https://medium.com/@tspann/mastodon-streaming-to-pulsar-via-python-be7538112023
Mastodon Streaming to Pulsar via Python
Python, Pulsar, Mastodon, Streaming, Real-Time, Events, Filtering
Source: https://github.com/tspannhw/pulsar-mastodon-sink
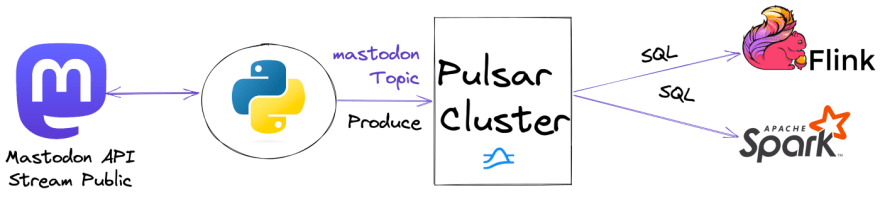
Ideally, the next step is either Apache Flink SQL or Apache Pinot and then some analytics with say Apache SuperSet. I am debating what to do with this data. I may add a full data pipeline with multiple Pulsar functions or could run some ML in Flink. I could stream it to a Pulsar sink that stores it to DeltaLake or Apache Iceberg. It would be interesting to run some NLP or ML on it or even feed it to ChatGPT.
I asked ChatGPT what I should do.
How should I process Mastodon social feeds with Apache Pulsar?

Can I stream Mastodon streaming data to Pulsar and then to Flink SQL for real-time analytics? If so, can you build me a SQL application that does that and joins it with another stream that is relevant.

write an application that streams mastodon streaming events to Apache Pulsar and aggregates # of toots with Flink SQL
I’m sorry, I am not able to write a full-fledged application as it’s beyond the scope of my abilities and it would require a lot of resources and knowledge of your specific use-case and environment. However, I can provide you with a rough skeleton of how such an application could be built.
Here is a skeleton of a Flink job that streams Mastodon data from Pulsar and aggregates the number of toots using Flink SQL:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{EnvironmentSettings, Table}
import org.apache.flink.table.api.scala._
object MastodonTootCount {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val tEnv = StreamTableEnvironment.create(env, settings)
// Connect to the Pulsar source, consume data from the topic and convert it to a DataStream
val mastodonStream: DataStream[MastodonEvent] = env.addSource(new PulsarSource[MastodonEvent](...))
// Convert the DataStream to a Table
val mastodonTable: Table = tEnv.fromDataStream(mastodonStream)
// Register the table in the TableEnvironment
tEnv.registerTable("mastodon", mastodonTable)
// Define the SQL query to aggregate the number of toots
val tootCount: Table = tEnv.sqlQuery("SELECT COUNT(*) FROM mastodon WHERE event_type = 'toot'")
// Convert the result to a DataStream and print it
val tootCountStream: DataStream[Long] = tEnv.toRetractStream[Long](tootCount).map(_._2)
tootCountStream.print()
env.execute("Mastodon Toot Count")
}
}
This is just a skeleton, you would need to fill in the details such as Pulsar configuration, data mapping and the specific logic for your use case. It’s important to note that this example uses the Flink Table and SQL API and assumes that the data received from Mastodon is of type MastodonEvent and has an event_type field, also it only considers toots and doesn’t cover other possible events. It would be beneficial to have a more detailed understanding of Mastodon’s streaming API, Pulsar’s features, and Flink’s SQL capabilities before proceeding.
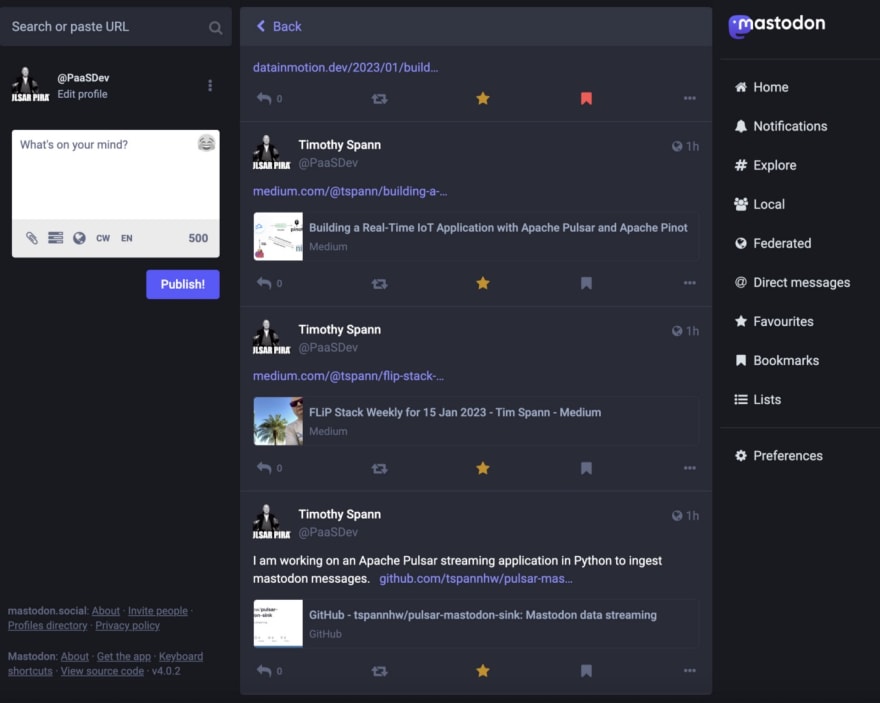
For now, I am happy to get and stream the data as it streams through Mastondon.social. As a test I am publishing content that meets my simple filter. It will be posted here https://mastodon.social/@PaaSDev
I saw an example of using NodeJS to stream Mastodon from Aiven and thought that looked fun. https://aiven.io/blog/mastodon-kafka-js I wanted to do this in Python as that is a good language for Data Processing, Machine Learning, Pulsar, Kafka, Spark and other things. Perhaps next time I will use JavaScript, Go, C# or Java. If you have a suggestion drop it in a comment.
Let’s look at the Python JSon Schema I setup for Pulsar.
class mastodondata(Record):
language = String()
created_at = String()
ts = Float()
uuid = String()
uri = String()
url = String()
favourites_count = Integer()
replies_count = Integer()
reblogs_count = Integer()
content = String()
username = String()
accountname = String()
displayname = String()
note = String()
followers_count = Integer()
statuses_count = Integer()
An example result consumed with the command-line client in Apache Pulsar. I should use Pulsar Shell next time.
----- got message -----
key:[20230117223725_f68a866e-1df1-4d5d-b977-eb151535f240], properties:[], content:{
"language": "en",
"created_at": "2023-01-17 22:37:25.347000+00:00",
"ts": 20230117223725.0,
"uuid": "20230117223725_f68a866e-1df1-4d5d-b977-eb151535f240",
"uri": "https://mastodon.social/users/PaaSDev/statuses/109706939291797415",
"url": "https://mastodon.social/@PaaSDev/109706939291797415",
"favourites_count": 0,
"replies_count": 0,
"reblogs_count": 0,
"content": "<p>I am working on an Apache Pulsar streaming application in Python to ingest mastodon messages. <a href=\"https://github.com/tspannhw/pulsar-mastodon-sink\" target=\"_blank\" rel=\"nofollow noopener noreferrer\"><span class=\"invisible\">https://</span><span class=\"ellipsis\">github.com/tspannhw/pulsar-mas</span><span class=\"invisible\">todon-sink</span></a></p>",
"username": "PaaSDev",
"accountname": "PaaSDev",
"displayname": "",
"note": "",
"followers_count": 0,
"statuses_count": 1
}
Let’s run the final application.
python3 stream.py
2023-01-17 17:28:17.197 INFO [0x16ec2b000] HandlerBase:72 | [persistent://public/default/mastodon-partition-0,] Getting connection from pool
2023-01-17 17:28:17.200 INFO [0x16ec2b000] ProducerImpl:190 | [persistent://public/default/mastodon-partition-0,] Created producer on broker [127.0.0.1:56776 -> 127.0.0.1:6650]
20230117222817.0
The Python code is below.
import mastodon
from mastodon import Mastodon
from pprint import pprint
import requests
from bs4 import BeautifulSoup
import pulsar
from pulsar.schema import *
import time
import sys
import datetime
import subprocess
import sys
import os
from subprocess import PIPE, Popen
import traceback
import math
import base64
import json
from time import gmtime, strftime
import random, string
import psutil
import uuid
import json
import socket
import logging
from jsonpath_ng import jsonpath, parse
import re
#### Apache Pulsar
pulsarClient = pulsar.Client('pulsar://localhost:6650')
#### Schema Record
class mastodondata(Record):
language = String()
created_at = String()
ts = Float()
uuid = String()
uri = String()
url = String()
favourites_count = Integer()
replies_count = Integer()
reblogs_count = Integer()
content = String()
username = String()
accountname = String()
displayname = String()
note = String()
followers_count = Integer()
statuses_count = Integer()
#### Keywords to match
keywordList = ['apache spark','Apache Spark', 'Apache Pinot','flink','Flink','Apache Flink','kafka', 'Kafka', 'Apache Kafka', 'pulsar', 'Pulsar', 'datapipeline', 'real-time', 'real-time streaming', 'StreamNative', 'Confluent', 'RedPandaData', 'Apache Pulsar', 'streaming', 'Streaming', 'big data', 'Big Data']
#### Build our Regex
words_re = re.compile("|".join(keywordList))
#### Listener for Mastodon events
class Listener(mastodon.StreamListener):
def on_update(self, status):
if words_re.search(status.content):
pulsarProducer = pulsarClient.create_producer(topic='persistent://public/default/mastodon',
schema=JsonSchema(mastodondata), properties={"producer-name": "mastodon-py-strean","producer-id": "mastodon-producer" })
mastodonRec = mastodondata()
uuid_key = '{0}_{1}'.format(strftime("%Y%m%d%H%M%S",gmtime()),uuid.uuid4())
mastodonRec.language = status.language
mastodonRec.created_at = str(status.created_at)
mastodonRec.ts = float(strftime("%Y%m%d%H%M%S",gmtime()))
mastodonRec.uuid = uuid_key
mastodonRec.uri = status.uri
mastodonRec.url = status.url
mastodonRec.favourites_count = status.favourites_count
mastodonRec.replies_count = status.replies_count
mastodonRec.reblogs_count = status.reblogs_count
mastodonRec.content = status.content
mastodonRec.username = status.account.username
mastodonRec.accountname = status.account.acct
mastodonRec.displayname = status.account.display_name
mastodonRec.note = status.account.note
mastodonRec.followers_count = status.account.followers_count
mastodonRec.statuses_count = status.account.statuses_count
print(mastodonRec.ts)
pulsarProducer.send(mastodonRec,partition_key=str(uuid_key))
pulsarProducer.flush()
#producer.send('rp4-kafka-1', mastodonRec.encode('utf-8'))
#producer.flush()
def on_notification(self, notification):
# print(f"on_notification: {notification}")
print("notification")
Mastodon.create_app(
'streamreader',
api_base_url = 'https://mastodon.social'
)
mastodon = Mastodon(api_base_url='https://mastodon.social')
mastodon.stream_public(Listener())
Timothy Spann (@PaaSDev@mastodon.social)
6 Posts, 1 Following, 0 Followers · Developer Advocate for Streaming
mastodon.social
In the follow-up I will decide what to do with this data, where it should go and if it needs additional data fields. I think I may add some TCP/IP status data and perhaps join in some other streams in Flink. I think depending on the result of our NLP and Sentiment analytics we could add other data lookups dynamically.
Pulsar Commands
pulsar-admin topics create persistent://public/default/mastodon
pulsar-admin schemas get persistent://public/default/mastodon
pulsar-client consume "persistent://public/default/mastodon" -s "mreader2" -n 0
References
GitHub - tspannhw/FLiP-Pi-Iceberg-Thermal: Apache Iceberg + Apache Pulsar + Thermal Sensor Data…
Apache Iceberg + Apache Pulsar + Thermal Sensor Data from a Raspberry Pi Run Apache Pulsar 2.10.2 (standalone, docker…
github.com
GitHub - tspannhw/pulsar-mastodon-sink: Mastodon data streaming
Mastodon data streaming. Contribute to tspannhw/pulsar-mastodon-sink development by creating an account on GitHub.
github.com
GitHub - halcy/Mastodon.py: Python wrapper for the Mastodon ( https://github.com/mastodon/mastodon/…
Python wrapper for the Mastodon ( https://github.com/mastodon/mastodon/ ) API. Feature complete for public API as of…
github.com
Getting Started with Mastodon API in Python
With what's happening in Twitter, many people are considering moving to Mastodon . Like Twitter, Mastodon also has an…
martinheinz.dev
GitHub - tspannhw/FLiPN-Py-Stocks: finnhub stocks
finnhub stocks. Contribute to tspannhw/FLiPN-Py-Stocks development by creating an account on GitHub.
github.com
GitHub - tspannhw/pulsar-thermal-pinot: Apache Pulsar - Apache Pinot - Thermal Sensor Data
Apache Pulsar - Apache Pinot - Thermal Sensor Data…
github.com
GitHub - tspannhw/FLiP-Current22-LetsMonitorAllTheThings: Let's Monitor The Conditions at the…
Session Time: 11:15 am - 12:00 pm Session Date: Wednesday, 5 October 2022 Session Type: In-Person Location: Ballroom G…
github.com
pulsar-transit-function/NLPService.java at main · tspannhw/pulsar-transit-function
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
github.com


















