
Vector indexes are the hottest topic in databases because approximate nearest neighbor (ANN) vector search puts the R in RAG (retrieval-augmented generation). “Nearest neighbor” for text embedding models is almost always measured with angular distance, for instance, the cosine between two vectors. Getting the retrieval accurate and efficient is a critical factor for the entire application; failing to find relevant context — or taking too long to find it — will leave your large language model (LLM) prone to hallucination and your users frustrated.
Every general-purpose ANN index is built on a graph structure. This is because graph-based indexes allow for incremental updates, good recall and low-latency queries. (The one exception was pgvector, which started with a partition-based index, but its creators switched to a graph approach as fast as they could because the partitioning approach was far too slow.)
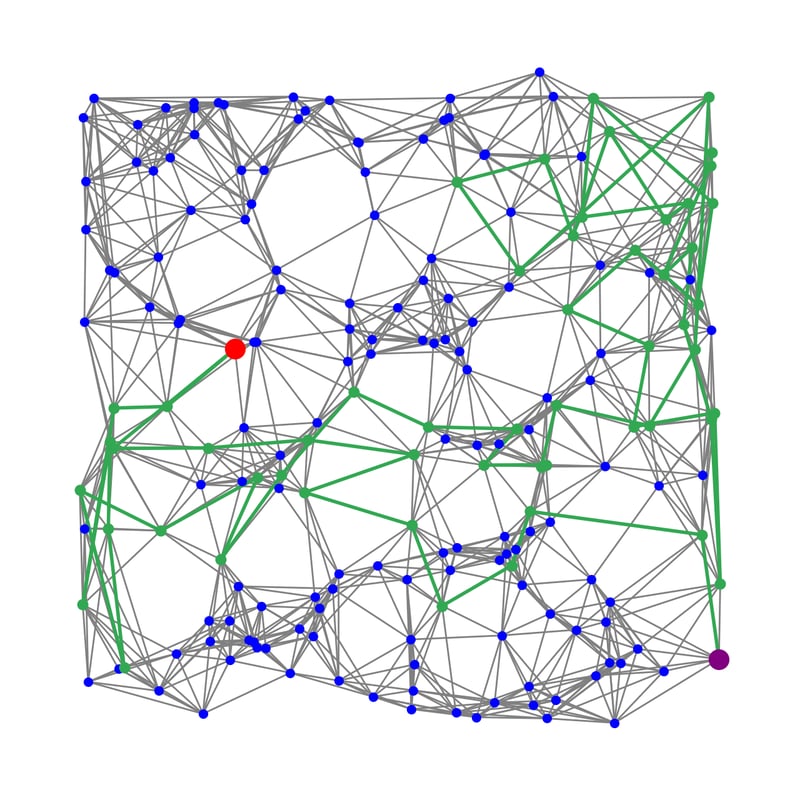
Caption: Visualization of searching for the closest neighbors of the red target vector in a graph index, starting from the purple entry point.
The well-known downside to graph indexes is that they are incredibly memory-hungry, because the entire set of vectors needs to live in memory. This is because you need to compare your query vector to the neighbors of each node you encounter as you expand your search through the graph, and this is very close to a uniformly random distribution of vectors being accessed. Standard database assumptions that 80% of your accesses will be to 20% of your data do not hold, so straightforward caching will not help you avoid a huge memory footprint.
For most of 2023, this flew under the radar of most people using these graph indexes simply because most users were not dealing with large enough data sets to make this a serious problem. That is no longer the case; with vectorized data sets like all of Wikipedia being easily available, it’s clear that vector search in production needs a better solution than throwing larger machines at the problem.
Breaking the memory barrier with DiskANN
Microsoft Research in 2019 proposed an elegant solution to the problem of large vector indexes in “DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node.” At a high level, the solution has two parts. First, (lossily) compress the vectors using product quantization (PQ). The compressed vectors are retained in memory instead of the full-resolution originals, reducing the memory footprint while also speeding up search.
JVector builds on the ideas in DiskANN to provide state-of-the-art vector search for Java applications. I’ve used the JVector Bench driver to visualize how recall (search accuracy) degrades when searching for the top 100 neighbors in data sets created by different embedding models against a small sample of chunked Wikipedia articles. (The data sets are built using the open source Neighborhood Watch tool.) Perfect accuracy would be a recall of 1.0.

It’s clear that recall suffers only a little at 4x and 8x compression, but falls off quickly after that.
That’s where the second part of DiskANN comes in. To achieve higher compression (which allows fitting larger indexes into memory) while making up for the reduced accuracy, DiskANN overqueries (searches deeper into the graph) and then reranks the results using the full-precision vectors that are retained on disk.
Here’s how recall looks when we add in overquery of up to 3x (such as retrieving the top 300 results using the PQ in-memory similarity) and then reranking to top 100. To keep the graph simple, we’ll focus on the openai-v3-small dataset:

With 3x overquery ( fetching the top 300 results for a top 100 query using the compressed vectors, and then reranking with full resolution), we can compress the openai-v3-small vectors up to 64x while maintaining or exceeding the original accuracy.
PQ + rerank is how JVector takes advantage of the strengths of both fast memory and cheap disk to deliver a hybrid index that offers the best of both worlds. To make this more user-friendly, DataStax Astra DB simplifies this to a single source_model setting when creating the index – tell Astra DB where your embeddings come from, and it will automatically use the optimal settings.
(If you want to go deeper on how PQ works, Peggy Chang wrote up the best explanation of PQ that I’ve seen — or you can always go straight to the source.)
Binary quantization
Binary quantization (BQ) is an alternative approach to vector compression, where each float32 component is quantized to either 0 (if negative) or 1 (if positive). This is extremely lossy! But it’s still enough to provide useful results for some embeddings sources if you overquery appropriately, which makes it potentially attractive because computing BQ similarity is so fast — essentially just the Hamming distance, which can be computed blisteringly quickly using SWAR (here’s OpenJDK’s implementation of the core method). Here’s how BQ recall looks with 1x to 4x overquery against the same five data sets:

This shows the limitations of BQ:
- Even with overquery, too much accuracy is lost for most sources to make it back up.
- OpenAI-v3-small is one of the models that compresses nicely with BQ, but we can get even more compression with PQ (64x!) without losing accuracy.
Thus, the only model that Astra compresses with BQ by default is ada-002, and it needs 4x overquery to match uncompressed recall there.
But BQ comparisons really are fast, to the point that they are almost negligible in the search cost. So wouldn’t it be worth pushing overquery just a bit higher for models that retain almost as much accuracy with BQ, like Gecko (the Google Vertex embedding model)?
The problem is that the more overquery you need to do to make up for the accuracy you lose to compression, the more work there is to do in the reranking phase, and that becomes the dominant factor. Here’s what the numbers look like for Gecko with PQ compressing the same amount as BQ (32x) and achieving nearly the same recall (BQ recall is slightly worse, 0.90 vs 0.92):

For 20,000 searches, BQ evaluated 131 million nodes while PQ touched 86 million. This is expected, because the number of nodes evaluated in an ANN search is almost linear with respect to the result set size requested.
As a consequence, while the core BQ approximate similarity is almost 4x faster than PQ approximate similarity, the total search time is 50% higher, because it loses more time in reranking and in the rest of the search overhead (loading neighbor lists, tracking the visited set, etc.).
Over the past year of working in this field, I’ve come to believe that product quantization is the quicksort of vector compression. It’s a simple algorithm and it’s been around for a long time, but it’s nearly impossible to beat it consistently across a wide set of use cases because its combination of speed and accuracy is almost unreasonably good.
What about multi-vector ranking?
I’ll conclude by explaining how vector compression relates to ColBERT, a higher-level technique that Astra DB customers are starting to use successfully.
Retrieval using a single vector is called dense passage retrieval (DPR), because an entire passage (dozens to hundreds of tokens) is encoded as a single vector. ColBERT instead encodes a vector-per-token, where each vector is influenced by surrounding context. This leads to meaningfully better results; for example, here’s ColBERT running on Astra DB compared to DPR using openai-v3-small vectors, compared with TruLens for the Braintrust Coda Help Desk data set. ColBERT easily beats DPR at correctness, context relevance, and groundedness.

The challenge with ColBERT is that it generates an order of magnitude more vector data than DPR. While the ColBERT project comes with its own specialized index compression, this suffers from similar weaknesses as other partition-based indexes; in particular, it cannot be constructed incrementally, so it’s only suitable for static, known-in-advance data sets.
Fortunately, it’s straightforward to implement ColBERT retrieval and ranking on Astra DB. Here’s how compression vs. recall looks with the BERT vectors generated by ColBERT:

The sweet spot for these vectors is PQ with 16x compression and 2x overquery; 32x PQ as well as BQ loses too much accuracy.
Product quantization enables Astra DB to serve large ColBERT indexes with accurate and fast results.
Beyond simple reranking
Supporting larger-than-memory indexes for Astra DB’s multitenant cloud database was table stakes for JVector. More recently, the JVector team has been working on validating and implementing improvements that go beyond basic DiskANN-style compression + reranking. Some of these include:
- Anisotropic quantization from “Accelerating Large-Scale Inference with Anisotropic Vector Quantization”
- Fused graphs that accelerate PQ computation as described in “Quicker ADC: Unlocking the hidden potential of Product Quantization with SIMD”
- Locally-adaptive quantization from “Similarity search in the blink of an eye with compressed indices”
- Larger-than-memory index construction using compressed vectors (first implemented in JVector, to my knowledge)
JVector currently powers vector search for Astra DB, Apache Cassandra and Upstash’s vector database, with more on the way. Astra DB constantly and invisibly incorporates the latest JVector improvements; try it out today.


















