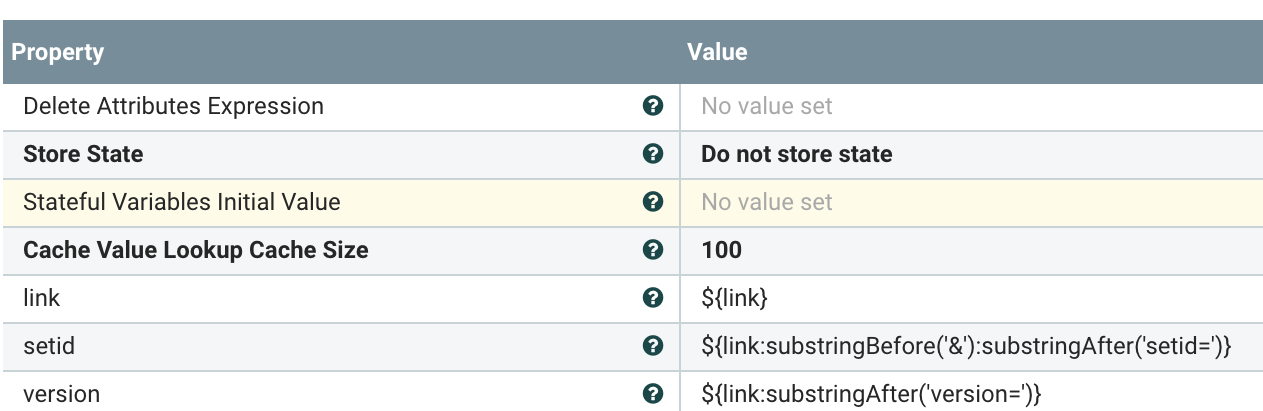
FLaNK: Using Apache Kudu As a Cache For FDA Updates

- InvokeHTTP : We invoke the RSS feed to get our data.
- QueryRecord : Convert RSS to JSON
- SplitJson : Split one file into individual records. (Should refactor to ForkRecord )
- EvaluateJSONPath : Extract attributes you need.
- ProcessGroup for SPL Processing
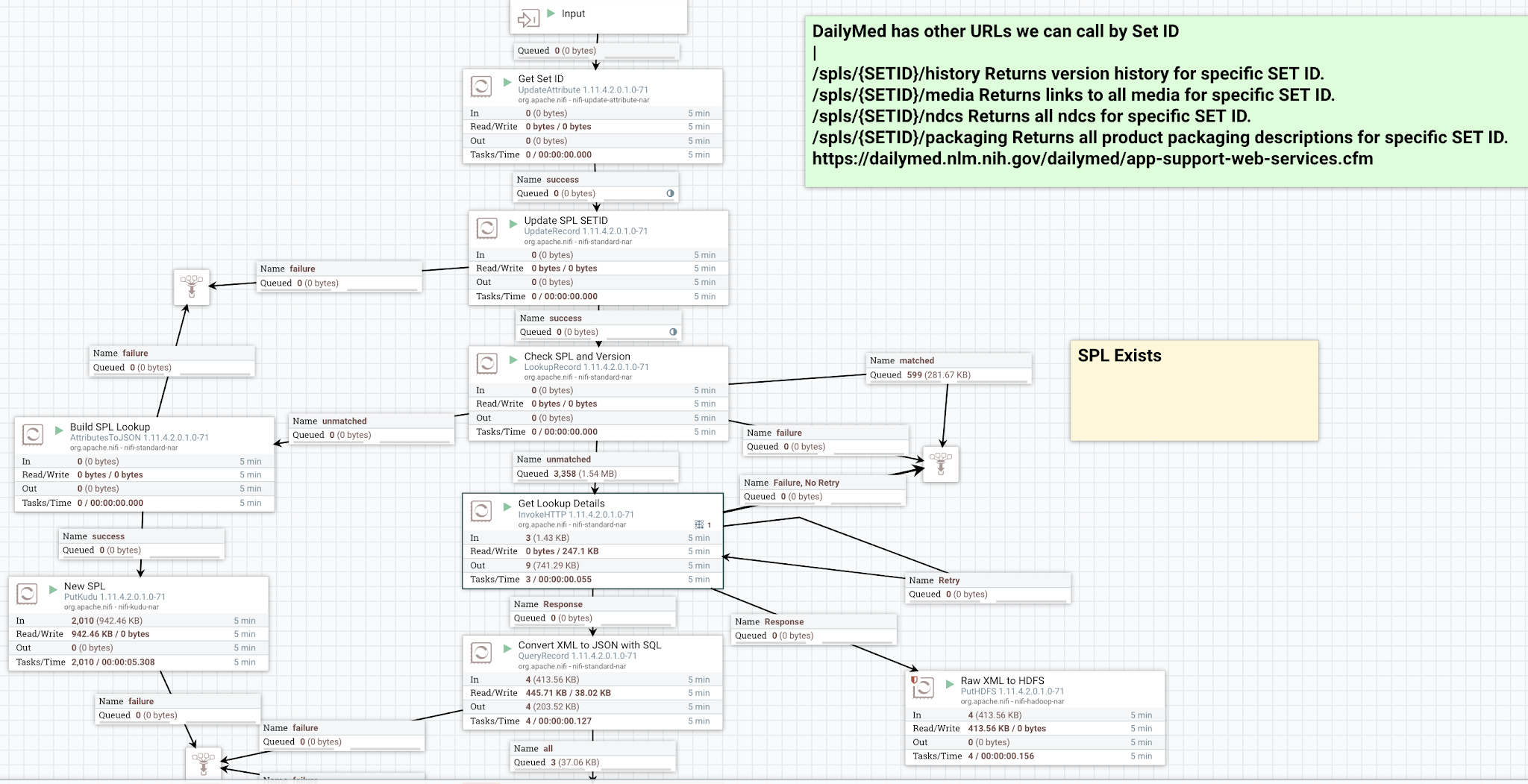
We call and check the RSS feed frequently and we parse out the records from the RSS(XML) feed and check against our cache. We use Cloudera's Real-Time Datahub with Apache Impala/Apache Kudu as our cache to see if we already received a record for that. If it hasn't arrived yet, it will be added to the Kudu cache and processed.
SPL Processing
We use the extracted SPL to grab a detailed record for that SPL using InvokeHTTP.

We have created an Impala/Kudu table to cache this information with Apache Hue.
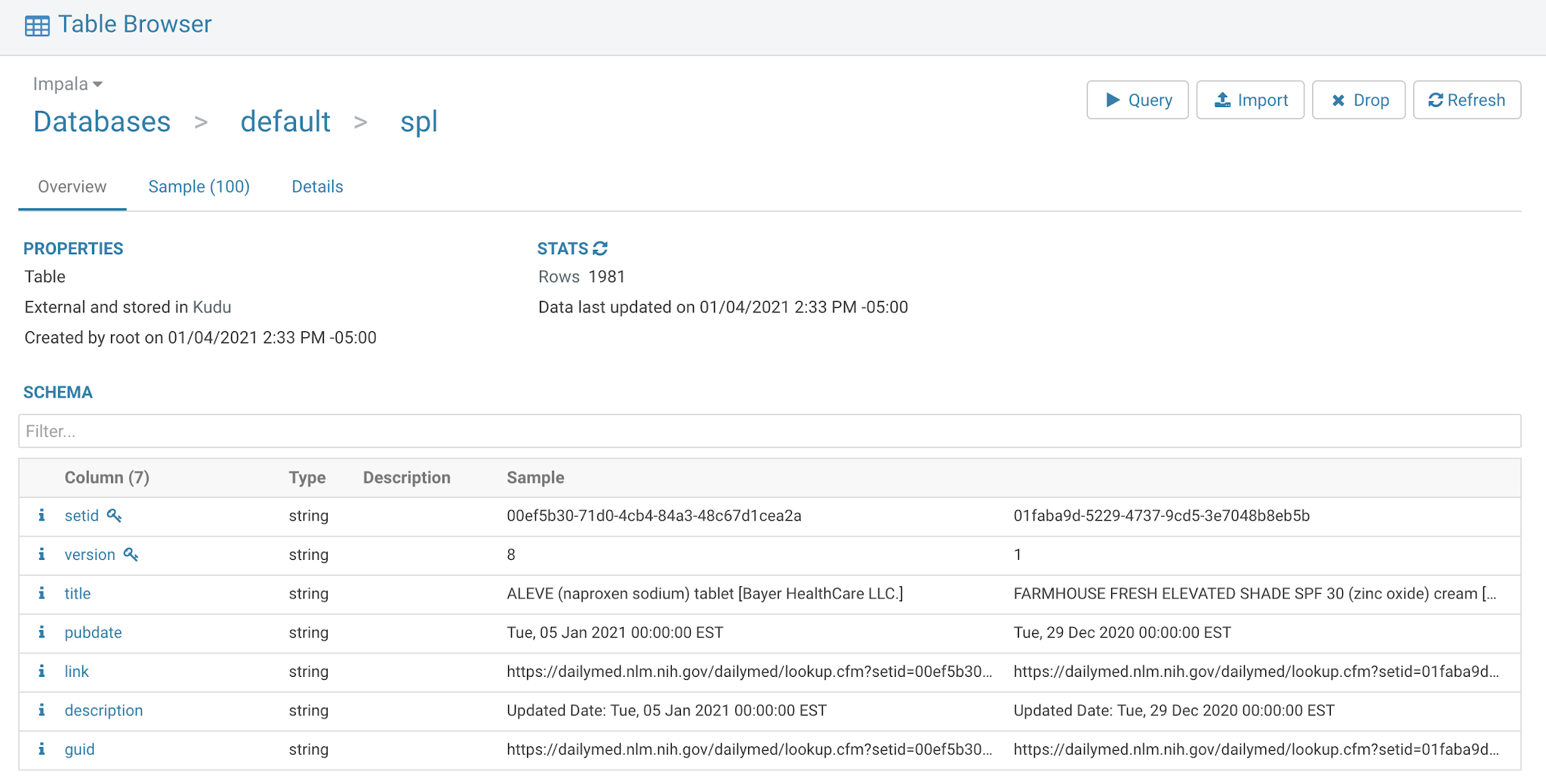
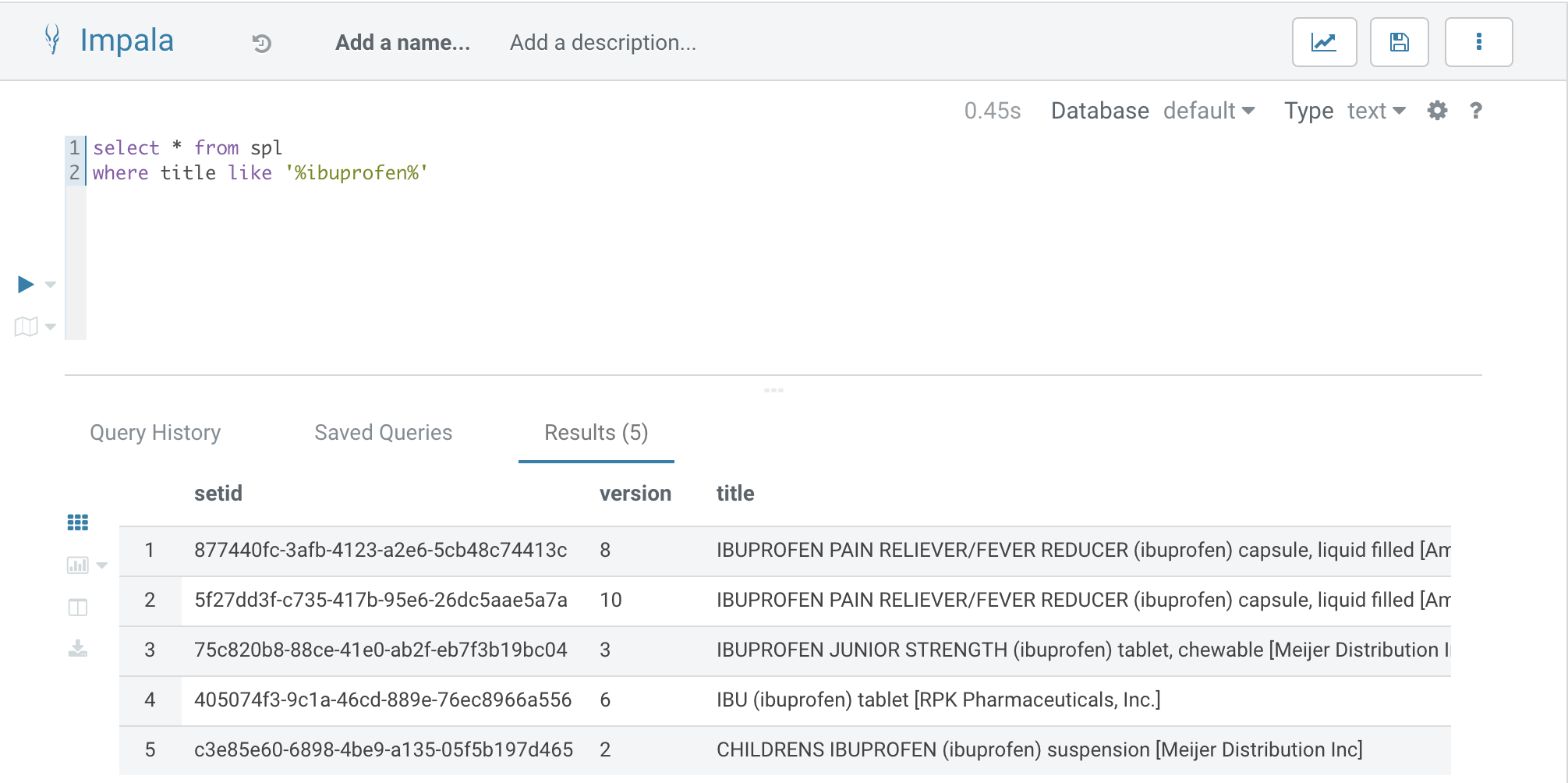
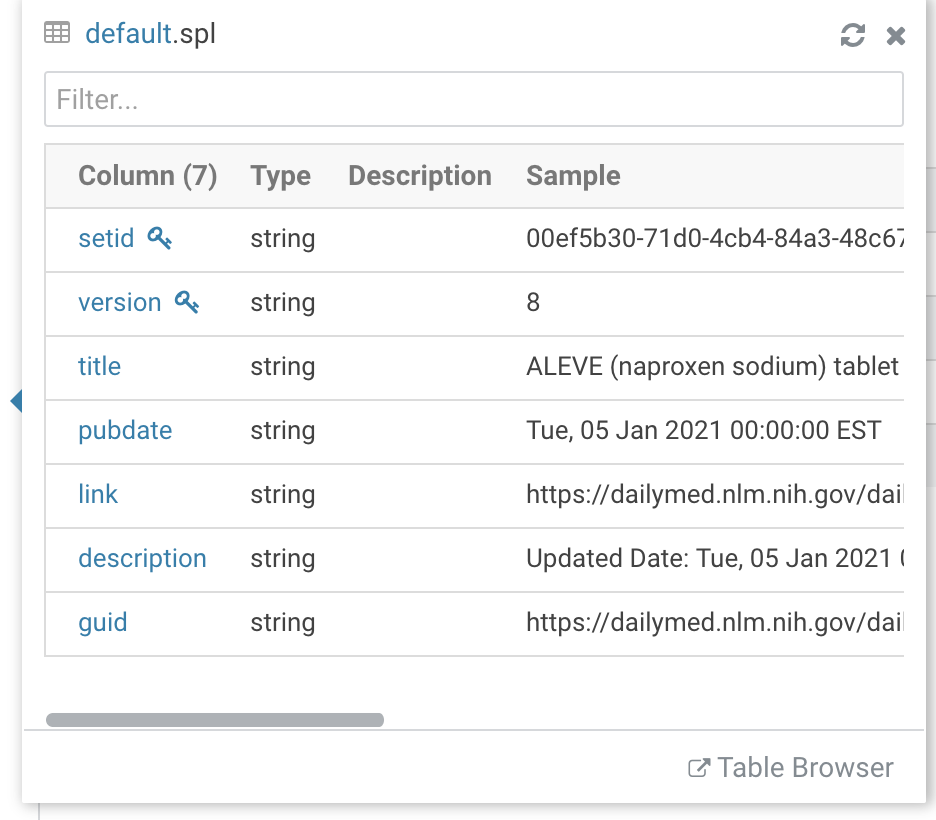
We use the LookupRecord to read from our cache.
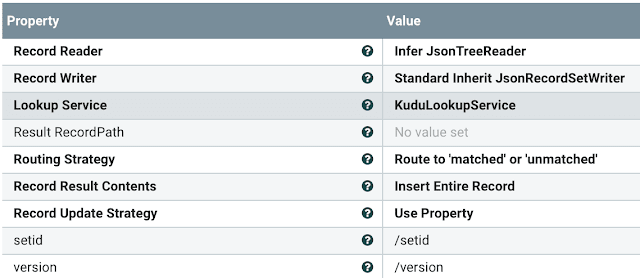
If we don't have that value yet, we send it to the table for an UPSERT.
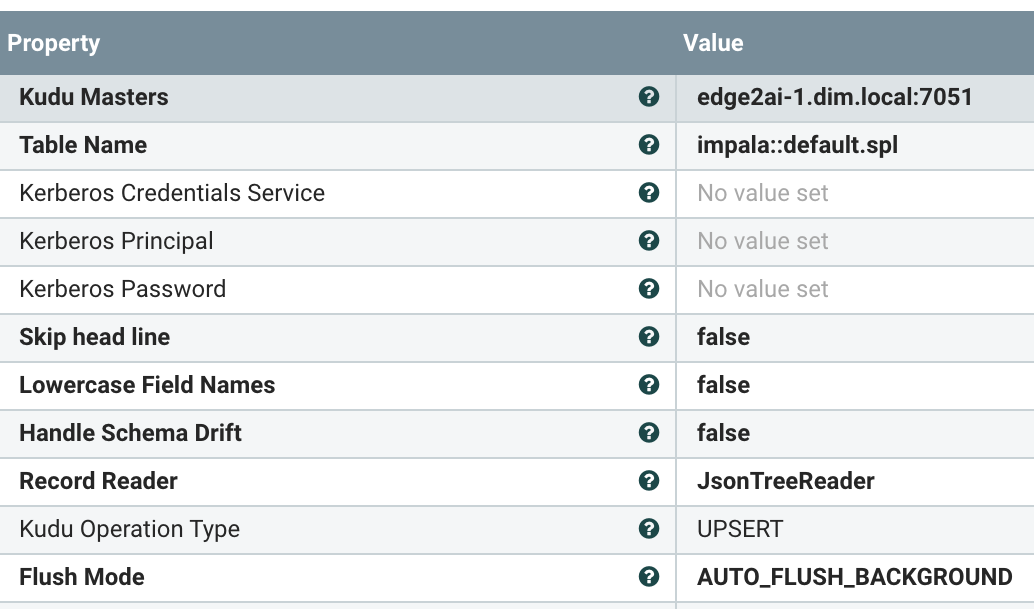
We send our raw data as XML/RSS to HDFS for archival use and audits.

We can see the results of our flow in Apache Atlas to see full governance of our solution.
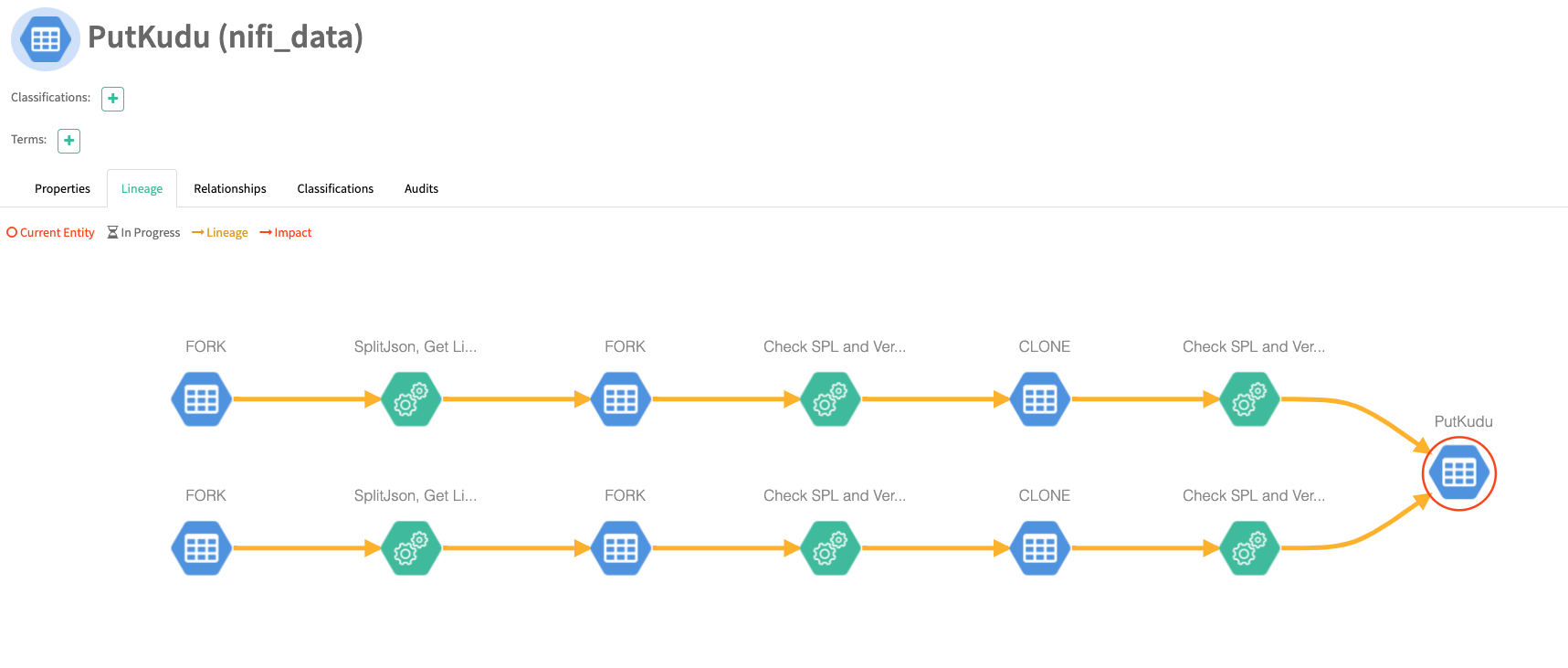
So with some simple NiFi flow, we can ingest all the new updates to DailyMed and not reprocess anything that we already have.


















