
Hello All👋,
🎇After reading this article you will come to know how to contribute limited storage from data-node to Hadoop Cluster. I have done all the setup on AWS cloud so, No Need to worry about the resources such as RAM, CPU, etc.
So Without any further delay, Let’s Get Started.

🎇Our Primary Goals:
Launch a Name-node and a Data-node of AWS cloud
Create an EBS volume of 1 Gib and Attach it to Data-Node
Make sure to install Hadoop software and JDK software in both the nodes.
Create Partition(s) in attached volume.
Format it and finally mount it on the Data-node Directory
Setup the Name-node and Data-node
Contribute Limited Storage from Data-node to Hadoop Cluster.
🎇I hereby assume that you have some basic knowledge about Hadoop cluster and Cloud Computing.
🎇First of I have launched 2 instances with RedHat Linux Image of Amazon with 10Gib EBS Storage in North Virginia region.
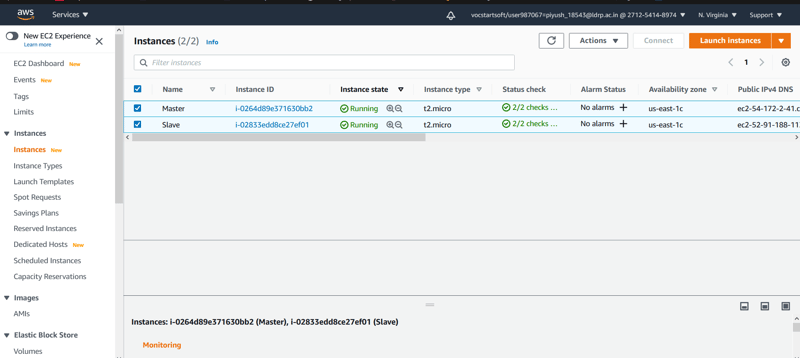
🎇After the instances are launched to do remote login I used PuTTY software.
🎇Now after this we will create EBS volume of 1GiB by clicking on Volumes in AWS Console. I named it slave-volume. Notice here the 2 volumes of 10GiB are Root Volumes.
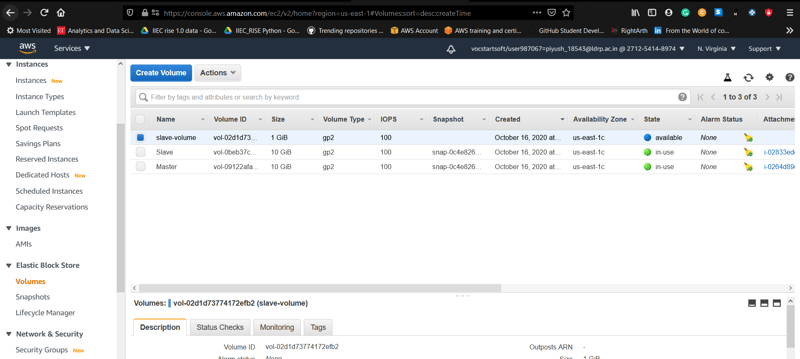
🎇Now, We will attach our slave-volume to our datanode instance running. It is just like we insert pendrive in our local system or we create a virtual harddisk and attach to it. Mainly we have to give the instance id only while attaching.
🎇Attaching the volume is so simple, we just need to select that volume first, click on Actions Button and after that we have to provide instance id.
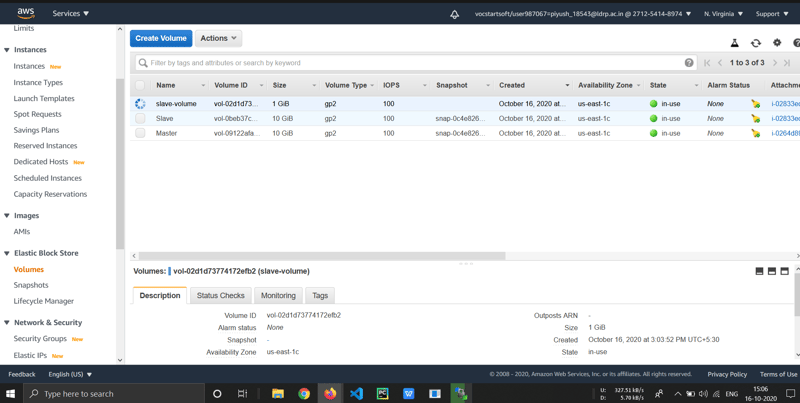
🎇After attaching volume to data-node we can see that volume is in in-use status.
🎇As we remotely logged in data-node instance previously, now we can see similar linux terminal and to confirm that EBS volume we created or not we can use fdisk -l command.
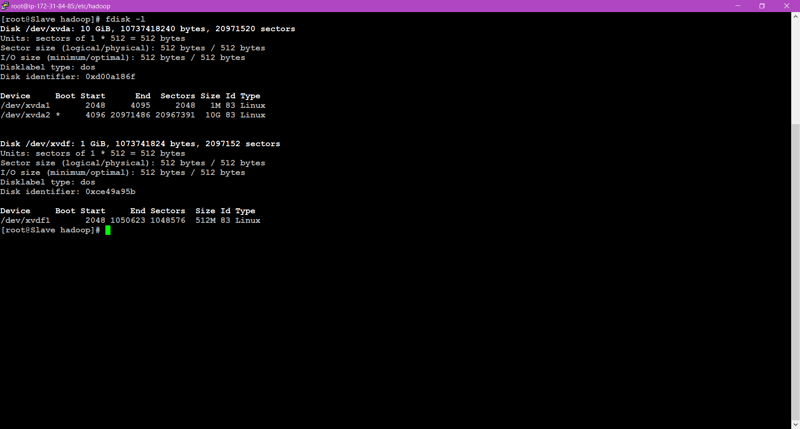
🎇Now the main concept of Partitions come into play. To share limited storage we are going to create partition in that 1GiB volume attached. Here we created partition of 512M(512 MiB). Here We can see the device /dev/xvdf1 created.
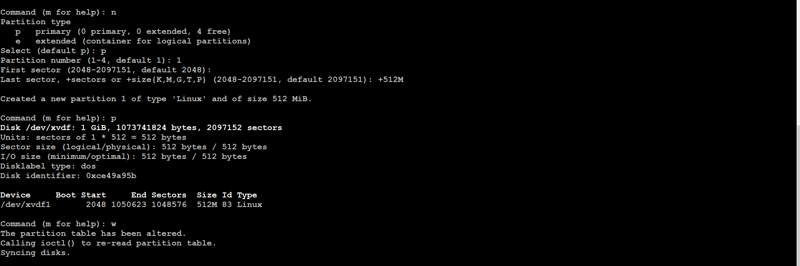
🎇Now we know we share the storage of Data-node to Name-Node to solve problem of storage we have in BigData. So, For storing any data in this partition, we have to first Format it.
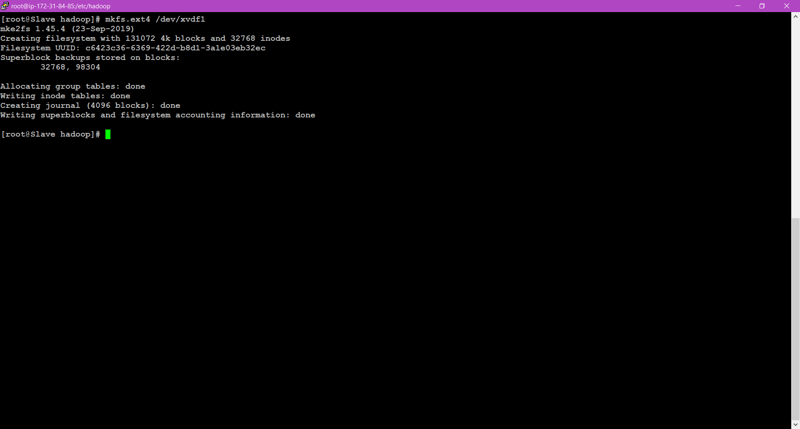
🎇To format that partition we created we need to run a command.
mkfs.ext4 /dev/xvdf1
🎇Now, We have to mount it on the same directory of data-node we will be using in Hadoop Cluster.
🎇To mount the partition on desired directory, we have to run the following command:
mount /dev/xvdf1 /dn2

🎇After mounting we can confirm or see the size using df -hT command.
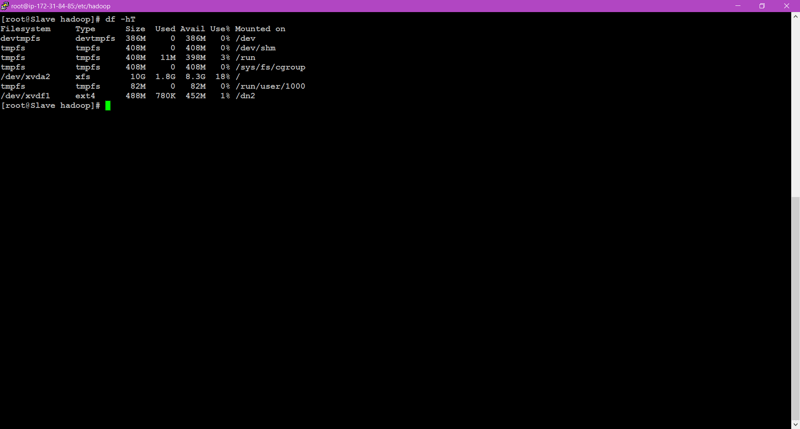
🎇Here all the steps of partitioning and mounting are completed.
🎇Now we have to configure the hdfs-site.xml file and core-site.xml file in Name-node and Data-node.
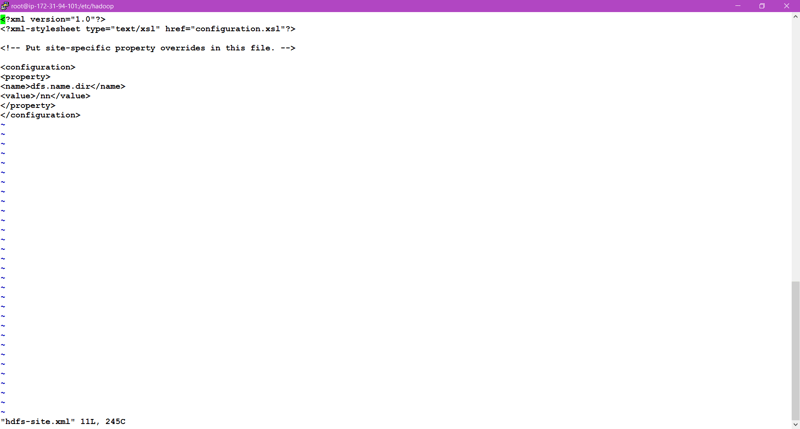
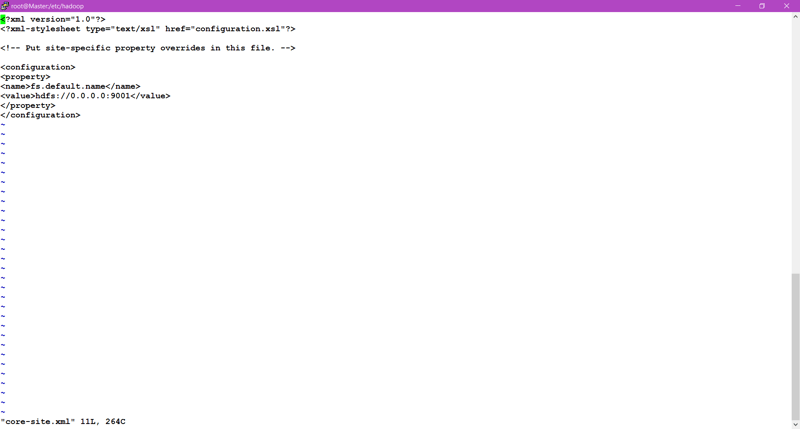
🎇Remember, In Namenode we have we have to format /nn directory we created and After that start the service of NameNode using hadoop-daemon.sh start namenode.
🎇Now we have to also configure the same files in Datanode also in the similar way, just remember to give IP of Name-node in core-site.xml file.
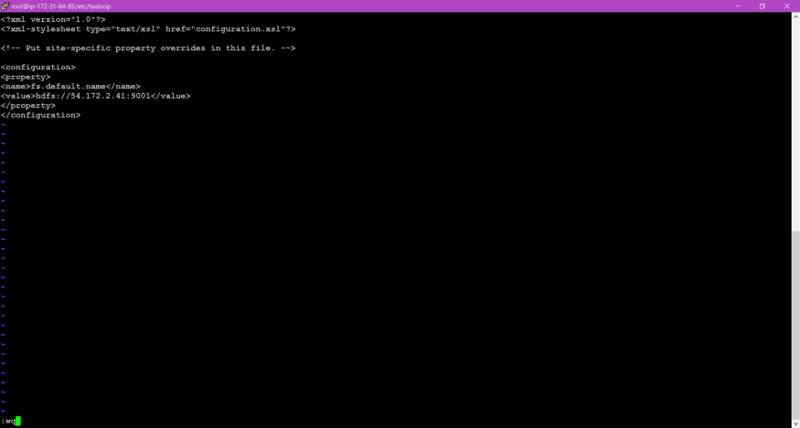
🎇Atlast, start the service of datanode also.
🎇Finally, Our all configurations are completed here.
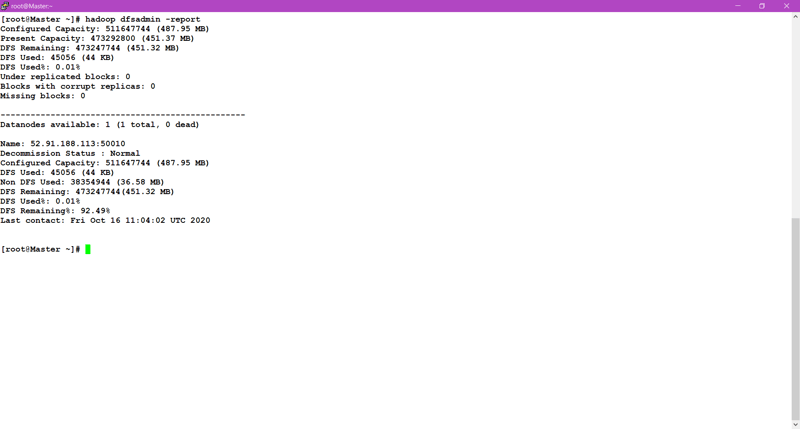
🎇Now by command hadoop dfsadmin -report ,We can see the status of hadoop cluster. This Command can be run from any of the node.
🎇Finally,we have set the limitation to data-node storage size.
Atlast, I want to say that I know if you are beginner, You find the concept of partitions a little bit tricky. So For That I am providing some links of Video lectures; You can go through it and explore more.
Thanks For Reading………………
🎇Video lectures:-


















