
This is the second episode of my Tricky Dataflow series, in which I present some of the trickiest issues I faced while implementing pipelines with Google Cloud Dataflow, and how I overcame them.
The last episode dealt with some BigQuery issues. This time, let's talk about a completely different flavour of database : MongoDB
MongoDB now is fairly widespread in the DB world, and arguably the most well-known NoSql database on the market. So, as one would expect, the Dataflow SDK has got a MongoDB connector ready to ease the usage of MongoDB as a datasource.
It offers the ability to read from and write to MongoDB collections, so I (the naïve me who was not so familiar with MongoDB at the time) thought it was all that was required to implement this simple kind of pipeline:
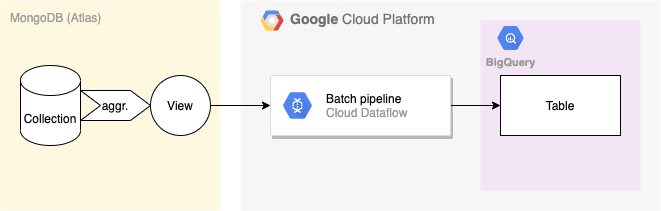
But of course - otherwise there would be not point writing a blog post - everything did not run as smoothly as I expected.
So you want to query a view, huh ?
In the first version of the pipeline, which I did as a warmup, I read documents directly from the collection with MongoDbIO.read().withUri(...).withDatabase(...).withCollection(...) and faced no real issue. There was one subtle point though, of which I did not realize the importance at the time:
Because the source MongoDB instance was hosted on Atlas, MongoDbIO was not allowed to run the default splitVector() command and therefore it was mandatory to add withBucketAuto(true) clause to download the collection.
I was not expecting the difficulties that came when I naïvely tried to use the view name in place of the collection :
[WARNING] org.apache.beam.sdk.Pipeline$PipelineExecutionException: com.mongodb.MongoCommandException: Command failed with error 166 (CommandNotSupportedOnView): 'Namespace [myview] is a view, not a collection' on server [***]
So apparently MongoDB knows about my view, understand I'd like to request this view but no, it won't let me retrieve documents from it. Actually it turns out there was no simple way to just get documents from the view. There surely is a good explanation for this, but I couldn't find it. So frustrating...

You know that feeling... (Photo Wikipedia / Nlan86)
Actually, a view in MongoDB is not as straightforward as a regular view in the SQL world : a MongoDB view is the result of collection documents processed by an aggregation pipeline. And MongoDbIO is able to perform aggregation queries on read collection thanks to AggregationQuery that may be passed to .withQueryFn(). The solution started to appear:
- read from the collection
- retrieve the aggregation definition from the view options
- pass the aggregation pipeline to
withQueryFn - MongoDB will process the document through the provided pipeline, which will result in the same documents as from the view
Let's follow the plan !
Retrieve the view's aggregation pipeline
To get the pipeline, we need to use mongo-java-client directly and get collection infos with it. It's pretty verbose:
static List<BsonDocument> retrieveViewPipeline(Options options) {
if (Strings.isNullOrEmpty(options.getView())) {
LOG.debug("No view in options");
return new ArrayList<>();
}
com.mongodb.MongoClientOptions.Builder optionsBuilder = new com.mongodb.MongoClientOptions.Builder();
optionsBuilder.maxConnectionIdleTime(60000);
MongoClient mongoClient = new MongoClient(new MongoClientURI("mongodb+srv://" + options.getMongoDBUri(),
optionsBuilder));
List<Document> viewPipeline = null;
for (Document collecInfosDoc : mongoClient.getDatabase(options.getDatabase()).listCollections()) {
if (collecInfosDoc.getString("name").equalsIgnoreCase(options.getView())) {
viewPipeline = collecInfosDoc.get("options", Document.class).getList("pipeline", Document.class);
break;
}
}
checkArgument(viewPipeline != null, String.format("%s view not found", options.getView()));
return viewPipeline.stream().map((doc) -> doc.toBsonDocument(BsonDocument.class,
MongoClient.getDefaultCodecRegistry())).collect(Collectors.toList());
}
Pass the pipeline to MongoDbIO
As mentioned, MongoDbIO has a method to handle aggregations : withQueryFn. However, this method actually has a little bug in the current version (2.27) when the pipeline has multiple steps:

Line 71: Harsh time for the last stage of the pipeline :( (screenshot from Github)
Of course, there is a simple workaround for this: just append a useless item to the pipeline list, which will be replaced by the bucket() stage:
if (viewPipeline.size() > 1) {
viewPipeline.add(new BsonDocument());
}
There you go, with the source connector configured like this, you can now retrieve the view documents:
PCollectionTuple mongoDocs =
pipeline.apply("Read from MongoDB",
MongoDbIO.read()
.withUri("mongodb+srv://" + options.getMongoDBUri())
.withDatabase(options.getDatabase())
.withCollection(options.getCollection())
.withBucketAuto(true)
.withQueryFn(
AggregationQuery.create()
.withMongoDbPipeline(viewPipeline))
)
But wait ! Does it work on HUGE collections ?
Finally ! You can now retrieve documents from your testing dataset, now you feel ready to test your shiny new pipeline on your real, huge, MongoDB view. And then...
com.mongodb.MongoCommandException:
Command failed with error 16819 (Location16819): ‘Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting. Aborting operation. Pass allowDiskUse:true to opt in.’
... it turns out you're not finished yet. At least the error message is pretty clear: when processing the aggregation pipeline on the MongoDB instance, the memory (RAM) limit has been exceeded. Sadly this limit is not configurable. The only work around is to allow MongoDB to use a swap file, which you can force by setting the parameter allowDiskUse: true alongside the aggregation pipeline.
This parameter is easily accessible through mongo-java-client thanks to AggregateIterable.allowDiskUse(). The problem is that, sadly, this method is not exposed in MongoDbIO yet. There is a feature request for it but it's not in a roadmap at the moment.
Unfortunately, allowDiskUse() is necessary in two places of the MongoDB Beam connector and it's not possible to override them:
-
MongoDbIO.buildAutoBuckets
AggregateIterable<Document> buckets = mongoCollection.aggregate(aggregates).allowDiskUse(true);
-
AggregationQuery.apply()
return collection.aggregate(mongoDbPipeline()).allowDiskUse(true).iterator();
So, the only way to edit these classes for now is to fork or duplicate them. Not perfect, but at least you can do some cleanup in your pipeline dependencies:
<!-- MongoDB connector -->
<!-- Because of limitations, a fork of this lib is used -->
<!--<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-mongodb</artifactId>
<version>${beam.version}</version>
</dependency>-->
<!-- The fork needs the Mongo-java driver -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.12.7</version>
</dependency>
All you need is mongo-java-driver
This long story has a happy end: thanks to allowDiskUse and the swap file, your custom MongoDbIO connector can now query MongoDb views of any size !
That's it for this second episode. Stay tuned for the next one, I'll talk present you GCP Workflows, a convenient way to orchestrate your Dataflow pipelines


















