
I’ve held several roles in my career in IT, ranging from software developer to enterprise architect to developer advocate. I’ve always been fascinated by the role that data plays in our applications—putting it into databases, getting it back out quickly, making sure it remains accurate when transferred between systems. Many of the hardest problems I’ve encountered have centered around data. For example:
Writing a cache eviction algorithm for an application that replayed hours worth of time-series radar data on a loop (ask me about the maintenance nightmare I created)
Learning how to form queries in Kibana so that we could pull just the right log statements to help us debug interactions between microservices and even down to the database.
One problem sits at the intersection of technology and the people building it. There’s an ongoing debate over when developers should be required to access data via APIs and when they should be allowed to write their own database queries directly.
Here, I’ll explore some of the solutions I’ve encountered in past projects and share why I’m excited about the Stargate project as a framework for solving this problem for everyone. Stargate is an open-source API gateway for data, built on top of Apache Cassandra.

A brief history of data access design patterns
Even back when we were writing monolithic applications, many of us committed to creating maintainable code were isolating data access and complex query logic behind object-relational mapping tools or using patterns like data access objects (DAOs). Later, when we started using service-oriented architecture (SOA), similar patterns for abstracting data access appeared.
While working in the hospitality industry, I helped design a cloud-based reservation system based on a microservices architecture. Following patterns inherited from our legacy SOA system, we found ourselves creating a set of services that we called entity services. Each entity service provided access to a particular data type such as hotels, rates, inventory, or reservations. I shared this architecture at Cassandra Summit and other conferences in 2016:
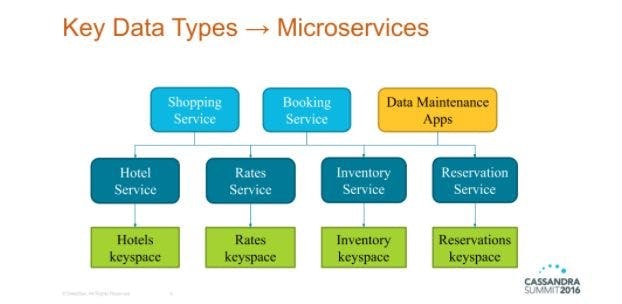
We layered services that implemented business processes on top of the entity services. The shopping service composed data from the hotel, rate, and inventory services to provide hotel and room options given desired dates and travel locations. The booking service wrote records into the reservation service and decremented the available room counts in the inventory service.
Each entity service was responsible for its own storage, and services were not permitted to access the storage of another service. This meant that each entity service could potentially have a different database, although, in practice, the initial entity services were all implemented on Cassandra, with a different keyspace to contain the tables used by each service.
Each entity service consisted of a few simple elements: an API layer (typically REST), business logic like data validation, and code to map between the data format presented on the API (typically JSON) and database queries implemented using a driver. I built a reference implementation of an entity service called the Reservation Service for my O’Reilly Cassandra book based on this architecture.
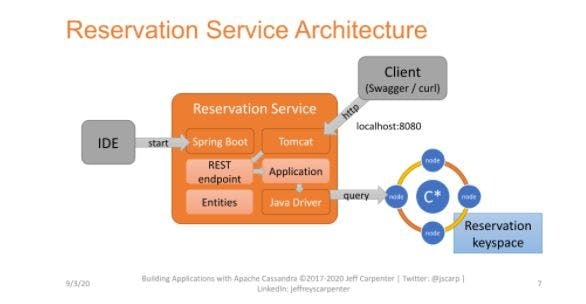
Drawbacks of entity services
Over time I began to observe that these entity services followed similar patterns in their API templates, validation logic, and database logic. While using frameworks such as Java Spring certainly helped with the API layer, logging, and other concerns, I wondered if there was more we could do to eliminate a lot of similar-looking code. The database access code, in particular, was quite formulaic:
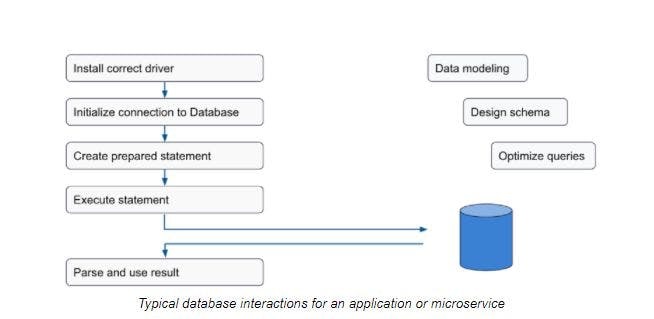
We encountered a performance challenge as well. Having multiple layers of microservices meant additional latency as client requests traversed business services, entity services, and the database.
There are few new problems in computer science
It turns out that my team was not the only one encountering these issues and coming up with solutions. At DataStax Accelerate 2019 (our annual Cassandra community gathering), Michael Figurere shared how Instagram introduced the concept of a Cassandra gateway into their architecture.
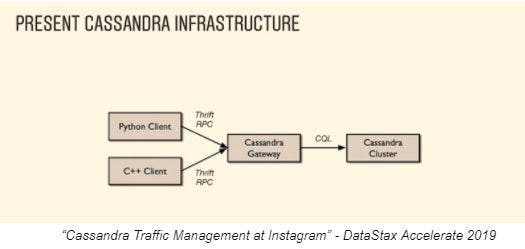
The motivations for introducing this gateway layer were familiar to my ears:
A desire to abstract the details of writing application queries from developers
A desire to support increased throughput and lower latency
A strategy for using familiar APIs to minimize impact to client applications
In an interesting twist, the “familiar API” was Cassandra’s legacy Thrift-based API. Instagram had a large investment in clients using Thrift. Introducing the gateway promoted client reuse, while providing a translation between Thrift and Cassandra’s more modern CQL API. This layer also made it much easier to upgrade Cassandra versions.
This highlights an interesting phenomenon: while the desire for an API layer to abstract data access is common across many organizations, each organization tends to have its own unique API requirements. There are often existing services with various API styles (such as REST, gRPC, Thrift) and data formats (such as JSON or protobuf). What if we could avoid the hassle of maintaining a bunch of services that are just thin wrappers around the database?
Enter Stargate
This desire to provide a common layer for data access with multiple different API styles inspired the Stargate project. The basic idea is simple: collapse the API layer into the database. As the picture shows, Stargate provides a pluggable framework for adding different API styles on top of Cassandra-compatible databases.
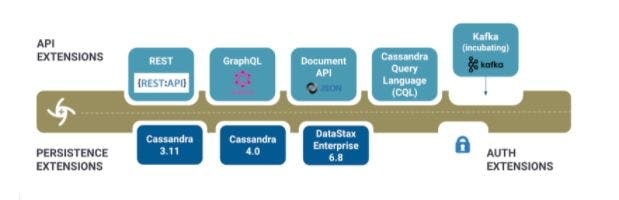
At the time of writing, the following API plugins are supported:
RESTful APIs This plugin exposes existing tables defined via CQL in a connected Cassandra cluster and provides an endpoint for creating a new schema. Data payloads are defined as JSON objects.
GraphQL APIs This plugin exposes CQL tables as a GraphQL API. A couple of features I absolutely love about GraphQL are the ability to request a subset of the fields of a returned row of data and the ability to compose data from multiple tables in a single query.
Document API This plugin is what I point to when people ask if Cassandra is “schemaless” like Mongo DB. Traditionally the answer to this has been “no”—Cassandra requires a schema defined by CQL. However, the Document API changes all this, enabling you to throw arbitrary JSON documents at Stargate, which stores them and then lets you query documents or sub-documents.
CQL API This plugin supports Cassandra’s native query language. You might wonder why you would use this instead of one of the other APIs or just accessing a Cassandra cluster directly. The main reason, in my opinion, is a cool pattern I want to show you now.
The hidden benefit of an old idea
An interesting aspect of Stargate’s architecture is that Stargate nodes are actually Cassandra nodes. They participate in Cassandra’s distributed architecture as nodes that respond to client queries but don’t actually store any data, delegating storage and retrieval to regular Cassandra nodes. This enables a flexible scaling approach that wasn’t possible previously. Now you can scale the number of Stargate nodes to handle your query volume and the number of Cassandra nodes to handle your storage volume.
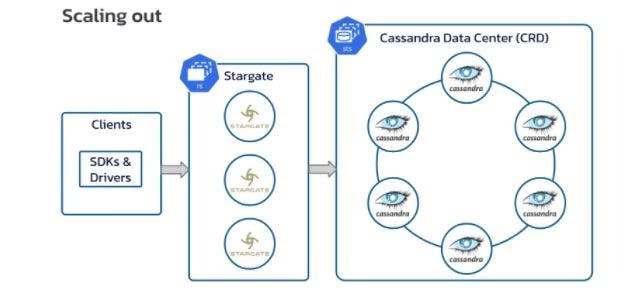
As it turns out, the idea of nodes that participate in a Cassandra cluster but don’t store data is not a new one. For example, longtime community member Eric Lubow introduced a similar concept called “coordinator nodes” (also known as “proxy nodes”) in his talk at Cassandra Summit 2016, based on his work at SimpleReach:
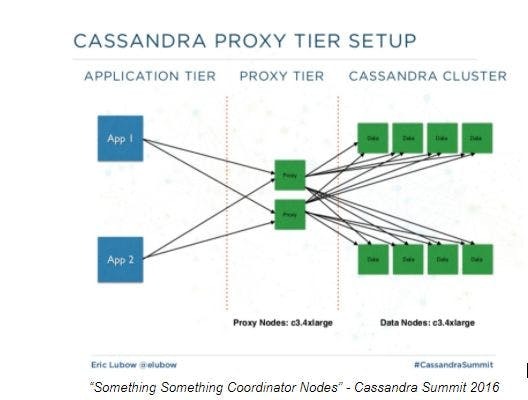
As shown in the figure above, the coordinator nodes can use different instance types than other “data nodes” in the cluster to support optimal use of resources and save on cloud computing costs. This is a benefit that Stargate provides as well, and one that is easily realized when deploying Stargate on Kubernetes as part of the K8ssandra project, just by changing a few values in a YAML config file to specify a different instance type.
More exciting possibilities ahead
Because of Stargate’s pluggable architecture, you can extend it for your own API needs and define additional APIs or tailor one of the existing open-source connectors to match your enterprise API standards. The roadmap includes plugins for gRPC, and streaming interfaces such as Pulsar and Kafka.
I’m also excited about the possibilities when the Stargate and K8ssandra open source projects are used together. The goal is to provide a production-ready, Cassandra-based data layer that you can install in any Kubernetes environment in minutes and focus on coding your apps. If you'd like to play with Cassandra quickly off K8s, try the managed DataStax Astra DB, which is built on Apache Cassandra.
Beyond these two projects, there’s another community of people from different organizations who have come together to dream up the future of cloud-based data infrastructure - the Data on Kubernetes community (in fact, this article is based on my talk at the Data on Kubernetes Community Day at KubeCon EU 2021). We’d love to work with you in any or all of these communities!


















