
At CodeSandbox, we run your repository and turn it into a link you can share with anyone. People visiting this link can not only see your running code, they can click "fork" and get an exact copy of that environment within 2 seconds so they can easily contribute back or play with the code. Give it a try with this Next.js example or import your GitHub repo!
Maybe you've experienced this before. You're working on a new feature that introduces some database migrations. You're almost done with the feature, but you get pulled aside because there's a bug that has to be fixed right now.
You want to fix the bug, but now you first have to roll back your migrations before changing the branch. And then after you've fixed the bug, you have to go back to your feature branch and re-run the migrations!
How great would it be if you didn't have to think about this? Ideally, you should get a new copy of your database when you change your branch.
With CodeSandbox, we're making this happen. Once your repository is imported into CodeSandbox, we give every branch and pull request a unique database.
In this post, I'll show how you can achieve this and how it works under the hood.
How does it work?
With CodeSandbox, you get a new cloud development environment for every branch and pull request. We enable this through VM cloning.
Here's an example. When you import your repository on CodeSandbox, we create a microVM for the main branch. You can see this as a template. Whenever you create a new branch, we clone the microVM main and switch the new VM to the new branch.
The VM clone is not only a clone of the filesystem, but also of the memory. If you want to learn more about how this works, we have an in-depth post about that.
This means that if you're running a database in the main VM, new branches will automatically get an exact clone (schema + data) of this database!
See this in action in the video below.
This doesn't only apply to branches. We also create a microVM for every pull request. This way, you can use CodeSandbox to test your pull requests as well, without deploying to staging or running migrations locally 🎉
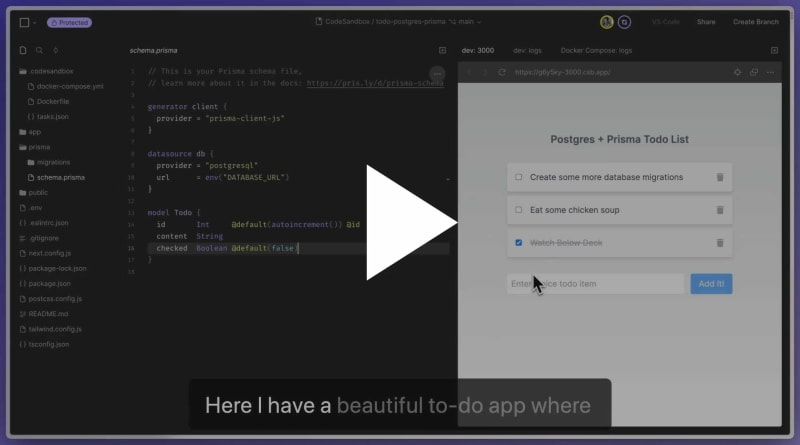
Let's see a demo of this in action that you can actually play with!
In this sandbox, I have an embed of this todo app where it fetches its data from a Postgres database. If you clone it (by clicking "Fork"), you'll get a microVM with the exact same database and data. Try it out!
How to set it up
To enable a unique database for every branch and PR, you need to first import your repository into CodeSandbox. You can do this by going to your dashboard and clicking "Import repository". We'll automatically open the main branch for you in the web editor.
Note that we also have an iOS app and a VS Code extension that you can use to open any branch.
Now, we need to configure the database! First, let's create a new branch, so that we're not making changes on the main branch directly. You can do this by clicking on "Create Branch" in the top right, and it will take you to a new branch (and microVM!) with an autogenerated name.
Once you're in this branch, you can configure your database with our docker-compose integration. To do this, you need to create a new file called docker-compose.yml in the .codesandbox folder. This file will be automatically picked up by CodeSandbox and used to run your database.
An example docker-compose.yml looks like this:
version: "3.8"
services:
db:
image: postgres:14.1-alpine
restart: always
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
ports:
- "5432:5432"
volumes:
- db:/var/lib/postgresql/data
volumes:
db:
After configuring docker-compose, we recommend restarting the VM to verify that everything is configured properly. You can do this by clicking "Restart Branch" in the menu on the left corner.

When that's done, you will have a branchable database that will automatically be provisioned for every branch and pull request!
Once you've merged the branch to main, you can add some seed data to the database—this way, every new branch will get the seed data as well.
Finally, we highly recommend installing the CodeSandbox GitHub App. This will provision a prebuilt development environment (with its own database) for every pull request.
Final thoughts
This VM cloning concept is powerful.
Plus, it applies to more than just databases. You can run Redis, or maybe Elasticsearch, and every PR will get a unique copy of that service, provisioned from the main branch.
We're all about removing time-consuming steps from the development workflow. That's why we see this as a major win for anyone working with databases.
If you're curious about testing this out, the best place to start is by installing the CodeSandbox GitHub App. Then, you'll have this in place for every PR and never have to roll back migrations in branches anymore!


















