
Faz alguns dias que não escrevo. Minha rotina mudou um pouco e também tenho focado em estudar algumas coisas que eu não tinha tanto domínio. Entretanto tenho algumas coisas pra compartilhar.
Vamos a isso.
Rinha de compiladores
Em Setembro de 2023 aconteceu na tal #bolhaDev uma outra competição em formato de rinha, mas desta vez o desafio era a construção de um compilador/interpretador que fosse capaz de rodar um programa escrito em uma linguagem especificada para a rinha, chamada - guess what -, rinha.
A competição foi criada por duas meninas fantásticas e que entendem muito desse mundo de compiladores: a Sofia e a Gabi. Ambas tinham o intuito de despertar mais o interesse das pessoas nesse tema de compiladores, o que foi atingido com sucesso: 190 projetos foram submetidos em diversas linguagens de programação. Teve até projetos submetidos em Bash (desta vez não fui eu, risos).
Inicialmente eu só tinha interesse em acompanhar esta rinha de perto sem submeter, apenas pra aprender mais com essa galera que manja bastante. Eu já tinha feito algumas coisas bastante básicas sobre compiladores na faculdade há muito tempo atrás.
Mas após ver a live do brabo Navarro, que trouxe uma didática excelente com sua versão em Rust, decidi entrar também com o intuito de aprender mais e praticar algumas técnicas.
Escolhi Ruby porque eu queria testar um negócio. E disto saiu o patropi.
Okay, mas o que era pra ser feito de fato? Vamos voltar duas casas e entender primeiro o que raios é um compilador ou interpretador.
👉🏽 Arquitetura de CPU e código de máquina
Para que uma CPU possa processar informações, é necessário organizá-la em um conjunto coeso de instruções. A este conjunto organizado de instruções para uma determinada CPU chamamos de arquitetura da CPU.
Existem diversos tipos de arquiteturas de CPU disponíveis, e cada CPU traz um conjunto específico de instruções. Exemplos de arquiteturas: x86, x86-64 (64-bits), ARM (baseada em RISC), MIPS, SPARC, PowerPC dentre outros.
As instruções da CPU são mapeadas para componentes da arquitetura chamados registradores. Para manipularmos esses registradores, precisamos utilizar um conjunto de "códigos" que são pré-definidos pelo fabricante da arquitetura da CPU. Estes códigos são chamados de opcodes, ou código de máquina, ou instruções de máquina.
0000000000401000
401000: 48 c7 c0 01 00 00 00
401007: 48 c7 c7 01 00 00 00
40100e: 48 c7 c6 00 20 40 00
401015: 48 c7 c2 0e 00 00 00
40101c: 0f 05
40101e: 48 c7 c0 3c 00 00 00
401025: 48 31 ff
401028: 0f 05
Escrever programas em código de máquina pode ser bastante desafiador, por isso alguns sistemas operacionais e bibliotecas trazem consigo um programa que auxilia na "montagem" desse código de máquina, possibilitando assim escrever programas em uma linguagem mnemônica com base em letras, números e símbolos, sendo mais fácil de memorizar do que os opcodes.
A estes montadores chamamos de assemblers.
👉🏽 Assemblers
Com um assembler, podemos escrever código de montagem (assembly), que é convertido para código de máquina.
Exemplo de um simples programa escrito em assembly x86_64 que imprime Hello, World! no standard output:
.section .data
hello:
.ascii "Hello, World!\n"
.section .text
.global _start
_start:
# write our string to stdout
movq $1, %rax # syscall number for sys_write
movq $1, %rdi # file descriptor 1 is stdout
movq $hello, %rsi # pointer to the hello string
movq $14, %rdx # length of the hello string plus newline character
syscall # invoke the kernel
# exit
movq $60, %rax # syscall number for sys_exit
xorq %rdi, %rdi # exit code 0
syscall # invoke the kernel
Após executar o programa com o assembler as que vem acompanhado no GNU/Linux seguido do linker ld, temos o binário com o código de máquina.
$ as -o hello.o hello.s
$ ld -o hello hello.o
$ ./hello
Hello, World!
Uma forma de fazer o "disassembly" do binário e ver o assembly equivalente, é com o utilitário objdump, onde podemos ver as instruções de máquina (opcodes) mapeadas para cada instrução assembly contida no nosso código fonte:
$ objdump -d hello
hello: file format elf64-x86-64
Disassembly of section .text:
0000000000401000 <_start>:
401000: 48 c7 c0 01 00 00 00 mov $0x1,%rax
401007: 48 c7 c7 01 00 00 00 mov $0x1,%rdi
40100e: 48 c7 c6 00 20 40 00 mov $0x402000,%rsi
401015: 48 c7 c2 0e 00 00 00 mov $0xe,%rdx
40101c: 0f 05 syscall
40101e: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
401025: 48 31 ff xor %rdi,%rdi
401028: 0f 05 syscall
Espetacular, não?
👉🏽 Tá, mas e os compiladores?
Os compiladores entram justamente na categoria de programas de mais alto nível que convertem para o assembly da arquitetura em questão ou diretamente para código de máquina.
Por exemplo, este simples programa escrito em C:
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
Pode ser compilado para código de máquina utilizando o compilador gcc:
$ gcc -o hello hello.c
$ ./hello
Hello, World!
É muito comum também compiladores converterem para uma representação intermediária (IR) antes de gerar o código de máquina, como é o caso do próprio gcc, LLVM, dentre outros.
👉🏽 E os interpretadores?
A distinção e similaridade entre compiladores e interpretadores não é um senso bastante comum, embora algumas pessoas entendam que interpretador é um tipo de compilador.
Indo pelo sentido prático, podemos dizer que o compilador compila para instrução de máquina. Enquanto que o interpretador vai lendo linha por linha do código fonte e executando.
Interpretadores modernos possuem um processo interno de compilação em tempo real, chamado just-in-time, ou JIT, o que pode inclusive caracterizar interpretadores também no rol de compiladores.
Independente da definição correta ou não de compiladores/interpretadores, uma coisa que devemos ter em mente é que estão acontecendo diversas transformações em camadas até chegar ao código de máquina.
Nesse processo de transformação, acontecem análises e otimizações que vão afetar drasticamente a performance do programa.
👉🏽 Frontend vs Backend
Você pensava que a briga front vs back existia apenas na web, pois não? No mundo dos compiladores também!
To brincando, gente. Não tem briga nenhuma não
Frontend é a etapa que faz a leitura do código fonte e gera uma árvore sintática. Esta árvore, como o próprio nome diz, segue uma estrutura de dados muito comum na computação, o que permite a análise de programas seguindo o conjunto de regras definido na gramática.
Basicamente, o frontend faz a análise léxica (gerando tokens válidos da especificação), e em seguida a análise sintática (parsing dos tokens), gerando a árvore sintática abstrata, ou AST.
Com a AST, o frontend pode ainda realizar análise semântica e até mesmo gerar um código intermediário (IR), se for o caso.
Já no Backend consiste na etapa de, a partir de uma AST ou IR, aplicar otimizações, análise estática (também chamada de ahead-of-time compilation, ou AOT), compilação em tempo de execução (JIT) e por fim a geração de assembly ou código de máquina.
Resumindo, então, alguns tipos de assemblers e compiladores:
1) Assemblers
- NASM
- GNU as
2) Frontend
- Clang (para LLVM)
- GCC
- javac
3) Backend
- LLC/LLI (para LLVM)
- GCC
- JVM
👉🏽 Okay mas e a rinha
Na rinha, foi disponibilizado um frontend para a especificação da linguagem, em formato de Rust crate.
Bastando ter o Rust instalado, adicionamos a crate e, através do comando rinha, temos uma representação JSON da AST:
# examples/hello.rinha
print("Hello, world")
# run frontend
$ rinha -p examples/hello.rinha
{
"name": "examples/hello.rinha",
"expression": {
"kind": "Print",
"value": {
"kind": "Str",
"value": "Hello, world",
"location": {
"start": 6,
"end": 20,
"filename": "examples/hello.rinha"
}
...........
O desafio? Escrever um compilador/interpretador para este AST. Simples assim.
Patropi e o trampolim
Minha submissão escrita em Ruby foi batizada de Patropi (idk either). Optei por fazer um interpretador no formato tree-walking interpreter, que basicamente vai caminhando por cada nó da AST e executando.
Como não sou especialista em compiladores e otimizações, pra mim foi o caminho mais sensato naquele momento.
Um exemplo de código muito simples em Ruby, para interpretar o simples print("Hello world"):
def evaluate(term)
case term
in { kind: 'Str', value: value }; value.to_s
in { kind: 'Print', value: next_term }; puts evaluate(next_term)
else raise "Unknown term: #{term}"
end
end
Note que o método evaluate é nosso ponto focal. Ele recebe um termo (nó da AST) e tenta buscar por um match específico. Caso dê match com uma String literal, retorna o valor. Mas se der match com um nó Print, chama o evaluate recursivamente.
👉🏽 Recursão
Recursão é o caminho mais intuitivo para manipular uma árvore na computação. Quase todo compilador é feito inicialmente de forma recursiva na manipulação da árvore justamente porque é intuitivo.
Enquanto há nó para percorrer, vou chamar minha função novamente, até chegar no fim do galho
Não vou entrar muito nos detalhes dos trade-offs da recursão, mas se quiser se aprofundar nisto, sugiro a leitura do artigo que escrevi sobre fundamentos de recursão.
Com isto em mente, e sabendo que o pessoal na rinha iria executar alguns programas que exigem muito da memória stack, decidi experimentar uma estratégia não muito ortodoxa e que funciona como alternativa à recursão quando otimizações de recursão de cauda não são possíveis ou são muito limitadas.
A esta estratégia (que também explico com detalhes no artigo apontado), chamamos de Trampoline, ou trampolim.
👉🏽 Trampolim para o resgate
Basicamente, ao invés de chamar a função recursivamente, eu devolvo uma estrutura chamada "continuation", passando o controle para um loop fora da função.
Este loop imperativo toma a decisão de executar uma closure com o valor passado na continuation ou se vai para o próximo nó da árvore. A cada iteração do loop, por não haver chamada recursiva, não há acúmulo na stack frame, portanto diminui drasticamente a chance de acontecer stack buffer overflow, ou seja, praticamente não há chance de estouro de pilha.
Aqui segue uma imagem com a arquitetura do Patropi:
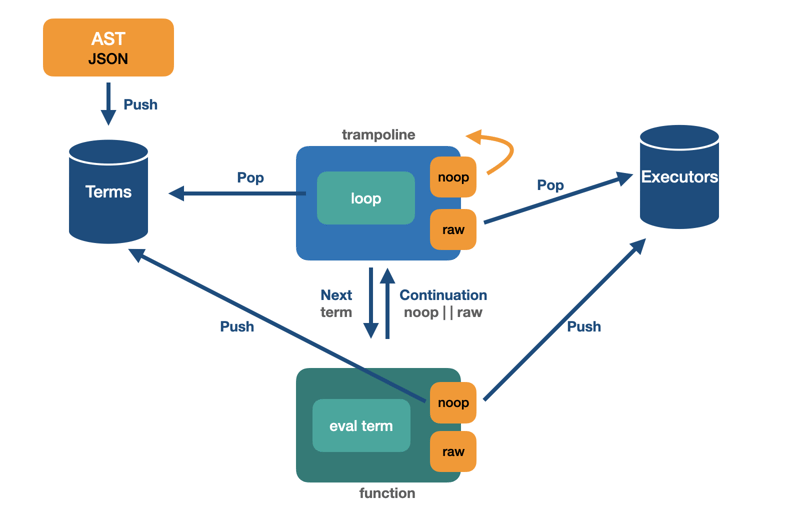
Para mais detalhes de código, basta seguir o link do repositório no Github
👉🏽 And the Oscar goes to...
O ranking oficial está divulgado no repositório da rinha, e em primeiro lugar ficou uma solução escrita em Golang de tree-walking interpreter. Achei incrível, here we "Go" again :P
Minha solução em Ruby, o Patropi, das 190 submissões, ficou entre as 68 que rodaram, amargando a 65ª posição.
Apesar de ter sido divertido implementar o trampolim, Patropi não soube lidar muito bem com Tuplas e falhou em diversos testes...
Fila duplamente terminada em Go
Neste intervalo de estudos, aproveitei também para contribuir para um projeto de algoritmos e estruturas de dados no Github. A ideia do repositório é muito boa, basicamente ali tem dezenas de algoritmos que podem ser implementados por qualquer pessoa em diversas linguagens. Basta contribuir :)
Aproveitei a deixa para submeter alguns algoritmos e estruturas de dados em Rust, Go e Ruby. Mas queria destacar uma fila duplamente terminada (double-ended queue, ou deque) que fiz em Go.
Deque é uma estrutura de dados de fila que permite adicionar ou remover elementos em qualquer um dos lados.
Por exemplo, uma pilha permite adicionar e remover em apenas um lado (LIFO). Em uma fila, adicionamos a um lado e removemos do outro (FIFO).
A versatilidade da deque permite na média um acesso em tempo constante em ambos os lados (início da fila ou fim), tanto para adição (push) ou remoção (pop).
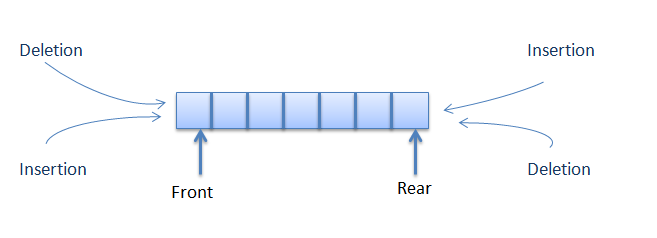
Um caso prático de deque seria no histórico de um navegador web, por exemplo. Como o armazenamento no navegador é limitado, o histórico precisa ter um limite de tamanho. Portanto adicionar e remover em ambas extremidades com o mesmo custo passa a ser uma vantagem neste cenário.
Em Go, poderíamos implementar em baby-steps da seguinte forma. Primeiro, definimos a type struct que terá um slice de inteiros:
package main
import "fmt"
type Deque struct {
Store []int
}
Agora, temos que implementar as operações do lado direito, Rpush e RPop:
func (deque *Deque) RPush(element int) {
deque.Store = append(deque.Store, element)
}
func (deque *Deque) RPop() *int {
if len(deque.Store) == 0 {
return nil
}
element := deque.Store[len(deque.Store)-1]
deque.Store = deque.Store[:len(deque.Store)-1]
return &element
}
- RPush: utiliza o built-in
appendno lado direito, que é uma operação constante - RPop: manipula o slice, trabalhando apenas com os índices
Para terminar, fazer o mesmo do lado esquerdo:
func (deque *Deque) LPush(element int) {
deque.Store = append([]int{element}, deque.Store...)
}
func (deque *Deque) LPop() *int {
if len(deque.Store) == 0 {
return nil
}
element := deque.Store[0]
deque.Store = deque.Store[1:]
return &element
}
No lado esquerdo, as operações passam a ter um custo linear, mas na média, por ser uma fila duplamente terminada, esse custo é amortizado caindo pra constante.
Thread pool no Adelnor
Pra finalizar, meu projetinho xodó do momento, o leandronsp/adelnor, precisava de uns ajustes importantes. Cada request HTTP era servido dentro da thread principal, não havia qualquer tipo de concorrência, e portanto o server não conseguia entregar muitos requests.
Resolvi implementar uma thread pool modesta submetendo este PR, em live na Twitch e também no Youtube.
$ gem install adelnor
require 'adelnor'
app = -> (env) do
[200, { 'Content-Type' => 'text/html' }, 'Hello world!']
end
Adelnor::Server.run app, 3000, thread_pool: 5
Foi um processo interessante. Após subir o server com uma pool de 5 threads, a app conseguiu entregar 4x mais requests do que na versão single-threaded.
E caso queira aprender mais sobre threads em Ruby, recomendo muito este guia.
Conclusão
É isto que tive experimentando ultimamente. No momento, estou fazendo algumas melhorias no Adelnor, nomeadamente implementar modelo de atores com Ractors, mas vou entrar em detalhes disto num blogpost à parte.
Referências
CPU architecture
x86 instructions chart
Crafting Interpreters
Rinha de compiladores
reu/rinha-compiladores
leandronsp/patropi
Fundamentos de Recursão
Double-ended queue
workingwithruby.com
leandronsp/adelnor

















