
❔ About
Sometimes, you may need a convenient yet powerful way to run many LLMs locally with:
-
Only
CPU(i5like) -
Little
RAM(eg<= 8Go) - Being able to plug third party frameworks (
Langchain,LlamaIndex) so you can build complex projects - Ease of use (few lines of code, powerful results)
👉 This is all what this post is about.
🎯 What you'll learn
In this short demo, you'll see how to:
- Run on Kaggle (CPU)
- Use
ollamato run open source models - Play with a first
LlamaIndexexample
💡 Benefits & opportunities
Get rid of weekly GPU usage limits on free plan:
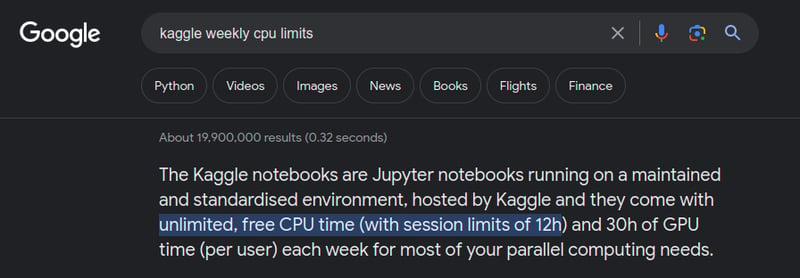
With this CPU approach, you are then able to schedule AI based workflow for free (as long as it does not exceed the 12h window limit).
🍿 Demo
Enough teasing, let's jump in the demo:
📜 Notebook
🔭 Further, stronger
To go further (48GB of RAM required, as well as GPU ), a full example around mixtral, see Running Mixtral 8x7 locally with LlamaIndex.


















