account>> getAccountsBySimilarIndustry(@RequestParam String industry, @RequestParam int limit) {
try {
return new ResponseEntity<>(
accountsService
.getAccountsBySimilarIndustry(industry, limit),
HttpStatus.OK);
} catch (Exception e) {
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
}
}
Deploy to Heroku
With the Spring Boot service ready, I added the following Procfile to the project, letting Heroku know more about our service:
web: java $JAVA_OPTS -Dserver.port=$PORT -jar target/*.jar
To be safe, I added the system.properties file to specify what versions of Java and Maven are expected:
java.runtime.version=17
maven.version=3.9.5
Using the Heroku CLI, I added a remote to my GitLab repository for the similarity-search-sfdc service to the Heroku platform:
heroku git:remote -a similarity-search-sfdc
I also set the buildpack type for the similarity-search-sfdc service via the following command:
heroku buildpacks:set https://github.com/heroku/heroku-buildpack-java
Finally, I deployed the similarity-search-sfdc service to Heroku using the following command:
git push heroku
Now, the Resources tab for the similarity-search-sfdc app appeared as shown below:
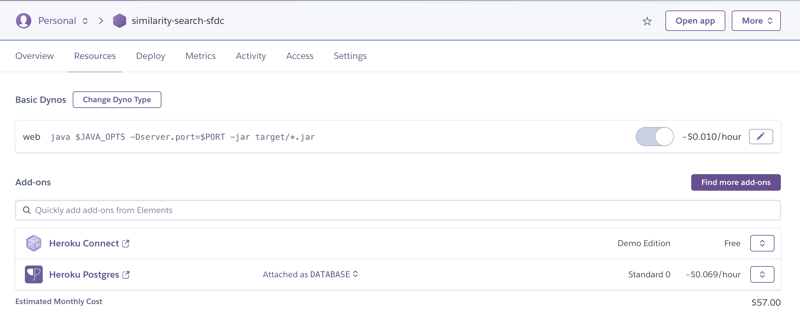
Similarity Search in Action
With the RESTful API running, I issued the following cURL command to locate the top three Salesforce industries (and associated accounts) that are closest to the Software industry:
curl --location 'https://HEROKU-APP-ROOT-URL/accounts/similarities?industry=Software&limit=3'
The RESTful API returns a 200 OK HTTP response status along with the following payload:
[
{
"id": "001Kd00001bsP80IAE",
"name": "CleanSlate Technology Group",
"industry": "Technology"
},
{
"id": "001Kd00001bsPBFIA2",
"name": "CMG Worldwide",
"industry": "Media"
},
{
"id": "001Kd00001bsP8AIAU",
"name": "Dev Spotlight",
"industry": "Technology"
},
{
"id": "001Kd00001bsP8hIAE",
"name": "Egghead",
"industry": "Electronics"
},
{
"id": "001Kd00001bsP85IAE",
"name": "Marqeta",
"industry": "Technology"
}
]
As a result, the Technology, Media, and Electronics industries are the closest industries to the Software industry in this example.
Now, the marketing department has a list of accounts they can contact for their next campaign.
Conclusion
Years ago, I spent more time than I would like to admit playing the Team Fortress 2 multiplayer video game. Here’s a screenshot from an event back in 2012 that was a lot of fun:
Those familiar with this aspect of my life could tell you that my default choice of player class was the soldier. This is because the soldier has the best balance of health, movement, speed, and firepower.
I feel like software engineers are the “soldier class” of the real world, because we can adapt to any situation and focus on providing solutions that meet expectations in an efficient manner.
For a few years now, I have been focused on the following mission statement, which I feel can apply to any IT professional:
“Focus your time on delivering features/functionality that extends the value of your intellectual property. Leverage frameworks, products, and services for everything else.”
- J. Vester
In the example for this post, we were able to leverage Heroku Connect to synchronize enterprise data with a Postgres database. After installing the pgvector extension, we created word vectors for each unique industry from those Salesforce accounts. Finally, we introduced a Spring Boot service, which simplified the process of locating Salesforce accounts whose industry was closest to another industry.
We solved this use case quickly with existing open-source technologies, the addition of a tiny Spring Boot service, and the Heroku PaaS – fully adhering to my mission statement. I cannot imagine how much time would be required without these frameworks, products, and services.
If you’re interested, you can find the original source code for this article on GitLab:
https://gitlab.com/johnjvester/similarity-search-sfdc
Have a really great day!


















