
One of the top challenges that organizations face when adopting Cloud is cloud cost management. The move from CapEx to OpEx, introducing challenges on both financial teams and technical teams to adapt their work methodology to be efficient in a Cloud environment. This change of mind is called FinOps. In a simple sentence : FinOps is the DevOps for Fin. This is as much a culture to adopt with practices and methodologies than a new job that needs sponsorship and skills. With this new concern, technical decisions to move to cloud, re-architecture a solution or new features development are more complicated to include financial decisions as recurrent activities on the projects.
FinOps principles and organization
The FinOps foundation defines FinOps as
“FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping engineering, finance, technology and business teams to collaborate on data-driven spending decisions.”
We note in this definition something very important: FinOps is not dealing with only cloud cost but with business value. This does not matter if cloud costs surge in so far as the business surges too. Actually, the purpose of FinOps is more to increase margins by decreasing Cloud costs per client. For example, increasing Cloud cost by 20% due to a new client on your solution does not matter if the client increases your benefits more than this 20%.
The FinOps activities are in the middle of Financial and Operational (thanks captain obvious). This means that technical teams (Dev, DevOps, Ops) and financial teams need to be able to elevate their skills to talk to each other. On the one hand, technical teams need to be able to talk about cloud cost forecast, discount on commitment, time & usage optimizations, rightsizing and on the other hand, financial teams need to be able to talk Cloud bill anatomy, budgets and alerting, non fixed bill per month and agile. This can lead to a culture shock if none of these teams has a dedicated vocabulary to communicate and processes to collaborate.
In this context, a FinOps team is very helpful to deep dive costs on the existing solution and project it on a hypothetical one. In this article, we will focus on how a FinOps engineer can help with methodology and tools to estimate the financial gain to move from backend services stack such as Kafka, Redis or ElasticSearch to Google Cloud (GCP) managed such MemoryStore, Pub/Sub or BigQuery.
Assess on what you already have and project on what you want/need
The top priority to start is to define one or several business cases to handle. This too complicated to address the whole challenge “I want to study the move every backend services to managed services”, we need to start with an inventory asset of what we have in terms of backend services, study the inbound and outbound traffic, the storage attached to it to really understand the usage of each backend service. With these kinds of metrics you have a snapshot of the user usage impacted on each of them.
Several questions will be very general and other specific to each backend service.
The next questions to ask is the target in terms of users also :
- Will the user traffic change ?
- Do you plan to have users in another area of the world ?
- Do you plan to extra use these backend services with new features on your product?
The idea behind is to stand on a envision of what the traffic and storage can be in the near future.
With this assessment and this projection, you have a big picture from a user centric perspective. you will also need to assess and project in terms of technique. Be able to assess on:
- The cloud strategy to be close to it
- The ops capacity of the team to identify activities bottleneck
- The already managed services used in the company to capitalized on them
- The technical skills of the team
- The specific usage of the backend services. For example in services like Kafka are we using advanced features like Kafka streams? In ElasticSearch, are we using geospatial features? The purpose here is to identify if the backend service is not switchable to a managed services due to specific usage of it
- The cost the usage of the backend service but also the license and/or support for it
After the business and technical assessment and projection, you have a whole picture to conduct a study to evaluate the gain to move to managed services nowadays but also by projection to a near future.
Mirroring current backend services usage with GCP managed services
One of the big challenges is to be able to map pricing models for these backend services (more or less based on Compute Engine with RAM, vCPU, Disks and Egress) to managed services with large differences in the pricing model. For example,
-
Memorystore, the GCP managed service for cache, is not a service by itself, you need to choice the backend behind with Redis or memcached. These two kinds of configurations for Memorystore do not have the same model pricing.
- Memorystore for memcached is mostly based on Compute Engine model with pricing based on the number of nodes and vCPU + RAM per node. Even if the model pricing is nearly the same, the prices themselves are different to allocate a VM with a flavor. However, the egress traffic is not billed within the same region on Memorystore for memcached contrary to VM inter-zone egress. What can we conclude from that? Well, the node itself will be more expensive than a VM but the inter-zonal egress is not to take into account. The migration choice should be balanced on both model pricing differences.
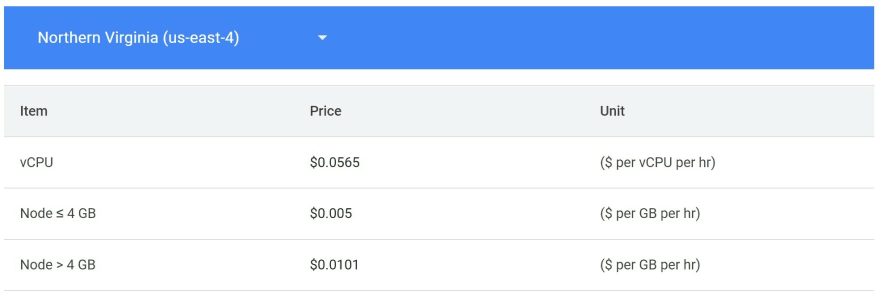
- Memorystore for Redis has two levels of service: a basic and standard. The first is mono instance or manual node replication whereas the second is high availability with native node redundancy. The model pricing for both of them is based on provisioned capacity that implies a range of RAM and a network performance. This pricing model is close to Compute Engine VM with flavor implying network performance but with their owns flavors only based on RAM and not vCPU. On the egress side, the inter-zonal is free such as on memcached and the others egress traffic has special prices based on number of nodes
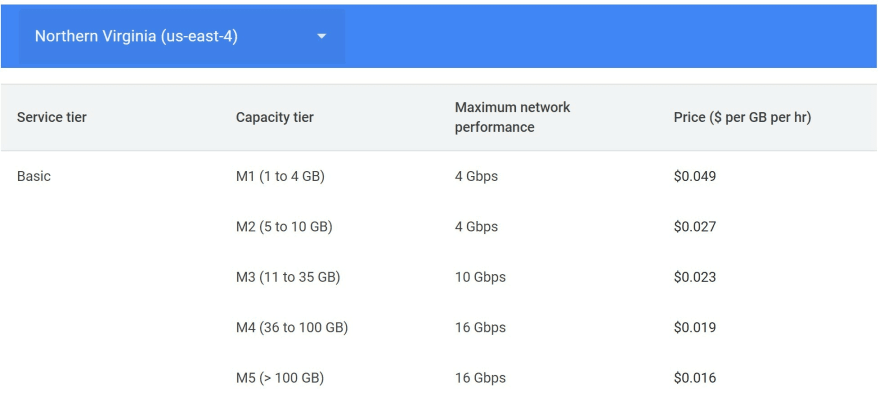
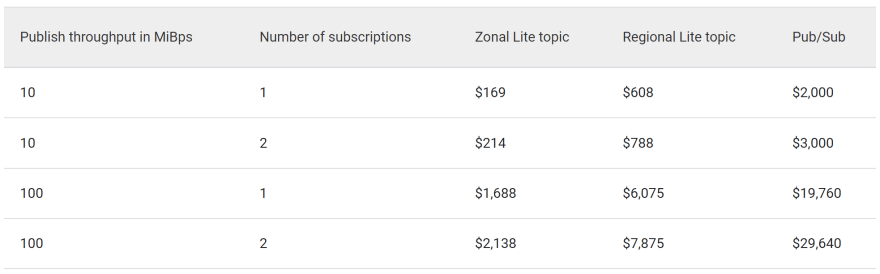
- Pub/Sub, the GCP managed service for message queuing, has two levels of services on standard and one Lite. Standard is the high availability version of it and Lite could be a zonal or regional service with infrastructure managed by the client. Obviously, the model pricing will be very different with a x10 between Standard and zonal Lite. However, the model pricing is the same is based on throughput for message publishing, message storage costs and egress for message distribution. Here, we totally break the similarity with a VM model (except on storage). Everything is drived on volumetry and performance of inbound and outbound messages.
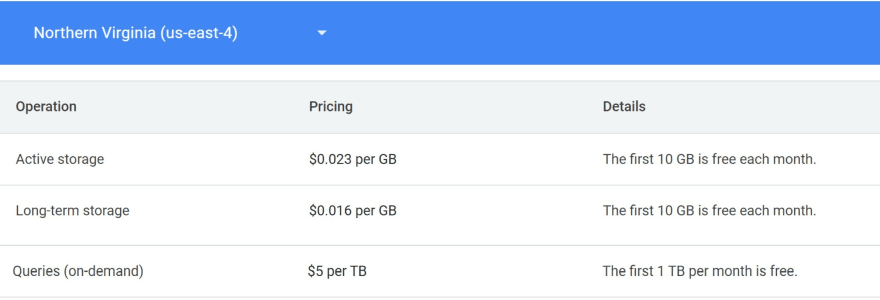
- BigQuery has a pricing model close to Pub/Sub : you pay for what you insert on the database (in streaming) and the storage of these data. The main difference is on what you can do with these data. BigQuery is not a message queuing service, this is a data warehouse service. It proposes a query service to exploit these data and you pay for these queries. Actually, not on the query itself but on the quantity of data manipulated for producing the results of the query. This means that you do not directly pay for a power capacity on query but on data transfer to produce the result which is very different from a none managed database perspective such SQL databases where the main model pricing is the node size to store and query data.
Disclaimer: The pricing model on managed services can evolve. The analysis was based on August 2022 model pricing.
In the beginning of this section, the purpose was to assimilate the heterogeneity of managed service pricing. Sometimes is close to the infrastructure behind such as Memorystore but with enough differences to not be able to directly compare with our already in-place backend service. Sometimes, this is a break changer on model pricing and comparison is difficult and sometimes, managed services have options of service level that have a direct impact on model pricing.
To be able to evaluate the cost gain to move to managed service, the challenge is to reach a really good understanding of the managed services pricing but also the options of configurations offered by them. With this big picture, you will need to extract your billed baseline on the backend service that you want to remove such as minutes of vCPU and RAM, quantity of disk storage, quantity of egress in inter-zone and inter-region to be able to map these basic metrics on managed services model pricing. You should be able at the end to assess the current pricing of your backend service and estimate what it should be in a GCP managed service.
The exercise is not so easy, even more in managed service where scalability is automated but billed such as App Engine and Cloud Run. Fortunately, these services are more for business applications rather than for backend services that we addressed in this article ;)
Forecasting managed services cost in the near future
The next step to achieve after this mirroring of usage between already in place backend services and GCP managed services is to gain the projection on them with the business forecast. The purpose is to be able to make decisions based not only on the current usage but also on what we can expect in the near future.
To do that, concrete, you already have everything !
- We collected the new user usages ate the assessment stage
- We extracted consumption and bill for current backend service on the mirror stage
- We filled a projected model pricing on managed service on the mirror stage
From this 3 different pieces of information, we can project the new user usages on the current backend services by identifying the impact of them in terms of compute capacity, storage and network to model the cost evolution on them. On the other hand, we can take these new technical information to projected once again on the managed service pricing models.
A little tip here, once again you came with some technical volumetries that you projected on model pricing with current data but also estimated. In time, you will maybe revise these data because the current data evolve or the hypothetical user usage changes do not occur as expected. Think about the evolution of these parameters and do not hesitate to build a sheet to automate the computation of the expected costs from fields with these data and fields with cloud provider SKU that impact the final cost ;)
Decision matrix and prioritization
In previous sections, we only talked about Cloud costs AFTER the migration. This is completely what we have to do to estimate final gain but this is not the only factor to estimate to decide if the migration or not!
There are several questions to ask to yourself to be able to take a global decision:
- Will we have data to transfer during the migration? What will be the cost of it?
- What is the development cost for your team to migrate? When can it be amortized with the Cloud cost gained? Is the time frame suitable for the project?
- Do you already have an Ops team that master your backend services and do not need to move Ops to the cloud provider with managed services?
Actually, keep in mind that the switch to managed services has to be suitable for the project, for the finance and for the development and ops teams. This is the whole to evaluate to only the bill cost in a decrease or increase approaches. Migrating to managed services and having a bill increase could be a good opportunity if on the other hand, you destress your Ops team with performance issues, you improve our customer satisfaction, you focus your teams on your business rather than techno-technical problems. At the end, the bill increase is to balance with product development velocity, capacity to onboard easely new clients, …
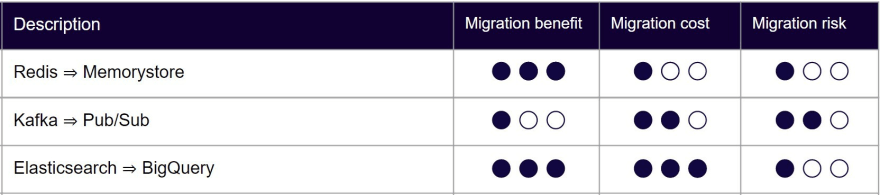
A good way to take a decision is to establish a decision matrix with the differents technicals choices offer to you to move to managed services with a same base of criterias:
- The estimated Ops cost
- The migration development cost
- The data migration cost
- The estimated risks in the migration (delay, managed service none compatible with your business case, lack of team skills, …)
- The estimated benefits of this migration (performance, deport Ops on cloud provider, cost, …)
These criterias can be very precise with quantitative data or less precise with qualitative data like indicators.
The matrix has to lead to decision to:
- keep going with a backend service if the costs and risks are too high regarding to benefits
- migrate as soon as possible on a managed service if the costs and risk are very low regarding to benefits
- delay in time the migration if the benefits worth it but costs and risks need to further studies, plan and mitigation
Conclusion
Managed services are a very good choice from scratch, you gain time in deployment, maintenance and you can focus on the business core of your company. However, when legacy is present in terms of technique but also people and skills, it is difficult to absolutely decide to move to managed service. The process to obtain or not this decision needs time, studies and skilled people to do it.
Even if at the end this is the good technical choice, maybe the business will cut it off because the customer projection is not good enough to amortize the migration cost. The work is not to put in the trash. First of all, trace it to capitalize on it for the team but also for you. Maybe in another business context, the choice of managed service will reappear and you will be able to reapply the methodology to this other case!
Even if you convince your teams and management to conduct this migration, the job is not over at the end of it. You need to adopt in a larger way FinOps activities to gain cost savings on other parts of your application. We propose here a how to start guide and we have open sourced a FinOps tool named Spendlr. Spendlr can use your billing export on GCP to notify users in Slack with customized notifications on Slack channels. Connectors can be added following your needs (AWS, Teams, …) thanks to the open source projects available here.


















