
Aujourd'hui mercredi 18 mai avait lieu l'ouverture de la KubeCon 2022 ! Voici ce que les Stackers sur place ont retenu de cette première journée.
Par @vixsty, @eisenkremer, @aimbot31, @psclgllt, @launoirt
Keynote
Finding Your Power to Accelerate to a Sustainable Future
Une des keynotes d'ouverture de la KubeCon 2022, présentée par Kate Mulhall & Emma Collins d'Intel, adresse la nécessité de renforcer l'efficacité énergétique des data centers. À titre d'exemple, les data centers consomment aujourd'hui 2% de l'électricité produite mondialement, 8% d'ici 2030. Les CPUs sont utilisés entre 20 et 40% de leur capacité seulement. Les présentatrices rappellent aussi le désormais célèbre classement des langages de programmation par efficacité énergétique: des plus sobres C et Rust,... jusqu'à Perl, le plus énergivore.
En partant du hardware, et en passant par une meilleure conception des charges de travail et leur orchestration plus intelligente, il est possible de réduire la consommation d'énergie et par conséquent réduire notre empreinte carbone. La collecte des données d'observabilité (télémétrie) et leur analyse, et l'apprentissage machine jouent un rôle important pour y parvenir. Les optimisations peuvent être faites à tous les niveaux compute, réseau et stockage.
Intel aspire à être un leader mondial en matière de développement durable (voir https://www.intel.com/content/www/us/en/environment/intel-and-the-environment.html).
Au delà du discours, cette présentation nous rappelle que la responsabilité écologique et ses solutions se trouvent d'abord entre les mains des développeurs.
La présentation "working your K8s cluster: smarter scheduling decisions for your workloads" qui suit l'après-midi, toujours par Intel, rentre dans le vif du sujet et aborde des solutions concrètes. Voir https://github.com/intel/platform-aware-scheduling
Incremental Deep Learning for Satellites with KubeEdge and MindSpore
Zhipeng Huang, Director, AI Open Source, Huawei
Xiaoman Hu, Community Operation Director, Huawei
Yue Bao, Software Engineer, Huawei
Dans cette keynote, Huawei, nous démontre une nouvelle façon de gérer la communication avec des satellites, en étendant votre cluster Kubernetes jusque dans vos satellites. Cela permet d’uniformiser vos déploiements de bout en bout.
KubeEdge propose de manager vos satellites en déployant vos workload de la meme façon que sur un worker node classique.

Le son de cette keynote, enregistrée au préalable étant de très mauvaise qualité, nous vous conseillons de retrouver les slides de présentation dans le programme de la KubeCon.
Conférences
Bypassing Falco: How to Compromise a Cluster without Tripping the SOC - Shay Berkovich, BlackBerry
Falco est un outil de détection d'évènements pour Kubernetes. Il permet de lever une alerte en cas de détection d'activité suspecte comme une connexion SSH sur un pod.
Dans cette présentation Shay Berkovich nous explique comment compromettre un cluster sans déclencher d'alerte sur Falco.
Il a présenté plusieurs types de méthodes :
- Chemin relatif sur un lien symbolique
- Utiliser une implémentation différente d'un exploit de CVE
- Renommer les exécutables
- Lien symbolique d'un exécutable
- Exécution de script au lieu de commande
- Utilisation de mknod et mkfifo pour un reverse shell
Il a publié une image contenant tous les outils pour tester ces techniques d'évasion.
Vous pouvez la trouver ici :
Il a conclu sa présentation avec les recommandations suivantes pour la création de règles Falco :
- Bien choisir les hooking points pour augmenter la fiabilité des règles
- Éviter d'utiliser des règles basées sur proc.name / proc.aname et filename car elles sont faciles à contourner
- Ne pas introduire d'exception “and not” car cela crée une porte d'entrée pour les attaquants
- Réévaluer la priorité des règles dans le contexte d'une évasion de règles
- Faire une veille régulière des exploits publics
- Développer ses propres règles privées pour que l'attaquant ne sache pas ce qui est surveillé et comment contourner les règles
Effective Disaster Recovery: The Day We Deleted Production - Rick Spencer & Wojciech Kocjan, InfluxData
InfluxData nous fait ici un retour d'expérience suite à la perte accidentelle de tout un cluster de production.
Voici le dur réveil du VP Engineer en ce vendredi de septembre :
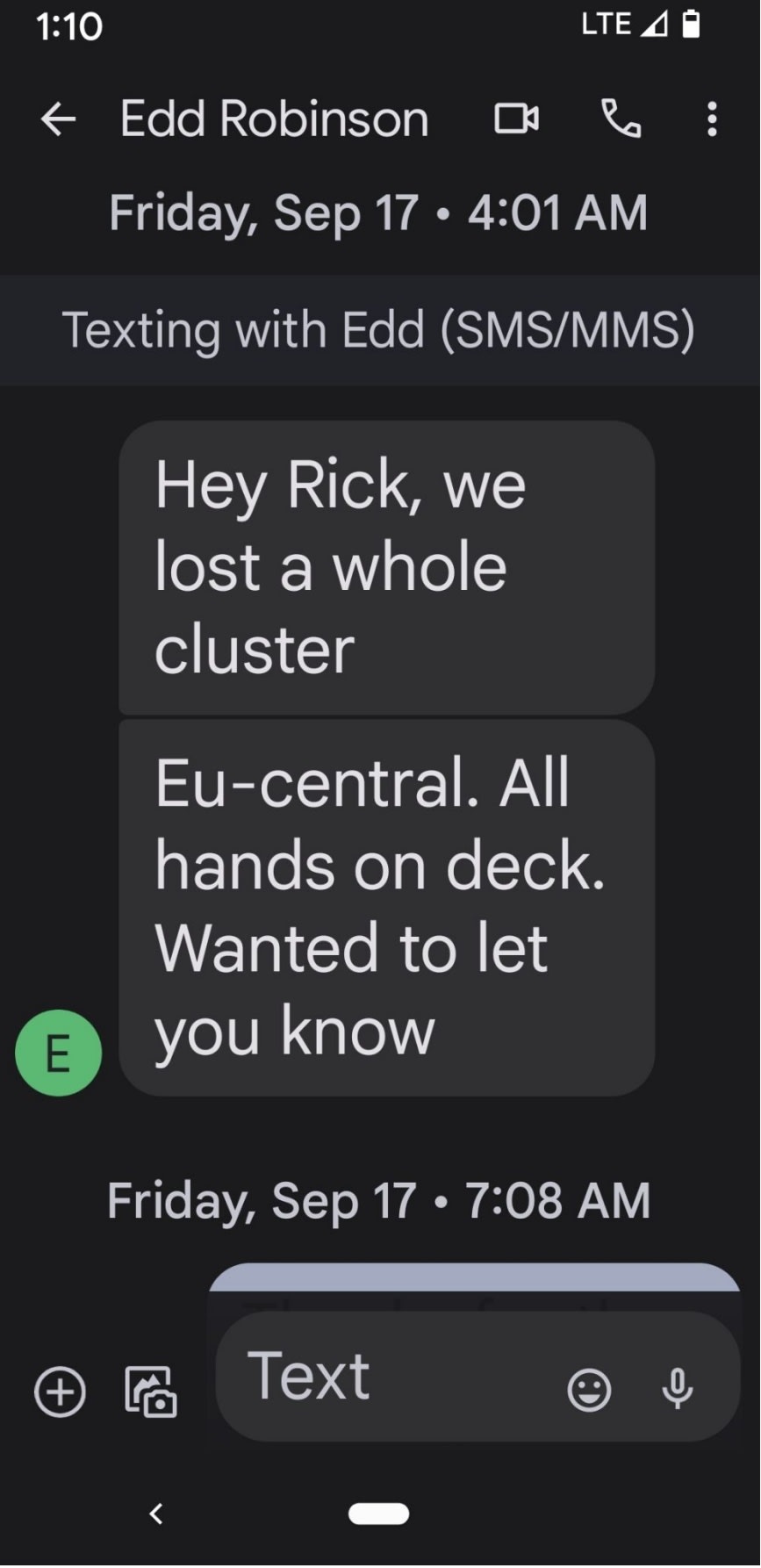
L'incident a débuté suite au merge d'une PR qui paraissait anodine, mais qui a mené à une collision de noms d'applications dans ArgoCD et ainsi à la destruction du cluster Kubernetes.
Trois minutes après le merge de la PR, leur système de monitoring InfluxData commence à lever des alertes.
Quinze minutes plus tard, la support team commence à répondre aux premiers incidents clients.
S'en suit un revert de la PR et le début du process de recovery.
Cinq heure trente après le début de l'incident, le cluster est de nouveau opérationnel.
Sans rentrer dans le long détail de ce process, voici ce que InfluxData en a retiré.
Tout d'abord ce qui a bien fonctionné :
- L'effort des différentes équipes pour remonter l'environnement
- Application indisponible (downtime) mais aucune perte de données
- Les équipes ont évité de céder à la panique, arrêté les tentatives infructueuses de rollback rapide et mis en place un plan d'action
- Les backups de données ont bien fonctionnés
Ce qui n'a pas marché :
- Leur chaîne de déploiement et d'automatisation n'a pas empêché la catastrophe
- Premiers rollback sous-optimaux
- Aucune procédure de reconstruction d'un cluster n'avait été écrite jusque là
Les équipes ont par la suite mis en place toute une série de règles et process pour éviter que cela ne se reproduise, notamment avec une meilleure revue des PR et l'amélioration de la configuration d’ArgoCD.
Multi-cluster Failover Using Linkerd - Charles Pretzer, Buoyant, Inc.
Charles Pretzer, field engineer at Buoyant, nous parle du produit linkerd, plus particulièrement comment faire du failover entre plusieurs clusters avec linkerd.
Dans ce talk, le speaker se sert « d’emojivoto »comme application d’exemple, cette appli génère du traffic avec 1/4 d’error rate.
Linkerd propose une fonctionnalité « multicluster » qui va nous permettre plusieurs choses :
- chiffrement du traffic entre les différents clusters
- Création de « services mirror »
Cette dernière fonctionnalité va être très intéressante pour contacter un service présent sur l’autre cluster afin de répartir la charge ou ségrégué le traffic en fonction de certains critères (localisation notamment). Un nouveau service va être créé sur l’autre cluster portant le même nom avec le nom du context de l’autre cluster à la fin.
Au niveau sécurité, les communications via les « services mirror » sont chiffrées via mTLS comme les communications dans le cluster.
Nous pouvons aussi nous servir de la spec SMI (ServiceMeshInterface) afin de spliter le traffic a travers les différents clusters de manière transparente pour les applications (sans changements dans l’application).
Les communications entre clusters peuvent-être unidirectionnelles ou bi-directionnelles. Une communication bi-directionnelle peut entraîner des checks circulaires, par chance, linkerd embarque une protection contre ce problème.
Plus d’informations : https://linkerd.io/2.10/features/multicluster/
How Lombard Odier Deployed VPA to Increase Resource Usage Efficiency - Vincent Sevel, Lombard Odier SA
Vincent Sevel, Architect / Platform Ops
Vincent nous propose d’essayer de répondre à la problématique suivante : “0/27 nodes are available: 19 Insufficient cpu”
Cette dernière est souvent induite par une mauvaise configuration des “requests” et “limits” de nos pods.
Le but:
Optimiser le placement
Ajuster les ressources des worker nodes
Économiser de l’argent
Pour répondre à cela nous allons essayer de récupérer dynamiquement les informations de consommation de nos pods afin de pouvoir les ajuster.

Le scale vertical de pod permet de :
Down-scale or Up-scale
Memory & CPU
Apply the recommendation (Opt)
React to OOM
Tous cela intégré dans des manifests Kubernetes
Ci dessous les ressource “économiser” grâce à ce set up:

La gestion de la mémoire est toujours en développement mais le projet est prometteur et réponds à un besoin de plus en plus présent.
Dans le futur :
Assess Memory/Initial
Densify
Bare Metal
Mix VPA with HPA/serverless
Expand VPA to Third Party packages
Si le sujet vous intéresse, vous pouvez lire cette article : https://povilasv.me/vertical-pod-autoscaling-the-definitive-guide/
Working your Cluster: Smarter Scheduling Decisions for Your Workloads - Madalina Lazar & Denisio Togashi, Intel
C’est ici une présentation des capacités de Platrorm Aware Scheduling et des problématiques que ce Kubernetes Scheduler Extenders tente de résoudre.

À savoir, permettre à nos exécutables d’avoir les ressources dont ils ont besoin en évitant de sur allouer. Avoir un Scheduling des pods plus intelligents que la simple utilisation de « resources request » permet d’y répondre. C’est rendu possible en permettant notamment l’utilisation de metrics externes et des stratégies plus évoluées.

Nous avons apprécié cette présentation qui tente d’apporter une réponse aux problématiques de sous consommation et de surcharge rencontré mais de notre première compréhension nous avons le sentiment que cela nécessitera du temps pour gérer une véritable stratégie. On rajoutera une petite attention particulière sur la gestion de deschedule qui peut être source de « flapping »


















