
Hello Readers,
After reading this article you will able to configure Hadoop Cluster using Ansible.
Before starting Let me tell you a little bit about Hadoop and Ansible.
What Is Hadoop?

Hadoop is an open-source, Java-based programming framework that supports the storage and processing of extremely large data sets in a distributed computing environment. It is part of the Apache project sponsored by the Apache Software Foundation.
Some Basic Terminology:
Namenode: Also called the master node is the main component of the Hadoop Cluster. It stores the metadata about block locations etc. This metadata is useful for file read and write operations.
Datanode: Also known as the Slave node, is someone who shares their own components with the master node. It is the final location for storing the files. There can be many data-nodes in one cluster.
What Is Ansible?

Ansible is open-source software that automates software provisioning, configuration management, and application deployment. To more about Ansible You can Read my other Article on “Ansible In Action”. I am providing its link below.
Link: https://dev.to/piyushbagani15/ansible-in-action-how-aws-is-solving-challenges-using-ansible-oll
Some Basic Terminology:
Controller Node: Machine where Ansible is installed.
Managed Node: The network devices (and/or servers) you manage with Ansible.
That’s All. Now Let’s stick to our main Objective.
The task that we are going to perform in this blog are:
🎇Configure Namenode (Master).
🎇Format the Namenode.
🎇Configure the Datanode (Slave).
🎇Check the connection between Datanode and Namenode.
Here I am going to launch 3 instances on AWS cloud. First will act as Controller Node, Second for Namenode and the last one is Datanode. Here Namenode and Datanode are acting as Managed Nodes.
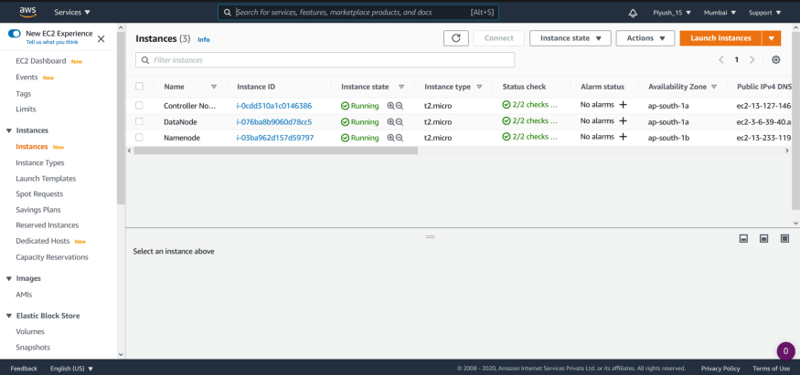
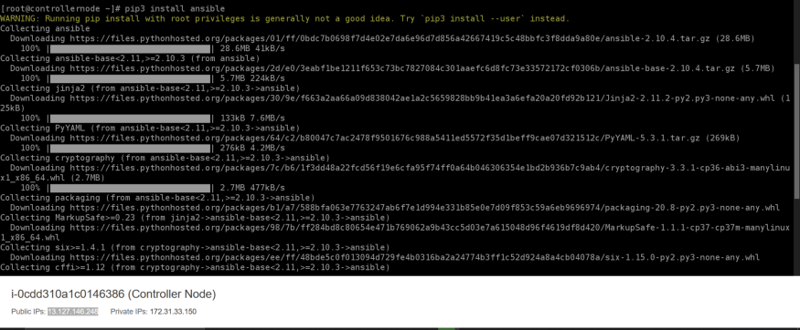
Firstly, In the controller node, We need to install Ansible. Before this Install Python using the yum install python3 Command.
Now We will setup the configuration file of Ansible by making a directory using mkdir /etc/ansible/ command. We need to write some code inside the configuration file of ansible.
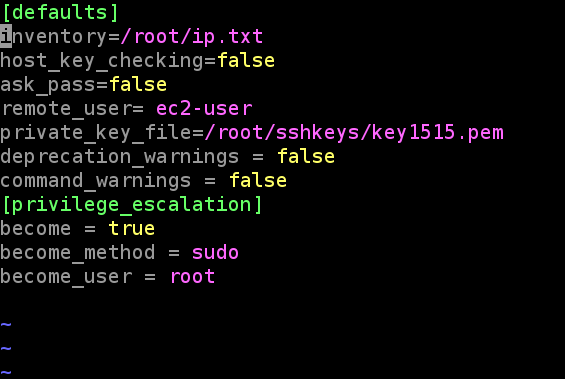
To avoid some warnings given by the command we have to disable it, using command_warnings=false
The remote user is that we are going to log in, here we have launched the ec2 instances hence the remote username is ec2-user
Also, we need to disable the ssh key, as when we do ssh it asks you for yes or no. We have to write host_key_checking=false to disable it.
Ansible uses existing privilege escalation systems to execute tasks with root privileges or with another user’s permissions. Because this feature allows you to ‘become’ another user, different from the user that logged into the machine (remote user), we call it to become. The become keyword leverages existing privilege escalation tools like sudo, su, pfexec, doas, pbrun, dzdo, ksu, runas, machinectl, and others.
To login in to that newly launched OS, we need to provide its respective key. Here .pem format will work. We need to give permission to that key in the read mode. Command for that:-
chmod 400 keyname.pem
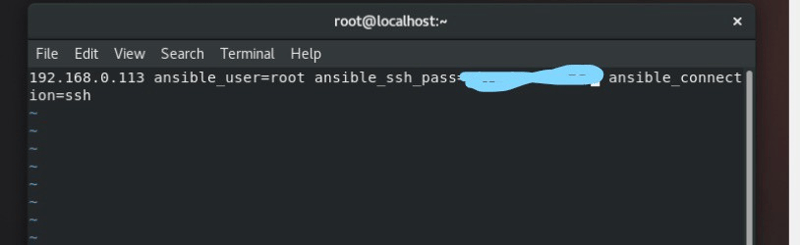
After setting up the configuration file, the next step is to create inventory. To create an Inventory create a text file and inside the text file provide managed node IP address, username, password, and connection type as shown.

Note: In this Inventory, we have given the .pem file for password as we are doing this practical/task on AWS cloud. If we want we can do it in Local VM(s). The changes we need to do are simple and as follows:
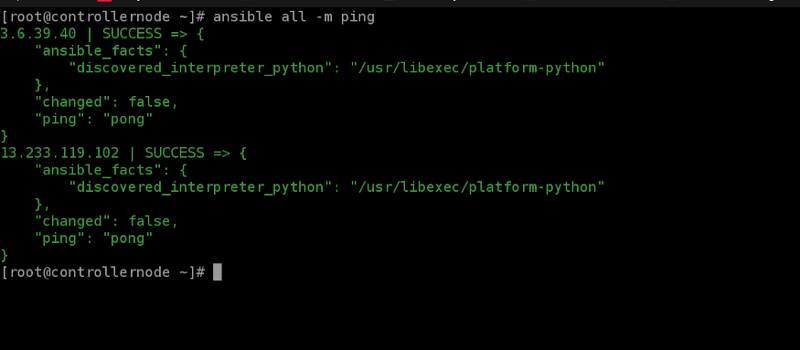
Now, check the connectivity with Managed Node using the command ansible all -m ping.
Now Start writing the playbook for configuring the Namenode. Also, It is good that we know how to setup a cluster manually as it provides the steps, and hence writing the playbook will be very much easy.
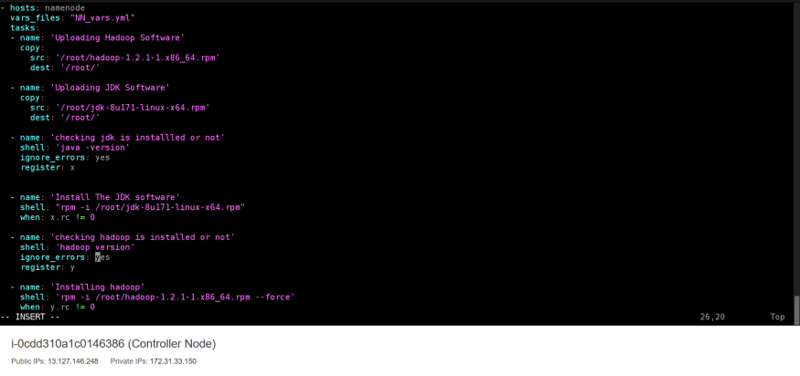

Now just the playbook using the command ansible-playbook namenode.yml If no error comes then you will see that Namenode is configured and the service is running perfectly.
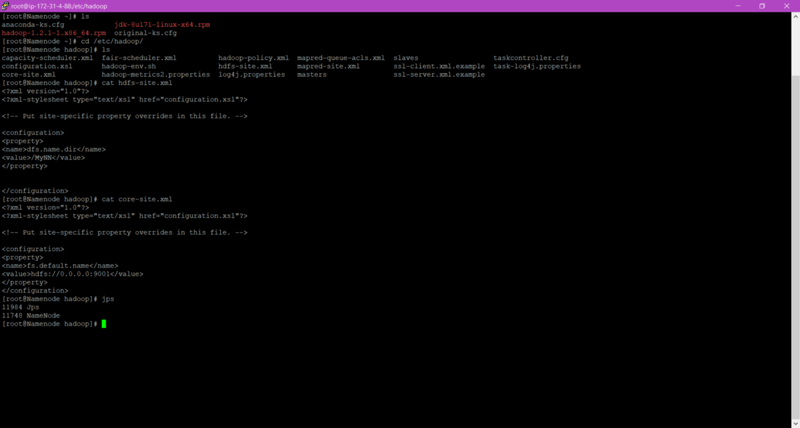
Here We can see all the tasks are performing great. Also, I have shown the content I wrote in the hdfs-site.xml and core-site.xml file as they are very much important.
Atlast by running the “ jps ” command manually we can also check the service is running or not.
Now let us write the playbook for Datanode. Again to the steps to configure it manually would be helpful. By chance I have attached the images which show how it executes afterward. Don’t worry about the code, I will provide my GitHub repo link at the end where you will find the entire code.
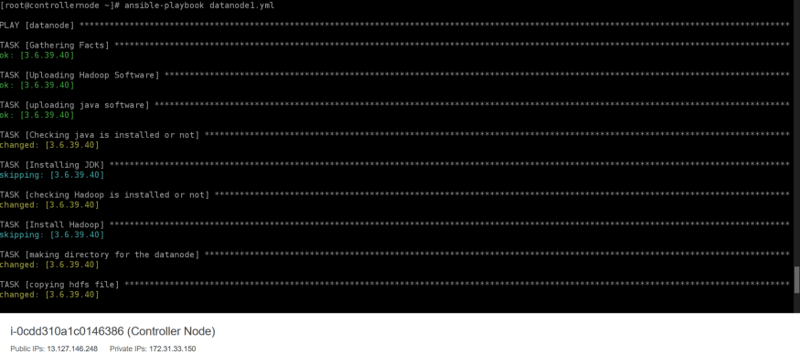
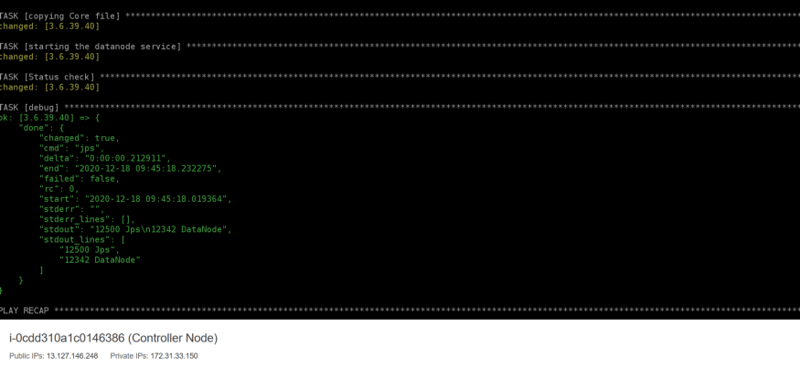
Hence, here the execution of the datanode1.yml completes and the final result can be seen in the below-attached image.
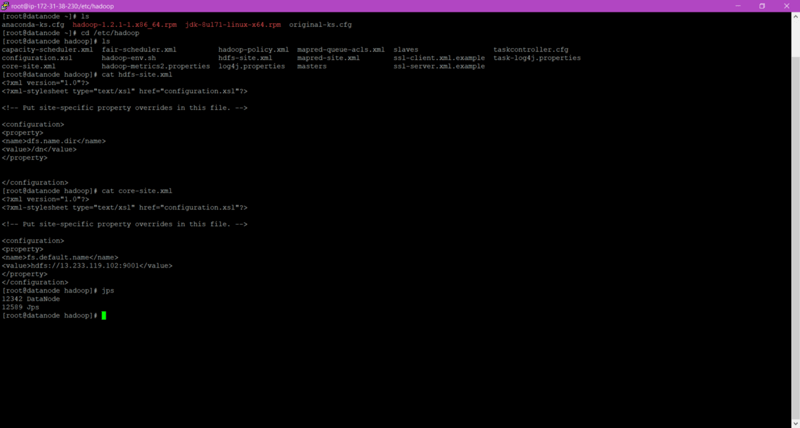
Finally, we have configured Namenode and Datanode using Ansible.
Let’s Check the report of the cluster we configured.

Here we can see that here Number of Datanodes is 1 and it is contributing its storage to the cluster.
We can Verify it from Hadoop WebUI.
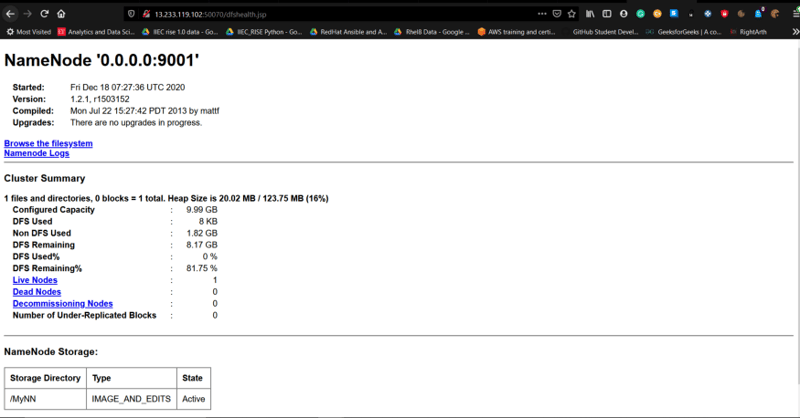
So that’s how we can set up the Hadoop cluster using Ansible.
Thank you!!!🎇🎇
Keep Learning, Keep Hustling🎇
GitHub Repo:https://github.com/PiyushBagani15/Ansible_Hadoop_Integration


















