
Consider an organization that receives emails from clients, and they’d like to analyze those emails to extract certain data to gain insight. Email clients only go so far as to help with organization and analysis. Manually analyzing huge volumes of email data just to extract the relevant details is tedious and time-consuming. This task needs to be automated through code, but dealing with HTML-based files can have its own set of concerns. ComponentOne TextParser proves to be efficient in extracting the right amount of data from structured sources like HTML emails.
This blog will focus on using C1TextParser to automate the process of extracting invoice totals from HTML-structured files. We will be creating an HTML extractor that extracts details like invoice total, order number, shipping charges, and address of the customer from the invoices that have a similar repeated structure.
To develop an application for the same, we need to follow these steps:
- Create a new WPF application
- Install the required NuGet packages to your app
- Creating an HTML extractor
- Extract the required details and parse them in JSON format
- Deserializing the extracted JSON result
- Using ComponentOne’s WPF FlexGrid to display the extracted data
Create a New WPF Application
1. Open Visual Studio. Select ‘Create a new project’.
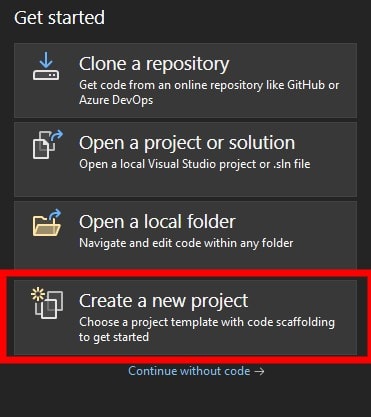
2. Enter ‘wpf app’ in the search bar and select WPF App (.NET Framework) in the ‘Create a new project' dialog box. Click Next.

3. Add project configurations like project name, project location, and framework in the Configure your new project dialog box.
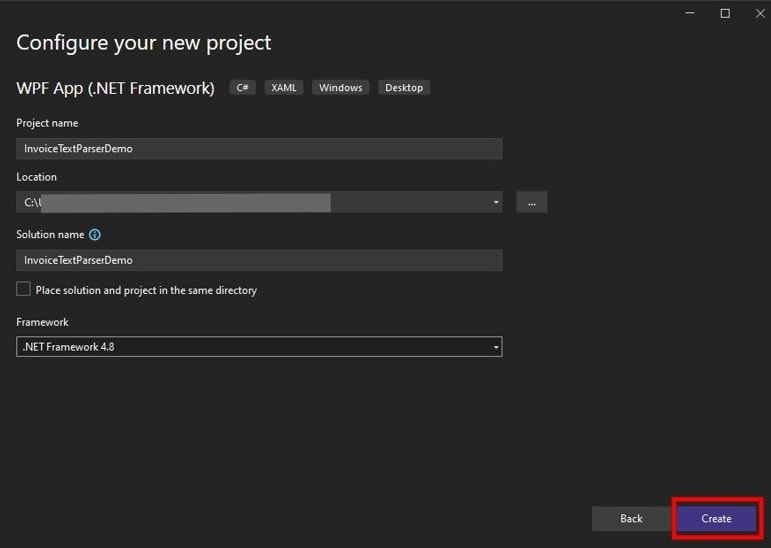
Installing the Required Nuget Packages to Your App
1. In the Solution Explorer(Ctrl+Alt+L), right-click on the project and select Manage NuGet Packages.

2. Search for C1.TextParser under the Browse tab and install the latest version.

Completing the above steps will add the C1TextParser library to your project.
Creating an HTML Extractor
In this step, we will be creating an HTML extractor using our email invoice template.
To begin with, we will use one of the invoice emails as a template file that will contain the placeholders for the text to be extracted.
Placeholders define the XPath of the text places which are to be extracted from the source files. XPath is a path expression used to navigate the elements in an XML/HTML code.
Define the template stream by opening the template file’s HTML content and passing it to an HTML extractor.
_receiptTemplateStream = File.Open(ParserStringResource.TemplateFilePath, FileMode.Open);
_htmlExtractor = new HtmlExtractor(_receiptTemplateStream);
Now, add the placeholders to the HTML extractor.
// function to add place holders to HTML Extractor
public void AddPlaceHoldersToExtractor()
{
_htmlExtractor.AddPlaceHolder("TotalAmount", _invoiceExtractorConfiguration.TotalAmtSamplePath, 1, 5);
_htmlExtractor.AddPlaceHolder("ShippingCharges", _invoiceExtractorConfiguration.ShipAmtSamplePath, 1, 4);
_htmlExtractor.AddPlaceHolder("AddressLine1", _invoiceExtractorConfiguration.AddressLine1SamplePath);
_htmlExtractor.AddPlaceHolder("AddressLine2", _invoiceExtractorConfiguration.AddressLine2SamplePath);
_htmlExtractor.AddPlaceHolder("AddressLine3", _invoiceExtractorConfiguration.AddressLine3SamplePath);
_htmlExtractor.AddPlaceHolder("OrderNo", _invoiceExtractorConfiguration.OrderNumSamplePath);
}
How to get the XPath using Chrome browser?
To get the XPath, we will need to inspect the HTML source code of the template file and locate the element containing the text to be extracted.
The following GIF demonstrates how to obtain XPath when you open an HTML file with Chrome.
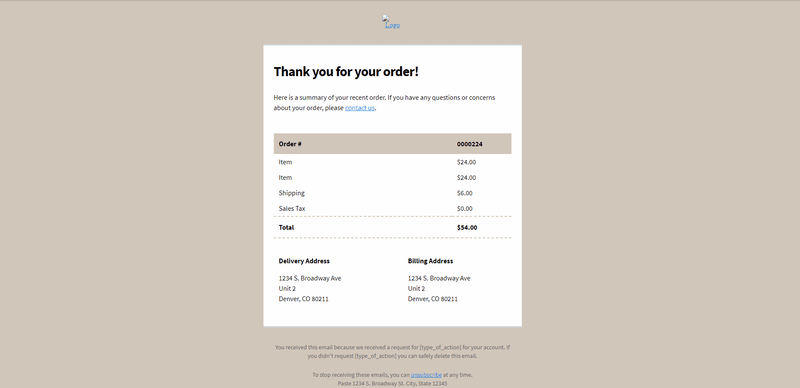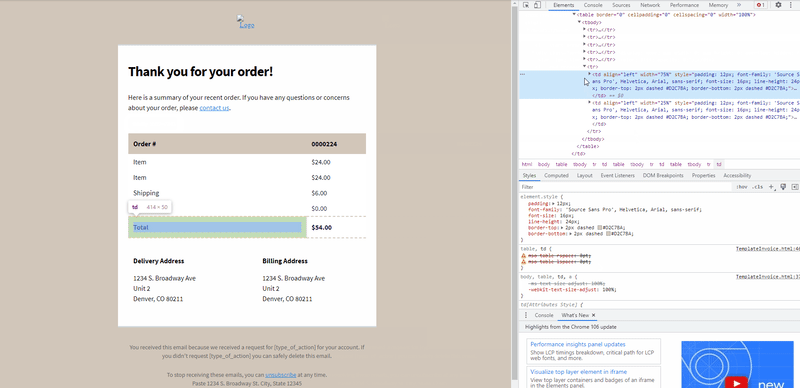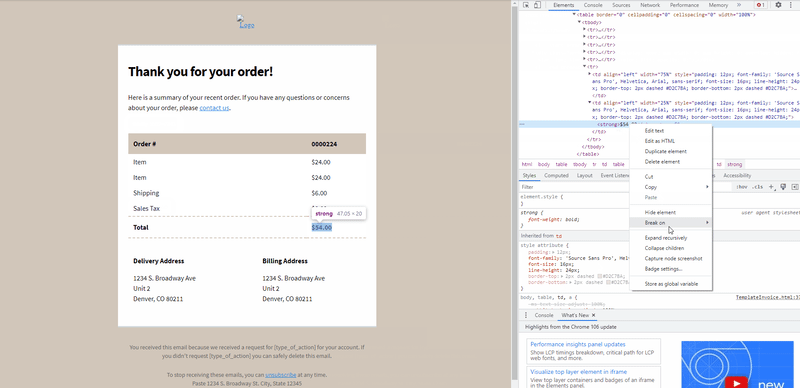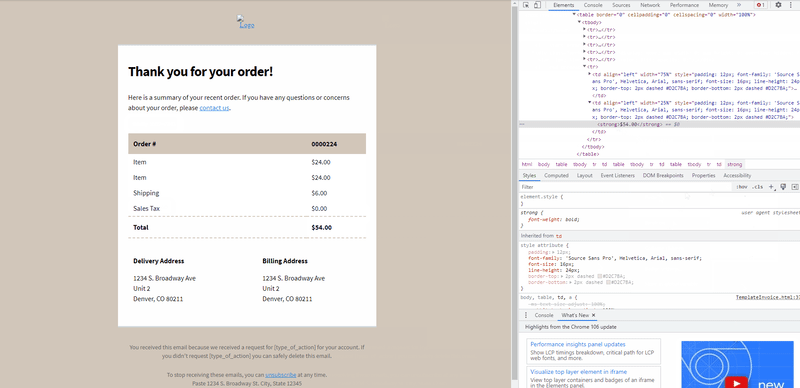
Extract the Details and Parse the Results in JSON Format
Now, we will be extracting the required details using the HTML extractor created in the previous step. HTMLExtractor’s Extract() method extracts the text from the input stream based on the placeholders already defined. Creating a JSON string based on the extracted results will allow it to be further deserialized in an object.
string _extractedResults = _htmlExtractor.Extract(_sourceTemplateStream).ToJsonString();
Deserializing the Extracted JSON Result
To deserialize the JSON string, we need a class that has properties matching JSON properties (keys).
We will be creating a class named ‘InvoiceData’ for our sample application as follows:
public class InvoiceData
{
public string OrderNo { get; set; }
public double TotalAmount { get; set; }
public double ShippingCharges { get; set; }
public string CompleteAddress {
get {
return AddressLine1 + ", " + AddressLine2 + ", " + AddressLine3;
}
}
public string AddressLine1 { get; set; }
public string AddressLine2 { get; set; }
public string AddressLine3 { get; set; }
}
Add the object obtained from the deserialized JSON string to the collection of type InvoiceData.
_invoices.Add(JsonConvert.DeserializeObject<InvoiceData> ((JObject.Parse(_extractedResults))["Result"].ToString()));
Using ComponentOne’s WPF FlexGrid to Display the Extracted Data
We will be using C1Flexgrid control to display the obtained results to the user. The flexgrid will be bound to the collection of InvoiceData type objects.
flexgrid.ItemsSource = _invoiceData.GetInvoiceData();
flexgrid.RowDetailsVisibilityMode = DataGridRowDetailsVisibilityMode.Visible;
Below is an image of how the data is displayed in our application.

Conclusion
In the above article, we demonstrated how to extract information from multiple invoice emails using the C1TextParser library. This library is efficient enough to work with a variety of case scenarios to extract data from XML files. Download the demo.
Please refer here for more information about ComponentOne’s TextParser library.


















