
Skąd wiesz, gdzie powinny być przechowywane Twoje dane? I co równie ważne, co się stanie, gdy węzeł pamięci masowej ulegnie awarii lub dodasz nowy węzeł pamięci masowej w celu skalowania systemu? Hash jest powszechnym i skutecznym sposobem określania, gdzie dane powinny być przechowywane w tym scenariuszu i jest szczególnie ważne, aby zrozumieć, jeśli wdrażasz jakąkolwiek aplikację do strumieniowego przesyłania danych.
Czym jest haszowanie?
Hashing wykorzystuje "tablice haszujące" i "funkcje haszujące" lub algorytmy do konwersji danych o zmiennym rozmiarze, takich jak plik lub dowolny ciąg znaków, na spójny wynik o stałym rozmiarze.
Funkcja haszująca (lub spójny algorytm haszujący) to operacja matematyczna, która pobiera dane i wyprowadza liczbę reprezentującą te dane, której wartość jest znacznie mniejsza niż oryginalny rozmiar dostarczonych danych. Liczba wyprowadzana przez funkcję haszującą nazywana jest "haszem", a jej wartość będzie spójna za każdym razem, gdy funkcja haszująca zostanie wywołana z tymi samymi danymi. Następnie można wyszukać dane w tablicy haszującej
Dla BARDZO prostego przykładu, rozważmy operator modulo (%) jako funkcję skrótu. Niezależnie od rozmiaru liczby dostarczonej do operatora modulo, zwróci on spójną liczbę w określonym zakresie n, dla [danych] mod n:
69855 MOD 10 = 5
63 MOD 10 = 3
916 MOD 10 = 6
26666 MOD 10 = 6
Ostatni przykład ilustruje "kolizję", w której różne dane wejściowe dają tę samą wartość skrótu, 6. Można również zobaczyć, jak można zmienić zakres wyjściowy, dostosowując funkcję skrótu, np. x MOD 20 lub x MOD 30.
W rzeczywistych implementacjach hashowania, bardziej złożone funkcje hashujące są używane do obsługi kolizji i najbardziej efektywnego wykorzystania pamięci, w zależności od oczekiwanych danych wejściowych.
Dlaczego warto używać haszowania?
Powszechnym przykładem hashowania jest przechowywanie i pobieranie danych. Załóżmy, że masz kolekcję 15 miliardów elementów i musisz pobrać określony element; jak byś to zrobił? Jednym ze sposobów mechanizmu byłoby iterowanie po zbiorze danych, ale jest to nieefektywne, ponieważ liczba kluczy w magazynie klucz-wartość rośnie; lepiej jest użyć skrótu.
Działałoby to w następujący sposób:
Przechowując elementy danych, najpierw przeprowadź klucz powiązany z danymi przez funkcję skrótu. Na podstawie wynikowego skrótu przechowuj dane w tabeli skrótu w zaszyfrowanej lokalizacji. W przypadku kolizji będziesz musiał podjąć kroki, aby upewnić się, że żadne dane nie zostaną utracone; na przykład tabela skrótu może przechowywać połączoną listę danych zamiast samych danych (tzw. haszowanie łańcuchowe) lub funkcja skrótu może kontynuować wyszukiwanie pustego gniazda, dopóki nie zostanie znalezione (techniki obejmują sondowanie lub podwójne haszowanie).
Podczas pobierania elementów danych należy ponownie uruchomić klucz powiązany z danymi za pomocą funkcji skrótu, a następnie wyszukać wynikowy kod skrótu w tabeli skrótu.
Jeśli mam już klucz do moich danych, dlaczego nie mogę po prostu użyć tego klucza bezpośrednio do przechowywania moich danych? Np. jako indeks do tablicy . Możesz (jest to odpowiednik użycia funkcji skrótu, która nic nie robi), ale jest to bardzo nieefektywne. Co jeśli twoje klucze są bardzo duże i nie są ciągłe?
Hashowanie w systemie rozproszonym
W poprzednim przykładzie omówiono użycie tabeli skrótów do przechowywania i pobierania dużej listy elementów danych, ale co, jeśli ta lista jest fizycznie rozproszona na wielu serwerach?
W systemie rozproszonym można użyć funkcji skrótu do określenia, gdzie dane powinny być przechowywane. Zamiast funkcji skrótu wskazującej lokalizację w tabeli skrótu, jak w poprzednim przykładzie, system rozproszony może użyć innej funkcji skrótu, której wynikiem jest identyfikator serwera, który można zmapować na adres IP.
Na przykład: Przechowując dane w systemie rozproszonym, najpierw skróć klucz powiązany z danymi, aby uzyskać identyfikator serwera, na którym dane powinny być przechowywane, a następnie zapisz dane na tym serwerze. Jeśli wybrałeś funkcję skrótu, której dane wyjściowe są równomiernie rozłożone na wszystkie dostępne serwery, żaden z serwerów nie będzie przeciążony, a dane można szybko odzyskać. Można również rozważyć równoważenie obciążenia w podobny sposób, w którym liczba serwerów wzrasta, aby zrównoważyć obciążenie serwera.
Załóżmy, że masz listę 5 serwerów, które mogą przechowywać Twoje dane i przypisałeś każdemu z nich unikalną tożsamość, od 1 do 5. W tym przykładzie decydujesz, na którym serwerze przechowywać dane na podstawie skrótu klucza tych danych:
Utwórz kod skrótu reprezentujący klucz przechowywanych danych; wynikowy kod skrótu powinien mieścić się w zakresie od 1 do 5 (ponieważ mamy 5 serwerów).
Wcześniejszy przykład używał bardzo prostego modulo dla funkcji skrótu; odpowiednikiem tutaj byłoby myślenie o naszej funkcji skrótu jako "
[klucz] MOD 5".Przechowujemy plik na serwerze, którego ID zostało obliczone.
To zadziała, ale co się stanie, gdy serwer przestanie działać? Co się stanie, gdy zostanie dodany nowy serwer? W obu przypadkach wszystkie dane muszą zostać ponownie obliczone i przeniesione na podstawie wyniku nowego skrótu - znanego jako rehashing, jest to nieefektywne i dlatego powyższe podejście jest zbyt uproszczone, aby można je było stosować w produkcji.
Czym jest spójne haszowanie?
Spójne haszowanie określa, gdzie dane powinny być przechowywane w systemie rozproszonym, jednocześnie tolerując dodawanie lub usuwanie serwerów, minimalizując ilość danych, które muszą być przenoszone lub ponownie haszowane w przypadku zmian w infrastrukturze.
Różnica między spójnym haszowaniem a haszowaniem
Hashowanie to ogólna technika pobierania pewnej zmiennej ilości danych i zmniejszania jej tak, aby była przechowywana w spójnej strukturze pamięci masowej o stałym rozmiarze, znanej jako tabela hash, w celu szybkiego i wydajnego wyszukiwania. Rozmiar wybranej tabeli hash będzie zależeć od ilości przechowywanych danych i innych bardziej praktycznych względów, takich jak dostępna pamięć systemowa. Po zmianie rozmiaru tabeli hash zazwyczaj zmienia się również funkcja hash, aby zapewnić równomierne rozłożenie danych w nowo zmienionej tabeli, co oznacza, że wszystkie dane muszą zostać ponownie zhashowane i przeniesione.
Spójne haszowanie jest specjalnym rodzajem haszowania, w którym po zmianie rozmiaru tabeli haszującej tylko niewielka część danych musi zostać przeniesiona. W szczególności liczba elementów danych, które należy przenieść, wynosi n/m, gdzie n to liczba elementów danych, a m to liczba wierszy w tabeli haszującej (lub serwerach, w naszym wcześniejszym przykładzie systemu rozproszonego).
Jak działa spójne haszowanie?
W przypadku spójnego haszowania wyobraź sobie serwery (lub dowolny wirtualny węzeł) przechowujące dane ułożone w okrąg i ponumerowane zgodnie z ruchem wskazówek zegara. Aby uczynić rzeczy bardziej intuicyjnymi, większość ilustracji będzie numerować węzły od 1 do 360 (stopni), ale rzeczywiste wybrane liczby i to, czy są one ciągłe, czy nie, są nieistotne; liczy się to, że przypisane identyfikatory serwerów rosną, gdy śledzisz trasę wokół okręgu w kierunku zgodnym z ruchem wskazówek zegara od jednego serwera do drugiego. Identyfikator następnego węzła będzie zawsze większy niż poprzedniego, aż do zawinięcia.
Podczas określania, na którym serwerze dane powinny być przechowywane, obliczany jest skrót danych, a następnie moduł tego skrótu jest brany z 360; wynikowa liczba prawdopodobnie nie będzie dokładnie pokrywać się z prawidłowym numerem serwera, więc wybierany jest identyfikator serwera, który jest najbliższy i większy niż wynikowa liczba. Jeśli nie ma serwera, którego identyfikator jest większy niż wynikowa liczba, należy zawinąć z powrotem do 0 i kontynuować wyszukiwanie identyfikatora serwera.
Jako przykład:
Istnieje pewien klucz danych, do którego zastosowano funkcję skrótu, której wynikiem jest 5562.
5562 MOD 360 to 162
Znajdujemy serwer w naszym wdrożeniu, którego identyfikator jest większy niż 162, np. identyfikator 175 na poniższym diagramie.

Co jeśli nie mam 360 serwerów? Lub więcej niż 360 serwerów? Liczby nie są ważne, tylko zasada. Tak długo, jak wybrane identyfikatory serwerów są ponumerowane w porządku rosnącym, w miarę równomiernie rozmieszczone i koncepcyjnie ułożone w pierścień (znany jako pierścień haszujący).
Dlaczego warto używać spójnego hashowania?
Ponieważ nasze dane są rozproszone na wielu węzłach (lub serwerach), dodawanie lub usuwanie węzła z naszego systemu staje się znacznie bardziej wydajne. Rozważmy przykład, w którym mamy 3 węzły, A, B i C, o identyfikatorach 90, 180 i 270. Każdy węzeł w naszej konfiguracji zawiera jedną trzecią danych.
Jeśli chcemy dodać nowy węzeł, D, przypisujemy mu nowy identyfikator, powiedzmy 360.
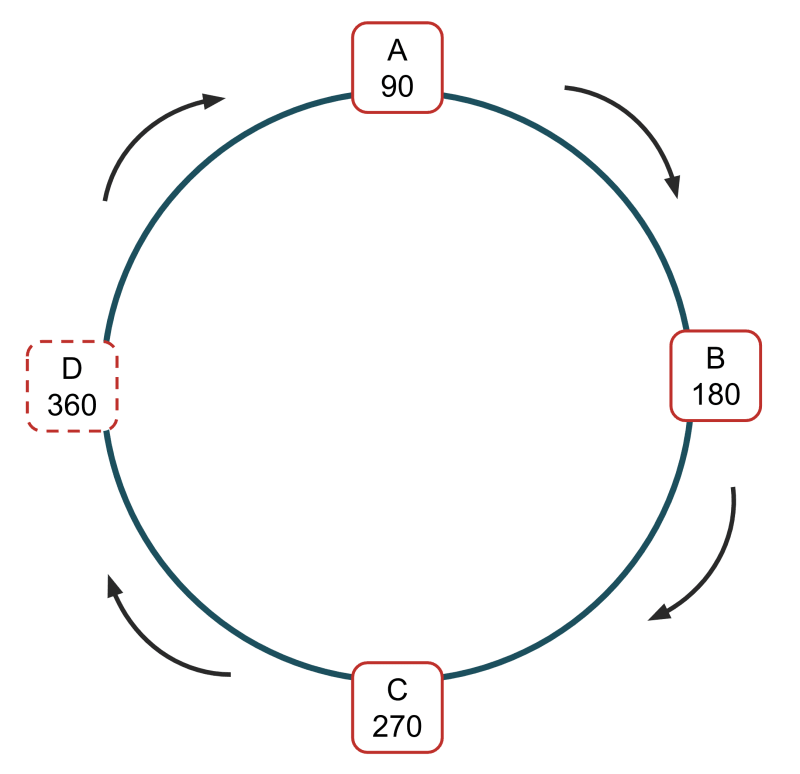
Mamy teraz wybór, czy pozostawić D puste i pozwolić na jego powolne zapełnianie w miarę przechowywania danych, czy też redystrybuować dane z innych węzłów do D. To, którego wyboru dokonamy, zależy od implementowanego rozwiązania; implementacje buforowania stron internetowych i serwerów pamięci podręcznej zrobią to pierwsze i pozwolą, aby pominięcia pamięci podręcznej powoli zapełniały D. Inne rozwiązania wezmą połowę danych z A i przeniosą je do D (bez zbytniego zagłębiania się w matematykę, przenoszone dane muszą mieć hash, którego wartość spowodowałaby, że zostałyby zapisane w D, gdyby były to nowe dane).
Czym jest spójna usługa nazewnictwa oparta na hashowaniu?
Poprzednie przykłady w tym poście dotyczyły przechowywania danych lub plików na serwerach, ale zasadę tę można rozszerzyć na przechowywanie dowolnych danych w sposób rozproszony. Usługi nazewnicze są jednymi z największych i najbardziej rozproszonych systemów i dobrze nadają się do implementacji za pomocą spójnego haszowania. Pomijając na razie DNS, który ma specyficzną i inną implementację, moglibyśmy zaimplementować bardziej ogólną usługę nazewniczą przy użyciu spójnego haszowania w następujący sposób:
Rekordy nazw są przechowywane na wielu serwerach.
Serwery powinny mieć przypisany identyfikator i być ułożone w porządku rosnącym w koncepcyjnym pierścieniu.
Aby rozwiązać nazwę, musimy zlokalizować serwer, na którym przechowywany jest rekord nazwy.
Należy wykonać hash nazwy, a następnie wziąć moduł wyniku z 360 (zakładając, że mamy mniej niż 360 serwerów).
Znajdź identyfikator serwera, którego nazwa jest najbliższa, ale większa niż wynik znaleziony w poprzednim kroku. Jeśli taki serwer nie istnieje, przejdź do pierwszego serwera w pierścieniu z najniższym identyfikatorem.
Rekord nazwy zostanie znaleziony na zidentyfikowanym serwerze.
Można również rozważyć sieci dostarczania treści, które działają w podobny sposób, równoważąc żądania w różnych węzłach, aby uniknąć gorących punktów
Spójna implementacja haszowania
Na Githubie dostępnych jest wiele istniejących implementacji, od Java po Python, w których wiele węzłów jest ułożonych w spójny pierścień haszujący zawierający rozproszoną tabelę haszującą.
Istnieją produkcyjne systemy pamięci masowej, które wykorzystują spójne haszowanie, takie jak Redis, Akamai lub dynamo Amazon, z których wiele wykorzystuje bardziej złożone struktury danych, takie jak memcache, wyszukiwanie binarne lub losowe drzewa do ostatniego etapu wyszukiwania danych.
Kroki do wdrożenia spójnego haszowania
Po wyjaśnieniu podstawowej techniki można rozpocząć wdrażanie spójnego rozwiązania haszującego, ale należy wziąć pod uwagę następujące kwestie:
Ile serwerów będziesz mieć w swoim rozwiązaniu? Czy spodziewasz się, że liczba ta wzrośnie?
W jaki sposób zostaną przypisane identyfikatory serwerów?
Jakiej funkcji haszującej użyjesz do utworzenia skrótu danych? Będziesz chciał wybrać funkcję, która generuje jednolite dane wyjściowe, aby dane nie były grupowane na jednym serwerze i były równomiernie rozłożone na wszystkich serwerach.
Zastanów się, co się stanie, gdy dodasz lub usuniesz serwer z rozwiązania. Powinieneś starać się zachować identyfikatory serwerów tak równomiernie, jak to możliwe, aby uniknąć grupowania danych.
Przykład implementacji spójnego haszowania
Rozważmy przykład, w którym pliki są przechowywane na jednym z 5 serwerów. Przydzielimy identyfikatory serwerów od 1 do 360.
Serwery są ułożone w koncepcyjny pierścień i przypisano im identyfikatory 74, 139, 220, 310 i 340
Musimy zapisać nowy plik, haszujemy klucz tego pliku, a wynikiem jest 1551
Wykonujemy 1551 MOD 360, co daje nam 111
Plik danych będzie zatem przechowywany na serwerze z identyfikatorem 139.

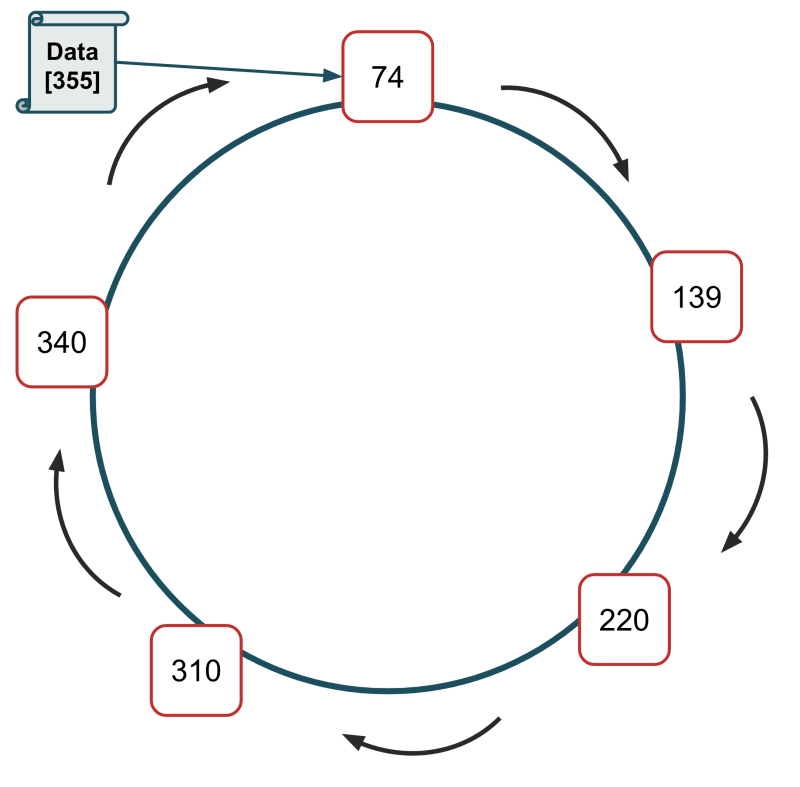
Rozważmy inny przykład:
Serwery są ułożone w koncepcyjny pierścień i przypisano im identyfikatory 74, 139, 220, 310 i 340.
Musimy zapisać nowy plik, haszujemy klucz tego pliku, a wynikiem jest 1075.
Wykonujemy 1075 MOD 360, co daje nam 355
Żaden identyfikator serwera nie przekracza 355; dlatego plik danych będzie przechowywany na serwerze o identyfikatorze 74.
Spójna optymalizacja haszowania
Jeśli węzeł (serwer) ulegnie awarii w systemie wykorzystującym spójne haszowanie, z założenia wszystkie dane zostaną ponownie przypisane do następnego serwera w pierścieniu. Oznacza to, że uszkodzony serwer podwoi obciążenie następnego serwera, co w najlepszym przypadku spowoduje marnowanie zasobów na przeciążonym serwerze, a w najgorszym może spowodować awarię kaskadową.Bardziej równomierną redystrybucję w przypadku awarii serwera można osiągnąć, zlecając każdemu serwerowi hashowanie do wielu lokalizacji lub replik w pierścieniu. Na przykład serwer ma 4 możliwe hashe i dlatego istnieje w 4 miejscach w pierścieniu, a teraz, gdy ten serwer ulegnie awarii, dane przechowywane na tym serwerze są redystrybuowane do 4 różnych miejsc, więc obciążenie żadnego innego serwera nie przekracza dodatkowej jednej czwartej, co jest łatwiejsze w zarządzaniu.
Spójna implementacja hashowania z PubNub
PubNub to platforma API dla deweloperów, która umożliwia aplikacjom dostarczanie wiadomości na masową, globalną skalę. PubNub ma wiele punktów obecności, dzięki czemu może bezpiecznie, niezawodnie i szybko dostarczać wiadomości.
Aby zapewnić skalę i niezawodność, których oczekują nasi klienci, używamy kilku technik na naszym zapleczu, w tym spójnego haszowania.
Jeśli tworzysz*aplikację, która musi wymieniać dane między klientami* lub między klientem a serwerem na dużą skalę, prawdopodobnie masz o wiele więcej do przemyślenia niż tylko to, jakiego mechanizmu haszowania użyć. Pozwól PubNub obsłużyć wszystkie Twoje potrzeby komunikacyjne, abyś mógł skupić się na logice biznesowej i nie martwić się o niskopoziomową transmisję danych Twojej aplikacji w miarę jej skalowania.
Jeśli zastanawiasz się nad przetwarzaniem brzegowym, sprawdź nasze rozwiązanie magistrali komunikatów brzegowych lub dowiedz się, jak PubNub może obsługiwać komunikację i rozwiązania blockchain web3.
PubNub można wypróbować za darmo, wystarczy się zalogować lub zarejestrować bezpłatne konto, aby utworzyć aplikację lub skorzystać z naszej wycieczki, aby zobaczyć, na czym polega PubNub.


















