

By Christopher Bradford and Ty Morton
Global applications need a data layer that is as distributed as the users they serve. Apache Cassandra has risen to this challenge, handling data needs for the likes of Apple, Netflix and Sony. Traditionally, managing data layers for a distributed application was handled with dedicated teams to manage the deployment and operations of thousands of nodes — both on-premises and in the cloud.
To alleviate much of the load felt by DevOps teams, we evolved a number of these practices and patterns in K8ssandra, leveraging the common control plane afforded by Kubernetes (K8s) There has been a catch though — running a database (or indeed any application) across multiple regions or K8s clusters is tricky without proper care and planning up front.
To show you how we did this, let’s start by looking at a single region K8ssandra deployment running on a lone K8s cluster. It is made up of six Cassandra nodes spread across three availability zones within that region, with two Cassandra nodes in each availability zone. In this example, we’ll use the Google Cloud Platform (GCP) zone name. However, our example here could just as easily apply to other clouds or even on-prem.
Here’s where we are now:
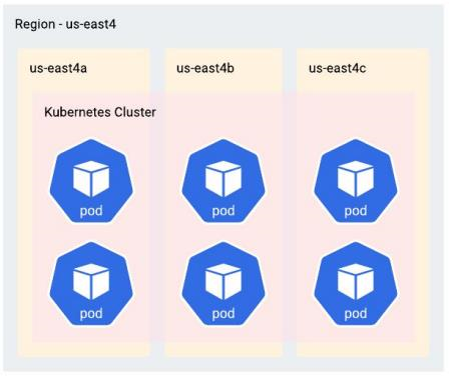
Existing deployment of our cloud database.
The goal is to have two regions, each with a Cassandra data center. In our cloud-managed K8s deployment here, this translates to two K8s clusters — each with a separate control plane, but utilizing a common virtual private cloud (VPC) network. By expanding our Cassandra cluster into multiple data centers, we have redundancy in case of a regional outage, as well as improved response times and latencies to our client applications given local access to data.
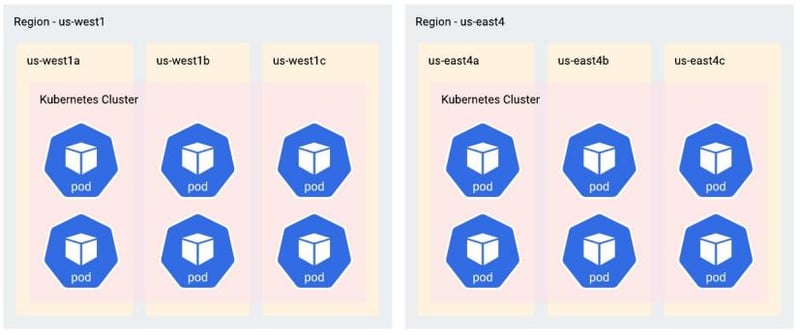
This is our goal: to have two regions, each with their own Cassandra data center.
On the surface, it would seem like we could achieve this by simply spinning up another K8s cluster deploying the same K8s YAML. Then just add a couple tweaks for Availability Zone names and we can call it done, right? Ultimately the shape of the resources is very similar, and it’s all K8s objects. So, shouldn’t this just work? Well, maybe. Depending on your environment, this approach might work.
If you’re really lucky, you may be a firewall rule away from a fully distributed database deployment. Unfortunately, it’s rarely that simple. Even if some of these hurdles are easily cleared, there are plenty of other innocuous things that can go wrong and lead to a degraded state. Your choice of cloud provider, K8s distro, command-line flag, and yes, even DNS — these can all potentially lead you down a dark and stormy path. So, let’s explore some of the most common issues you might run into, so you can avoid them.
Common hurdles on the race to scale
Even if some of your deployment seems to be working well initially, you will likely encounter a hurdle or two as you grow into a multicloud environment, upgrade to another K8s version, or begin working with different distributions and complimentary tooling. When it comes to distributed databases there’s a lot more under the hood. Understanding what K8s is doing to enable running containers across a fleet of hardware will help you develop advanced solutions — and ultimately, something that fits your exact needs.
The need for unique IP addresses for your Cassandra nodes
One of the first hurdles you might run into involves basic networking. Going back to our first cluster, let’s take a look at the layers of networking involved.
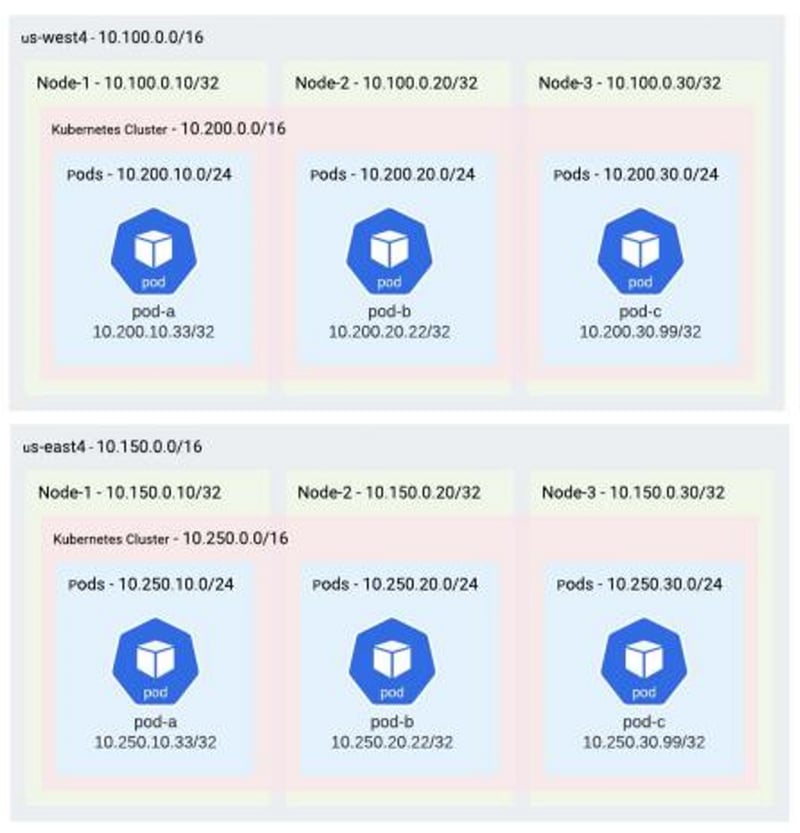
In our VPC shown below, we have a Classless Inter-Domain Routing (CIDR) range representing the addresses for the K8s worker instances. Within the scope of the K8s cluster there is a separate address space where pods operate and containers run. A pod is a collection of containers that have shared resources — such as storage, networking, and process space.
In some cloud environments, these subnets are tied to specific availability zones. So, you might have a CIDR range for each subnet your K8s workers are launched into. You may also have other virtual machines within your VPC, but in this example we’ll stick with K8s being the only tenant.

CIDR ranges used by a VPC with a K8s layer
In our example, we have 10.100.x.x for the nodes and 10.200.x.x for the K8s level. Each of the K8s workers gets a slice of the 10.200.x.x CIDR range for the pods that are running on that individual instance.
Thinking back to our target structure, what happens if both clusters utilize the same or overlapping CIDR address ranges? You may remember these error messages when first getting into networking:
Common error messages when trying to connect two networks.
Errors don’t look like this with K8s. You don’t have an alert that pops up warning you that your clusters cannot effectively communicate.
If you have a cluster that has one IP space, and then you have another cluster for the same IP space or where they overlap, how does each cluster know when a particular packet needs to leave its address space and instead route through the VPC network to the other cluster, and then into that cluster’s network?
By default there really is no hint here. There are some ways around this; but at a high level, if you’re overlapping, you’re asking for a bad time. The point here is that you need to understand your address space for each cluster and then carefully plan the assignment and usage of those IPs. This allows for the Linux kernel (where K8s routing happens) and the VPC network layer to forward and route packets as appropriate.
But, what if you don’t have enough IPs? In some cases, you can’t give every pod its own IP address. So, in this case, you would need to take a step back and determine what services absolutely must have a unique address and what services can be running together in the same address space. For example, if your database here needs to be able to talk to each and every other pod, it probably needs its own unique address. But if your application tiers in the East Coast and in the West Coast are just talking to their local data layer, they can have their own dedicated K8s clusters with the same address range and avoid conflict.
Flattening out the network.
In our reference deployment, we dedicated non-overlapping ranges in K8s clusters for the layers of infrastructure that MUST be unique and overlapping CIDR ranges where services will not communicate. Ultimately, what we’re doing here is flattening out the network.
With non-overlapping IP ranges, we can now move on to routing packets to pods in each cluster. In the figure above, you can see the West Coast is 10.100, and the East Coast is 10.150, with the K8s pods receiving IPs from those ranges. The K8s clusters have their own IP space, 200 versus 250, and the pods are sliced off just like they were previously.
How to handle routing between the Cassandra data centers
So, we have a bunch of IP addresses and we have uniqueness to those addresses. Now, how do we handle the routing of this data and the communication and discovery of all of this? There’s no way for the packets destined for cluster A to know how they need to be routed to cluster B. When we attempt to send a packet across cluster boundaries, the local Linux networking stack sees that this is not local to this host or any of the hosts within the local K8s cluster. It then forwards the packet on to the VPC network. From here, our cloud provider must have a routing table entry to understand where this packet needs to go.
In some cases this will just work out of the box. The VPC routing table is updated with the pod and service CIDR ranges, informing which hosts packets should be routed. In other environments, including hybrid and on-premises, this may take the form of advertising the routes via BGP to the networking layer. Yahoo! Japan has a great article covering this exact deployment method.
However, these options might not always be the best answer, depending on what your multi-cluster architecture looks like within a single cloud provider. Is it hybrid- or multi-cloud, with a combination of on-prem, with two different cloud providers? While you could certainly instrument all that across all those different environments, you can count on it requiring a lot of time and upkeep.
Some solutions to consider
Overlay networks
An easier answer is to use overlay networks, in which you build out a separate IP address space for your application — which, in this case, is a Cassandra database. Then you would run that on top of the existing Kube network leveraging proxies, sidecars and gateways. We won’t go too far into that in this post, but we have some great content on how to connect stateful workloads across K8s clusters that will show you at a high level how to do that.
So, what’s next? Packets are flowing, but now you have some new K8s shenanigans to deal with. Assuming that you get the network in place and have all the appropriate routing, some connectivity between these clusters exists, at least at an IP layer. You have IP connectivity pods and Cluster 1 can talk to Pods and Cluster 2, but you now also have some new things to think about.
Service discovery
With a K8s network, identity is transient. Due to cluster events, a pod may be rescheduled and receive a new network address. In some applications this isn’t a problem. In others, like databases, the network address is the identity — which can lead to unexpected behavior. Even though IP addresses may change, over time our storage and thus the data each pod represents stays persistent. We must have a way to maintain a mapping of addresses to applications. This is where service discovery enters the fold.
In most circumstances service discovery is implemented via DNS within K8s. Even though a pod’s IP address may change, it can have a persistent DNS-based identity that is updated as cluster events occur. This sounds great, but when we enter the world of multi-cluster we have to ensure that our services are discoverable across cluster boundaries. As a pod in Cluster 1, I should be able to get the address for a pod in Cluster 2.
DNS stubs
One approach to this conundrum is DNS stubs. In this configuration we configure the K8s DNS services to route requests for a specific domain suffix to our remote cluster(s). With a fully qualified domain name, we can then forward the DNS lookup request to the appropriate cluster for resolution and ultimately routing.
The gotcha here is that each cluster requires a separate DNS suffix set through a kubelet flag, which isn’t an option in all flavors of K8s. Some users work around this by using namespace names as part of the FQDN to configure the stub. This works, but is a little bit of a hack instead of setting up proper cluster suffixes.
Managed DNS
Another solution similar to DNS stubs is to use a managed DNS product. In the case of GCP there is the Cloud DNS product, which handles replicating local DNS entries up to the VPC level for resolution by outside clusters, or even virtual machines within the same VPC. This option offers a lot of benefits, including:
- Removing the overhead of managing the cluster-hosted DNS server — Cloud DNS requires no scaling, monitoring, or managing of DNS instances, because it is a hosted Google service.
- Local resolution of DNS queries on each Google K8s Engine (GKE) node — Similar to NodeLocal DNSCache, Cloud DNS caches DNS responses locally, providing low latency and high scalability DNS resolution.
- Integration with Google Cloud’s operations suite — This provides for DNS monitoring and logging.
- VPC scope DNS — Provides for multi-cluster, multi-environment, and VPC-wide K8s service resolution.
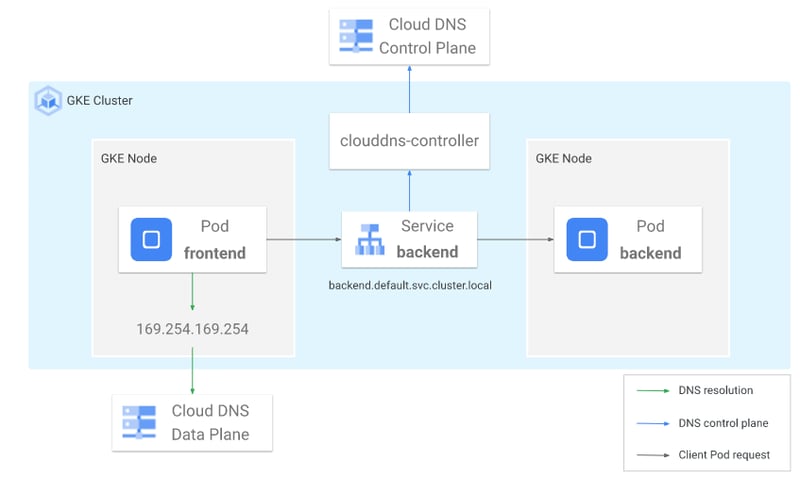
Replicated managed DNS for multi-cluster service discovery.
Cloud DNS abstracts away a lot of the traditional overhead that you would have. The cloud provider is going to manage the scaling, the monitoring and security patches, and all the other aspects you would expect from a managed offering. There are also some added benefits to some of the cloud providers with GKE providing a node local DNS cache, which reduces latency by running a DNS cache at a lower level so that you’re not waiting on DNS response.
For the long term, a managed service specifically for DNS will work fine if you’re only in a single cloud. But, if you’re spanning clusters across multiple cloud providers and your on-prem environment, managed offerings may only be part of the solution.
The Cloud Native Computing Foundation (CNCF) provides a multitude of options, and there are tons of open source projects that really have come a long way in helping to alleviate some of these pain points, especially in that cross-cloud, multi-cloud, or hybrid-cloud type of scenario.
Curious to learn more about (or play with) Cassandra itself? We recommend trying it on the Astra DB free plan for the fastest setup.
Follow the DataStax Tech Blog for more developer stories. Check out our YouTube channel for tutorials and here for DataStax Developers on Twitter for the latest news about our developer community.


















